灵衢协议深度分析
中国算力突围的互联赌注
草稿 v0.2 | 2026-05-30
一、为什么需要灵衢
AI 算力的竞争已经从"谁的芯片更强"转向"谁能把更多芯片粘在一起"。
原因很简单:单芯片算力增长放缓,但训练参数量每 18 个月翻一番。GPT-4 约 1.8 万亿参数,MoE(混合专家)架构下每次推理只激活一小部分参数。这意味着 All-to-All 通信的频率和带宽需求爆炸式增长。模型并行(TP)、专家并行(EP)、流水线并行(PP)三种并行策略的效率,都直接取决于互联带宽和时延。
2025 年 9 月,华为在昇腾开发者大会上发布 Atlas 950 SuperPoD,8192 张昇腾 NPU 无收敛全互联,单集群算力对标 NVIDIA DGX SuperPOD。支撑这套系统的不是 PCIe、不是 NVLink、也不是 RoCE,而是一个华为自研的统一互联协议:灵衢(UnifiedBus,简称 UB)。
在这个背景下,互联协议的格局是这样的:
- PCIe:通用 IO 总线,PCIe 5.0 x16 双向 128 GB/s,PCIe 6.0 翻倍到约 242 GB/s。但演进速度跟不上 GPU 算力增长,且协议栈本身有数百纳秒的开销。
- NVLink:NVIDIA 私有协议,第五代 1.8 TB/s 双向带宽,但只在 NVIDIA 自家芯片间工作,不对外开放。
- InfiniBand/RoCE:网络级互联,微秒级时延,适合跨节点通信,但无法满足节点内 GPU 间共享内存的纳秒级需求。
- CXL:基于 PCIe 物理层的缓存一致性协议,CXL 3.x 支持内存池化,但带宽受限于 PCIe 通道数,且生态成熟度不足。
对中国来说还有一个额外约束:制程受限,单芯片算力弱。昇腾 950PR 的单卡算力大约是 H100 的 60-70%,但 Atlas 950 SuperPoD 靠 8192 卡无收敛全互联,在整体系统吞吐上追平甚至超过了部分 NVIDIA 方案。这就是华为说的"用数学补物理,非摩尔补摩尔":用互联优势弥补单芯片短板。
灵衢就是这个战略的核心基础设施。
二、灵衢是什么
先把灵衢的定位说清楚,然后再谈它为什么这么设计。
灵衢是一个面向超节点(SuperNode)的统一互联协议,目标是替代 PCIe、NVLink、C2C、RoCE 等多种互联技术,用单一协议栈覆盖从芯片内到集群内的所有互联场景。
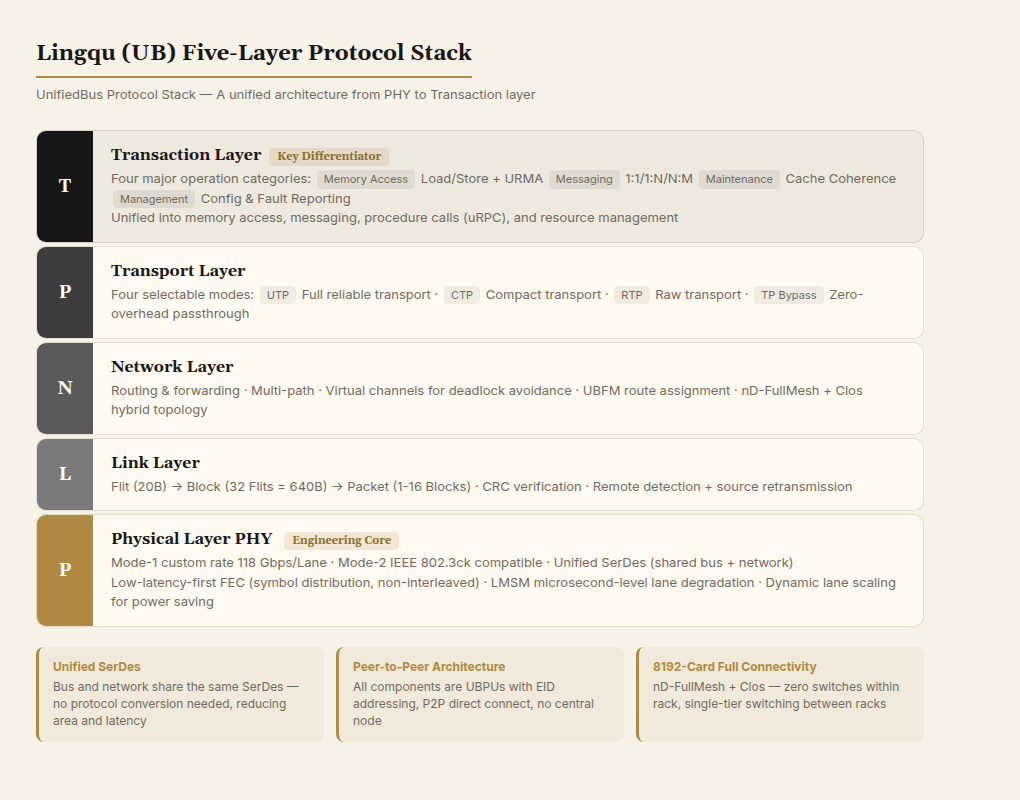
2.1 五层协议栈
灵衢的协议栈分为五层,每一层都有明确的职责,并且可以根据场景灵活组合:
物理层(PHY)
物理层提供两种模式:
- PHY Mode-1:自定义速率,当前 118 Gbps/Lane,优于同代 IEEE Ethernet 标准速率。基于 SerDes(串并转换器,高速信号的核心物理组件)DSP + FEC(前向纠错) + 线性直驱技术。
- PHY Mode-2:兼容以太网物理层,可以共享以太网的光模块和线缆生态。
物理层支持多种 FEC(前向纠错)模式,可以根据链路质量灵活选择。同时支持动态升降 Lane:如果某条 Lane 出故障,系统可以在不中断业务的情况下降速运行,配合 N+N 光模块备份实现硬件级冗余。
链路层(LINK)
基于 Flit(Flow Control Unit)传输机制。Flit 是链路层最小传输单元,32 个 Flit 组成一个 Block,1-16 个 Block 组成一个 Packet。链路层负责 CRC 校验和可选的链路层重传。当远端检测到丢包,会向源端发送重传请求,在链路层完成纠错,对上层透明。
网络层(NETWORK)
负责路由转发。灵衢网络层支持多路径路由,配合虚通道技术避免死锁。在一个超节点内,所有 UBPU(灵衢处理单元)都通过 UBFM(灵衢总线管理器)分配路由信息。
传输层(TRANSPORT)
传输层提供三种模式,按场景灵活选择:
- UTP(UB Transport Protocol):完整传输层,提供可靠传输保证。
- CTP(Compact Transport Protocol):精简传输层,减少开销。
- RTP(Raw Transport Protocol):裸传输层,最小化协议开销。
还有一种 TP Bypass 模式,可以在某些场景下完全跳过传输层,进一步降低时延。这种灵活性是灵衢的显著特点:不是所有通信都需要完整的传输层保障,对于低时延敏感的同步内存访问,Bypass 模式可以显著减少协议栈开销。
事务层(TRANSACTION)
事务层定义了四大类操作:
- 内存访问(Memory Accessing):UBPU 之间的内存读写,支持同步的 Load/Store 语义和异步的 URMA(Unified Remote Memory Access)语义。
- 消息传递(Message Passing):支持 1 对 1、1 对多、多对 1、多对多的消息传输。
- 维护操作(Maintain):更新远端 UBPU 内部状态,如缓存一致性维护、安全状态更新。
- 管理消息(Management):配置/运行过程中的状态上报,如地址配置和故障上报。
事务层的设计思路是把所有用户操作归一为内存访问、消息传递、过程调用(uRPC)、资源管理四类,提供直接利用硬件能力的高效编程方式。单一协议栈支撑所有操作,避免协议转换开销。
2.2 对等架构
这是灵衢与传统互联最本质的区别。
在传统架构中,CPU 是中心,GPU/NIC/SSD 都是"设备",挂在 PCIe 总线下,由 CPU 统一管理。GPU 之间的通信需要经过 CPU 中转,或者依赖 NVLink 这种私有高速通道。
灵衢把这个模型彻底翻了过来:所有组件都是 UBPU(灵衢处理单元),地位完全平等。
每个 UBPU 拥有:
- EID(Entity ID):全局唯一标识符,类似 IP 地址的角色。
- UMMU(UB Memory Management Unit):硬件级内存鉴权和地址翻译模块,把全局 UBA(UB Address)翻译为本地物理地址。
- UB Controller:协议栈的硬件实现,直接与计算单元的 NoC(片上网络)对接。
UBPU 之间可以直接发起 Load/Store 或 URMA 操作访问对方的内存,不需要经过任何中间节点。通信范围覆盖 H2H(CPU 到 CPU)、H2D(CPU 到 NPU)、D2D(NPU 到 NPU)、H2N(CPU 到 DPU)、H2S(CPU 到 SSU)等全组合,跨节点、跨机柜都一样。
UBFM(UB Fabric Manager)负责管理整个 Fabric 域内的 EID 分配、路由配置和资源管理,但它只做管理、不做数据转发,数据路径是完全去中心化的。
2.3 统一编程模型
灵衢提供两套编程接口:
- POSIX 接口:应用无感适配,原有 Linux 应用程序不需要修改。
- 高阶服务 API:通过 openEuler 的 UB Service Core 提供,包括池化内存管理(UBS Mem)、通信服务(UBS Comm)、IO 服务(UBS IO)、编译器与运行时(UBS Compiler & Runtime)、虚拟化(UBS Virt)、Serverless(UBS Serverless)等。
硬件层面,UB Controller 原生匹配计算单元乱序和并发执行的特征。计算单元可以直接用指令调度 UB Controller,不需要额外的驱动层介入。
2.4 全量池化
灵衢支持超节点内计算、存储和互联资源的全量池化:
- 计算资源池化:通过 UB Partition 实现多租户安全隔离,μs 级资源共享和迁移。
- 互联资源池化:所有 Entity 可使用所有可达路径和端口,通过多通道共享机制实现 TB/s 级带宽池化共享。
- 存储资源池化:远端 SSU(Storage Server Unit)通过 UB 直接暴露存储资源,通过 MMIO 和消息实现直接访问。
池化后的资源由 UBFM 统一管理,但数据路径仍然是去中心化的 P2P 直连。
2.5 大规模组网
灵衢支持从 64 卡到 8192 卡的线性扩展,拓扑设计采用 nD-FullMesh + Clos 混合策略:
- Rack 内:1D/2D-FullMesh 拓扑,电缆直连,零交换机,提供本地高带宽。
- Rack 间:一层交换的 Clos 拓扑,每个 Rack 内嵌 UB Switch,跨 Rack 通过 25.6T 交换机互联。
以 Atlas 950 为例:单 Rack 64 NPU + 4 CPU 板 + 1 备板,16 Lane × 64 Port 提供全互联。128 个 Rack 组成 8192 卡大超节点,Rack 间一层 Clos 交换。
灵衢还支持两种融合组网模式:
- UBoE(UB over Ethernet):UB 协议承载在以太网物理层上,与以太网交换机对接。IANA 已分配 UB 硬件类型(38)和专用端口(4792)。
- UB + OCS:与光路交换机配合,实现可变拓扑,匹配业务动态流量。
2.6 高可用性
灵衢的可靠性设计是分层的:
- 物理层:动态升降 Lane + N+N 光模块备份,单点故障下业务不中断。
- 链路层:远端重传机制,链路闪断和误码对上层透明。
- 传输层:端到端可靠传输(UTP 模式)。
- 管理面:UBFM 实时监控,故障自动隔离和路径重路由。
整体目标是 μs 级故障检测和恢复,应用无感知。

三、从 CUDA-NVLink 演进看灵衢的设计动机
理解了灵衢的架构之后,下一个问题是:为什么要"发明一套新协议"?答案在 NVLink 的演进史里。
3.1 NVLink 是怎么被 CUDA 逼出来的
理解灵衢为什么要"发明一套新协议",得先理解 NVLink 为什么存在。
2014 年之前,GPU 之间的通信只有一条路:PCIe。PCIe 是英特尔在 90 年代为通用 IO 设计的总线协议,它根本不是为 GPU 之间高频、大带宽、低时延的数据交换设计的。随着 CUDA 把 GPU 从图形加速器变成通用计算引擎,GPU 集群之间的通信量爆炸式增长,PCIe 的带宽瓶颈成了整个系统的天花板。
NVLink 的每一代演进,都是 CUDA 的编程模型在倒逼互联设计:
- NVLink 1.0(2016,P100):80 GB/s 双向带宽,是 PCIe 3.0 的 5 倍。解决了 GPUDirect P2P 的带宽问题,但只能连 4 个 GPU,拓扑是简单的网格。
- NVLink 2.0(2017,V100):150 GB/s,引入 NVSwitch 实现 16 GPU 全互联。CUDA Unified Memory 开始依赖 NVLink 做透明跨 GPU 内存访问。
- NVLink 3.0(2020,A100):600 GB/s,带宽大幅提升但拓扑不变。CUDA 的 Tensor Parallelism 开始要求 NVLink 提供可预测的低时延。
- NVLink 4.0(2022,H100):900 GB/s,NVL64 出现。CUDA 的 MoE 支持开始对 All-to-All 通信提出极高要求。
- NVLink 5.0(2024,Blackwell):1.8 TB/s,NVL72 机架级全互联。SHARP 引擎在网络内做归约加速。
- NVLink 6.0(2026,Rubin):3.6 TB/s,NVL72 保持 72 卡,但带宽翻倍。
注意一个关键趋势:NVLink 的规模上限没有随着带宽同步增长。从 NVL64 到 NVL72 只增加了 12.5%,而带宽从 900 GB/s 到 3.6 TB/s 增长了 4 倍。这不是 NVIDIA 不想做更大规模,而是NVLink 的 FullMesh 拓扑在大规模时遇到物理瓶颈:72 个 GPU 全互联需要 72×71/2=2556 条链路,交换芯片的端口数和布线复杂度已经接近工程极限。
NVIDIA 的解决办法是在 NVLink 之上叠加 NVSwitch 做交换式互联,但交换式互联引入了额外的跳数和时延。NVL72 用了一级 NVSwitch,更大的规模就需要二级甚至三级交换,时延和成本都会非线性上升。
3.2 CUDA 对互联的三个刚性需求
NVIDIA 十年来的互联演进,背后是 CUDA 编程模型对硬件的三个刚性需求:
需求一:全局内存可见性。CUDA Unified Memory 让开发者可以像访问本地内存一样访问任何 GPU 的内存。背后是 NVLink 提供的硬件级地址翻译和页迁移。这个能力让大模型的 Tensor Parallelism 成为可能--模型参数分布在不同 GPU 上,但计算核心用统一的地址空间访问它们。
需求二:纳秒级 All-to-All 时延。MoE 架构的每次推理都需要做专家路由(All-to-All 通信)。以 DeepSeek V4 为例,1.6 万亿参数的 MoE 模型,每次推理有 256 个专家需要从不同 GPU 上读取。如果 All-to-All 时延从 100 纳秒增加到 10 微秒,推理吞吐直接下降 50% 以上。
需求三:可预测的带宽隔离。训练和推理混合部署时,不同任务对带宽的需求差异极大。Tensor Parallelism 需要持续的大带宽 All-Reduce,而 MoE 推理需要高频的小消息 All-to-All。如果两者共享同一组链路,带宽竞争会导致时延抖动。
3.3 灵衢的设计动机:从 NVLink 的瓶颈出发
华为设计灵衢时,面对的核心约束和 NVIDIA 不同:
-
制程受限,单芯片算力弱:昇腾 950PR 的单卡算力大约是 H100 的 60-70%。要达到同等系统吞吐,需要把更多芯片粘在一起,互联规模必须比 NVLink 更大。
-
不能用 NVLink:出口管制切断了使用 NVLink 的可能,必须自研互联。
-
生态从零开始:没有 CUDA 这样的成熟编程模型可以依赖,互联协议必须自己把内存语义、编程模型、通信库都定义好。
这三个约束叠加,推导出灵衢的核心设计选择:
为什么是统一协议栈而不是分层拼凑?
NVLink 之所以可以"只做 GPU 间的高速通道",是因为它有 PCIe 在下面做 CPU-GPU 连接,有 InfiniBand 在上面做节点间通信。NVLink 只需要解决"GPU 和 GPU 怎么快速交换数据"这一个问题。
华为没有这种奢侈。它需要从零构建整个互联体系,如果走 PCIe + 自研高速链路 + RDMA 的分层路线,每层都需要单独开发和优化,工程量巨大且层间协议转换会引入不可控的时延。统一协议栈的代价是复杂度高,但好处是从物理层到事务层的时延和带宽可以精确控制。
为什么需要 8192 卡的全互联规模?
这不是盲目追求规模。原因在于:单卡算力弱意味着需要更多卡参与同一个训练任务。如果 NVLink 的 72 卡对应的是 8×H100 的算力,灵衢可能需要 200-300 张昇腾才能提供等效算力。8192 卡的互联规模意味着一个超节点内部可以容纳多个这样的训练任务,或者完成单个超大规模训练任务而无需跨超节点通信。
跨超节点通信(Scale-Out)的时延在微秒到毫秒级,比超节点内部的百纳秒级高出三个数量级。减少跨超节点通信的比例,是灵衢追求大规模互联的核心动机。
为什么选择 118 Gbps/Lane 而不是更高速率?
NVLink 6 的 224 Gbps/Lane 需要 4nm 以下工艺的 SerDes,且功耗极高。华为在 SerDes 领域的积累不如 NVIDIA(NVIDIA 可以借助台积电最先进工艺),选择 118 Gbps 是工程可行性权衡的结果。
但灵衢通过大规模 FullMesh 拓扑弥补单通道带宽的不足:8192 卡时,任意两个 UBPU 之间的可用路径远多于 NVLink 72 卡的拓扑。多路径传输可以聚合带宽,虽然单条链路慢,但总可用带宽可以很高。
这个设计的局限性:多路径传输意味着乱序到达,需要接收端做重排序缓冲。这会增加时延(重排序等待时间)和面积开销(缓冲区大小与路径数的平方成正比)。在 8192 卡的规模下,路径数可能达到数百条,重排序缓冲的开销不可忽视。
3.4 内存语义的设计取舍
灵衢同时提供 Load/Store(同步)和 URMA(异步)两种内存访问语义。这个设计需要理解它解决的问题。
Load/Store 的价值:让计算核心可以直接用指令访问远端内存,不需要通过操作系统或驱动。在 MoE 推理中,专家路由需要从远端 GPU 读取 64B-4KB 的小块数据。如果用传统的 RDMA(需要 PIN 注册内存、提交工作请求、轮询完成),一次访问需要 3-5 微秒。用 Load/Store 直接访问,可以把这个时延压到百纳秒级。
URMA 的价值:大块数据传输(如模型参数同步、All-Reduce)。URMA 类似 RDMA 但集成在协议栈内,不需要额外的网卡。这省掉了传统架构中"GPU → PCIe → CPU 内存 → RDMA NIC → 网络 → 远端 NIC → 远端 CPU 内存 → 远端 PCIe → 远端 GPU"的漫长路径。
实现的代价:
Load/Store 的同步语义要求 UMMU(灵衢内存管理单元)在硬件级维护全局地址映射。8192 个 UBPU 的地址空间意味着 UMMU 的页表可能非常大。如果每个 UBPU 有 64GB HBM,全局地址空间总量达到 512TB。UMMU 需要在纳秒级完成这个地址空间的查询和翻译,这要求极高的 TLB 命中率和精心设计的页表结构。
更棘手的问题是一致性。灵衢的规范没有明确说明是否支持缓存一致性(Cache Coherence)。如果不支持,Load/Store 访问的远端数据可能不是最新的--写操作可能还在远端的缓存中没有刷回主存。开发者需要手动做缓存刷新(类似 GPU 编程中的 __threadfence_system()),这显著增加了编程复杂度。
NVLink 从第四代开始在 GPU 之间支持硬件缓存一致性。这是一个 NVIDIA 花了两代产品才解决的问题。灵衢能否在不一致性的条件下靠软件保证正确性,或者在未来版本中实现硬件一致性,是一个关键的工程挑战。
3.5 灵衢 vs 现有分层体系:不是谁替代谁
用一张表看灵衢与现有互联协议的定位差异:
| 维度 | PCIe | NVLink | CXL | RDMA/RoCE | 灵衢 |
|---|---|---|---|---|---|
| 设计目标 | 通用 IO 总线 | GPU 间高速互联 | 缓存一致+内存池化 | 远程内存访问 | 统一全栈互联 |
| 时延 | 数百纳秒 | 百纳秒级 | 百纳秒级 | 微秒级 | 百纳秒~微秒 |
| 带宽/链路 | 64 GT/s (PCIe 6.0) | 224 Gbps (NVLink 6) | 64 GT/s (CXL 3.0) | 100-400 Gbps | 118 Gbps |
| 最大规模 | 1 设备/插槽 | 72 GPU (NVL72) | 数十设备 | 数千节点 | 8192 UBPU |
| 内存语义 | DMA | Load/Store + DMA | Load/Store + 一致性 | RDMA Read/Write | Load/Store + URMA |
| 缓存一致性 | 无 | GPU 间支持 | 原生支持 | 无 | 未明确 |
灵衢试图用一套协议覆盖 PCIe + NVLink + RDMA 三个层次的能力。好处是统一编程模型、消除协议转换。代价是每一层的性能都不如专用方案:Load/Store 不如 NVLink 快(118 vs 224 Gbps/Lane),RDMA 语义不如专用 RDMA NIC 成熟,缓存一致性还没有解决。
判断:灵衢的设计是"用统一性换极致性能"的工程权衡。对华为来说这是正确的选择,因为它的约束条件不允许走"每层用最优方案再拼起来"的路线。但如果一个厂商有 NVLink、PCIe 6.0 和成熟 RDMA 可用,灵衢的统一协议栈没有明显的性能优势。它的竞争力在于大规模组网(8192 卡)和全栈可控,而不在于单层性能。

四、国内超节点互联路线竞争
灵衢不是凭空出现的。它的设计选择只有在对比中才能看懂。先看国内,再看全球。
中国做 AI 超节点互联的不只灵衢一条路。按技术路线分,目前主要有四条:
4.1 灵衢路线:专用总线协议
代表:华为(昇腾 + 鲲鹏)
核心思路:自研统一协议,替代 PCIe/NVLink/RoCE 全栈,用系统级互联优势弥补单芯片短板。
优势:
- 协议栈设计完整,从物理层到应用层统一,没有协议转换开销
- 8192 卡无收敛全互联,大规模训练场景有明确的性能优势
- 软件栈开源(openEuler + openFuyao),降低适配门槛
劣势:
- 生态封闭,核心硬件 IP 全部来自华为
- 第三方芯片厂商集成 UB Controller 的意愿和能力待验证
- 与全球主流技术路线(PCIe/CXL/UALink)不兼容,存在技术孤岛风险
4.2 以太网优化路线
代表:阿里(EthLink/Eth-X)、百度(天池超节点)、字节、腾讯
核心思路:不发明新协议,在以太网上做深度优化:超以太网联盟(UEC)标准 + 定制交换机 + 算法协同调度。
百度是最新的重量级玩家。2026 年 6 月,基于昆仑芯 P800 的天池 256 卡超节点将正式上市,下半年推出 512 卡版本。天池超节点配备自研高带宽交换机,已完成 3 万卡集群的商业部署,适配 PD 分离推理架构。百度没有选择发明新的总线协议,而是在以太网基础上做 Scale-Up 优化,这和阿里 EthLink 的思路一脉相承。
优势:
- 复用以太网成熟的产业链(光模块、线缆、交换芯片),成本低
- 多厂商生态,不会被单一供应商锁定
- UEC 标准正在快速推进,2027 年有望大规模商用
- 百度天池超节点的落地进一步证明:以太网路线在国内不是纸面方案,已经有万卡级商业部署
劣势:
- 以太网本质上还是网络级互联,时延底线在微秒级,无法做到总线级的百纳秒
- 内存语义和一致性需要额外层(如 CXL over PCIe),协议栈仍然分层
- 对于 All-to-All 密集型 MoE 推理,时延可能成为瓶颈
4.3 OISA(开放互联标准架构)
代表:中国开放指令生态联盟
核心思路:推动开放互联标准,类似 UALink 的中国版。目标是建立跨厂商的互联协议标准。
现状:标准还在讨论阶段,离实际产品落地还有距离。
4.4 海光 HSL:从授权到开放
代表:海光信息
海光 HSL 的背景需要从 AMD Infinity Fabric 的技术授权说起。
Infinity Fabric 的技术基因
Infinity Fabric(IF)不是单一的互联协议,而是 AMD 花了近十年打造的一套统一系统互连架构。它的演进清晰地映射了 AMD 的产品策略:
- IF Gen1(2017,Zen/Naples):作为 CPU 内部互联出现,解决多 CCD(核心复合芯片)之间的通信问题。链路带宽约 40 GB/s,用于 CPU 内的 Data Fabric 和 Control Fabric 双轨架构。
- IF Gen2(2019,Zen 2/Rome):带宽提升到约 50 GB/s,开始支持跨插座(2P)的 CPU 间直连。AMD 用 IF 把多个 Chiplet 粘在一起的策略开始见效。
- IF Gen3(2021,MI250/EPYC Milan-X):关键升级。IF 第一次跨越 CPU 和 GPU,MI250 中两个 GPU Die 通过 IF Gen3 直连,共享内存地址空间。这为 MI300 的 CPU+GPU 融合架构奠定了基础。Frontier 超级计算机用 IF Gen3 实现了 CPU-GPU 的统一内存访问。
- IF Gen4(2023,MI300X/EPYC Genoa):AMD 用 IF 把 8 个 GPU Die + 2 个 CPU Die 封装在 MI300 中,形成"加速处理单元(APU)"。GPU 和 CPU 共享 HBM 内存,IF Gen4 提供约 400 GB/s 的 Die 间带宽。这是 AMD"统一内存架构"的核心。
- IF Gen5(2025,Helios/MI400):AMD 将 IF 演进为"Infinity Architecture",定位从芯片级互联升级为系统级互联。Helios 机架级平台用 IF Gen5 连接 EPYC Venice CPU、MI400 GPU 和 Pensando Vulcano NIC,形成统一的机架级系统。支持 UALink 和 Ultra Ethernet 两种对外接口,IF Gen5 作为内部互联"脊梁"。
IF 的设计哲学是分层演进、逐步扩展。从最初的 CPU 内部互联,到 CPU+GPU 封装内互联,再到系统级互联,每一代都在前一代基础上扩展功能范围,而不是推倒重来。这种渐进式演进的代价是协议栈的历史包袱较重,但好处是每一代都有经过大规模部署验证的基础。
海光 HSL 的技术渊源
2016 年,AMD 与天津海光签署技术授权协议,授权内容涵盖 Zen 架构 CPU 及部分 GPU/互联技术。海光在此基础上发展出 C86 系列 CPU 和深算系列 DCU。
海光 HSL(High-performance Scalable Link)的基因来自 IF 的授权版本,但做了两个关键改造:
-
国产化改造:增加了国密算法指令、安全处理器、漏洞防御机制。这些改动不是表面工作,而是在总线协议层嵌入了安全能力。HSL 宣称支持"全局地址空间一致性",意味着所有连接的芯片共享一个统一的内存地址空间,硬件级保证一致性。
-
开放化策略:2025 年 9 月,海光向产业界正式开放 HSL 1.0 规范。这不是简单的"文档公开",而是提供完整的 IP 参考设计和开放指令集,让国内其他芯片厂商可以直接集成 HSL 接口。壁仞、燧原、寒武纪等厂商不需要从头设计互联协议,只需要集成 HSL IP 就可以和海光的 CPU/DCU 形成异构系统。
HSL 的五大特性
根据海光公开信息,HSL 的核心特性:
- 高带宽:远超 PCIe 带宽(具体数值未公开,但声称支持万卡级异构互联)
- 低时延:总线级直连,不经过网络协议栈
- 全局地址空间一致性:所有连接芯片共享统一内存地址空间,硬件保证一致性
- 全栈开放:开放总线协议规范、IP 参考设计、指令集
- 灵活扩展:从单机多卡到大规模智算集群
海光的战略意图
海光开放 HSL 的目标不是和灵衢竞争"谁的协议更强",而是做一件灵衢做不到的事:成为国产芯片的统一互联标准。
灵衢的问题是:它由华为主导,华为既是供应商又是竞争对手。国内其他芯片厂商对灵衢的担忧不是技术问题,而是"我用了你的互联协议,会不会在下一个版本被你卡脖子"。
海光的定位不同。海光的 CPU 是 x86 架构,DCU 兼容 CUDA 生态,它不直接和壁仞、燧原等 GPU 厂商竞争核心算力市场。开放 HSL 等于是在说:"互联是我的贡献,算力是你们的事。" 这种角色更容易被其他厂商接受。
而且 HSL 已经有 IF 五代演进的工程基础。虽然海光没有公开 IF 授权的具体条款(是否限制 HSL 的演进方向),但 IF 的成熟度意味着 HSL 不需要从零开始解决互联的基本问题(缓存一致性、死锁避免、路由算法等),可以把工程资源集中在国产化适配和生态建设上。
HSL 的局限
-
带宽和速率未公开。海光没有公布 HSL 的具体带宽参数和 Lane 速率,这使得它很难和灵衢、NVLink、UALink 做定量对比。可能是技术限制(带宽不及竞品),也可能是商业策略(不暴露技术细节)。
-
IF 授权条款的约束。AMD 的授权协议通常有技术范围和使用限制。海光能否在 HSL 上做突破性的架构创新(比如类似灵衢的五层协议栈),还是只能在 IF 框架内做增量改进,取决于授权条款。这个信息不公开,外界无法判断。
-
生态建设刚起步。HSL 1.0 规范 2025 年 Q4 才发布,目前和生态伙伴的合作还处于早期阶段。从规范发布到产品落地通常需要 18-24 个月,这意味着 HSL 的实际影响要到 2027 年才能体现。
判断:HSL 是灵衢在国内市场最重要的竞争者,不是因为 HSL 技术更强,而是因为海光的"开放互联提供商"定位比华为的"全栈自研+协议公开"模式更容易被其他国产芯片厂商接受。如果 HSL 能在 2027 年前吸引足够的生态伙伴,它有机会成为国产芯片的事实互联标准,而灵衢可能退回到华为体系内部。
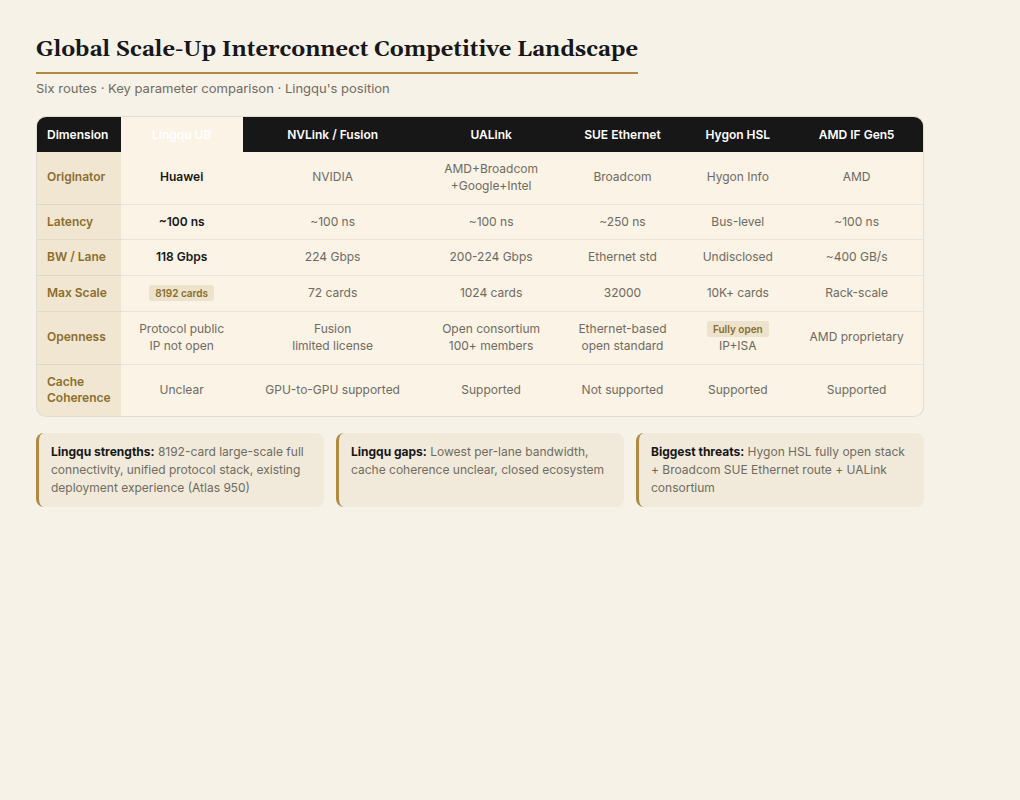
五、国际竞争格局
把视角拉远。灵衢不是中国特有的问题,全球都在解决同一个瓶颈:Scale-Up 互联。
六条主要路线如下:
| 维度 | 灵衢 (UB) | NVLink/NVLink Fusion | UALink | SUE (Scale-Up Ethernet) | 海光 HSL | AMD IF Gen5 |
|---|---|---|---|---|---|---|
| 发起方 | 华为 | NVIDIA | AMD+Broadcom+Google+Intel+Meta 等 | Broadcom | 海光信息 | AMD |
| 时延 | 百纳秒级 | 百纳秒级 | 百纳秒级 | 亚微秒级(~250ns) | 总线级(未公开具体值) | 百纳秒级 |
| 带宽/Lane | 118 Gbps | 224 Gbps (NVLink 6) | 200-224 Gbps | 以太标准速率 | 未公开 | ~400 GB/s Die间 |
| 最大规模 | 8192 卡 | 72 卡 (NVL72) | 1024 卡 | 32000 GPU | 万卡级 | 机架级(Helios) |
| 开放性 | 协议公开,硬件 IP 未开放 | Fusion 有限授权 | 开放联盟标准 | 基于以太网 | 全栈开放(IP+指令集) | AMD 私有 |
| 生态成熟度 | 低(华为体系) | 高(CUDA) | 中(100+成员) | 高(以太网) | 低(刚起步) | 中(AMD 体系) |
| 缓存一致性 | 未明确 | GPU 间支持 | 支持 | 不支持 | 支持(IF 基因) | 支持 |
几个关键观察:
-
灵衢在带宽/Lane 上落后于 NVLink 6 和 UALink(118 Gbps vs 224 Gbps),但灵衢的优势在于大规模全互联。NVLink 5 最多 72 卡,灵衢可以 8192 卡。
-
UALink 是灵衢在全球层面的直接竞争对手。两者都定位于"总线级统一互联",但 UALink 走的是开放联盟路线,背后有 AMD、Broadcom、Google、Intel 等重量级玩家。灵衢走的是"华为自研 + 协议公开"路线。更重要的是,UALink 继承了 IF 五代的缓存一致性和内存语义工程经验,这是灵衢目前尚未解决的短板。
-
海光 HSL 是灵衢在国内市场最重要的竞争对手。HSL 的技术来自 IF 授权,起步点高,而且海光选择了全栈开放策略(IP+指令集+参考设计),比灵衢的"协议公开但硬件 IP 不开放"更有吸引力。HSL 的劣势是生态刚起步,但海光的"开放互联提供商"定位比华为的"全栈自研"更容易被其他国产芯片厂商接受。
-
AMD IF Gen5(Helios)是一个值得关注的变量。AMD 用 IF Gen5 把 CPU、GPU、DPU 互联在同一个机架内,同时支持 UALink 和 Ultra Ethernet 对外扩展。这是 AMD 的"统一内部互联 + 开放外部接口"策略。如果 AMD 的 Helios 平台在 2026 年下半年成功交付,它将证明 UALink+以太网的双层架构可以提供足够的性能,对灵衢的"统一协议栈压平所有层次"构成直接挑战。
-
博通的 SUE(Scale-Up Ethernet)是一个被低估的变量。博通没有选择做专用总线协议,而是用以太网做 Scale-Up 互联。Tomahawk Ultra 提供 250ns 时延和 51.2Tbps 容量,配合精简报头和 CBFC 流控,在 MoE 推理场景已经接近总线级性能。这个路线的开放性和成本优势可能比 UALink 更有吸引力。
六、协议栈逐层拆解
前面几章解决了"灵衢是什么"和"为什么这么做"。这一章拆开看"具体怎么做到的"。重点放在物理层,因为这是灵衢工程能力最集中的地方,也是公开信息最少、最容易低估的部分。
6.1 物理层
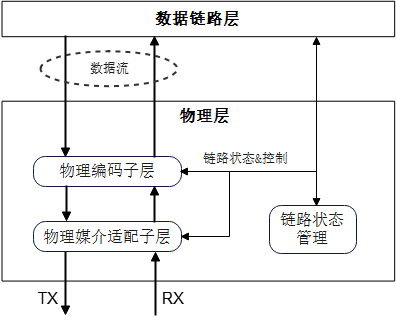
物理层是灵衢协议栈的基础,也是华为工程能力的集中体现。根据灵衢协议解码公开课的技术细节,物理层包含三个子模块:PCS(物理编码子层)、PMA(物理介质附加子层)和链路状态管理(LMSM)。
双模式设计:Mode-1 自定义 + Mode-2 兼容
灵衢物理层提供两种 PHY 模式,这是理解灵衢设计哲学的关键入口:
| 参数 | PHY Mode-1 | PHY Mode-2 |
|---|---|---|
| 数据速率 | 4.0 Gbps + 自定义速率 | 2.578 / 25.78 / 53.125 / 106.25 Gbps |
| 调制 | 4.0Gbps 用 NRZ,自定义速率可选 NRZ 或 PAM4 | 低速用 NRZ,53.125/106.25Gbps 用 PAM4 |
| 定位 | 自定义速率,不受固定标准速率约束 | 兼容 IEEE 802.3-2022 / 802.3ck-2022 |
Mode-1 的设计意图是充分利用 SerDes 和信道能力,不被以太网的固定速率等级(25G/50G/100G/200G/400G)约束。以太网的速率等级是为了兼容性而做的工程妥协:每一代速率必须和上一代平滑对接。灵衢不需要这个兼容包袱,所以 Mode-1 可以让 SerDes 跑到信道的物理极限。
Mode-2 则保证灵衢可以复用以太网成熟的物理层生态(线缆、连接器、光模块),降低部署成本。
数据路径:训练码流与数据码流
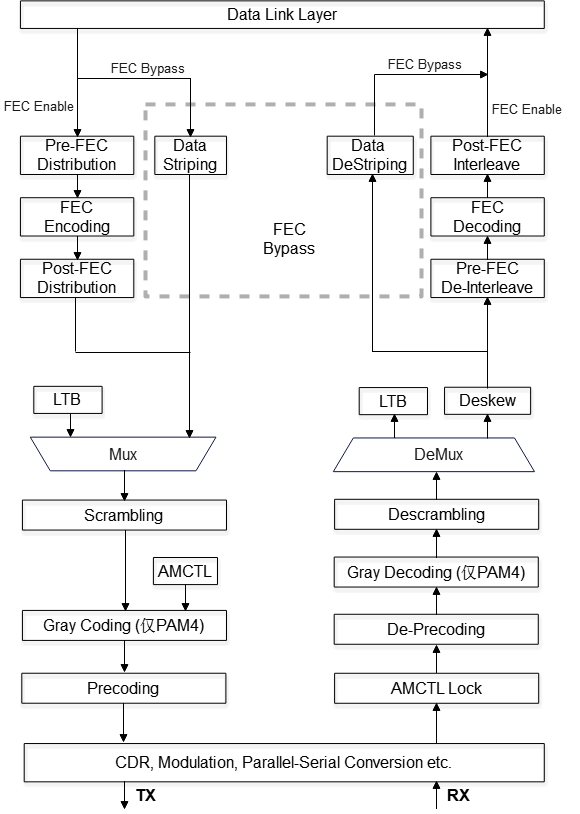
物理层的数据路径分为两条:
- 训练码流(链路训练状态):收发链路训练码(LTB),没有 FEC 编解码。这是链路从不可用到可用的初始化过程。
- 数据码流(链路可用状态):包含 FEC、扰码、预编码、格雷编码(PAM4 调制时)。低速或链路质量极好时可以 FEC Bypass,降低时延。
两条码流都周期性间插 AMCTL(管理控制字)进行帧定界和扩展控制功能。AMCTL 使用 eBCH-16 编码(BCH(15,5) + 1 bit 偶校验),可以纠正任意不超过 3 bits 错误及部分 4 bits 错误。AMCTL 不经过扰码,不在 FEC 保护范围内,默认插入间隔为 6656 个 symbol。
这个设计的精妙之处在于:AMCTL 作为物理层的"带内控制通道",即使在数据码流出错时也能保持链路管理能力。
FEC 设计:低时延优先
灵衢的 FEC 支持多种模式,核心参数:
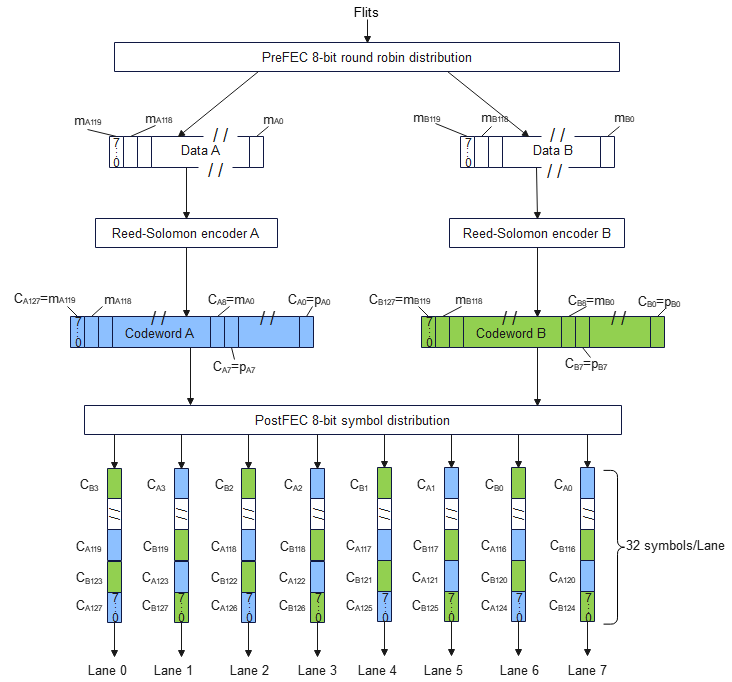
| FEC 模式 | N | K | T | 交织模式 |
|---|---|---|---|---|
| RS(128,120,T=2) | 128 | 120 | 2 | 1-way 或 2-way |
| RS(128,120,T=4) | 128 | 120 | 4 | - |
关键设计选择:灵衢的交织策略是"符号分发"而非传统交织。传统交织把多个码字的符号打散重新排列,纠错能力强但时延高。灵衢只做符号分发,不交织,保持低时延。少量不能纠正的错误交给链路层重传处理。
这个选择反映了灵衢的优先级:在 AI 训练和推理中,时延比极限可靠性更重要。 偶尔的重传(纳秒级)比持续的高 FEC 时延(百纳秒级)对吞吐的影响更小。
FEC 还支持动态切换:根据链路质量实时调整 FEC 模式。链路质量好时用轻量 FEC(T=2),质量差时用强 FEC(T=4),甚至可以 FEC Bypass。
LMSM:链路状态管理的工程深度
LMSM(Link Management State Machine)是灵衢物理层的核心竞争力之一。它负责链路训练和故障恢复,支持:
- 电链路和光链路
- 链路宽度协商和动态宽度切换
- 故障时强制快速降通道(微秒级,不进入 Retrain 状态)
- 固定速率模式和速率协商/切换模式(BER 过大时降速工作)
- FEC 模式协商和动态切换
- 全乱序(Lane Reorder)和 Lane 极性检测/翻转
- 均衡协商
动态升降 Lane 是一个值得单独分析的设计。
传统互联(如 PCIe)在 Lane 故障时需要重新训练整个链路,中断所有数据传输,耗时在毫秒级。灵衢的 LMSM 可以在微秒级完成降 Lane:不进入 Retrain 状态,只停用故障 Lane,其他 Lane 继续传输。配合链路层重传,故障情况下不丢包。
更进一步的"动态链路宽度切换"允许在业务运行中根据流量需求升降 Lane:流量小时降 Lane 省功耗,流量大时升 Lane 满足带宽。这意味着灵衢的物理层不是静态配置的,而是可以根据运行状态自适应调整的。
SerDes 归一化:灵衢的统一架构基础
灵衢的一个容易被忽视但极其重要的设计:所有类型的流量(总线、网络)共享同一套 SerDes。
传统架构中,PCIe SerDes 和以太网 SerDes 是分离的。一个 XPU 如果既要做总线互联又要做网络互联,需要两组独立的 SerDes 和控制器。节点间互联还需要在这两种 SerDes 之间做转换,增加面积和时延。
灵衢通过 UB 统一 SerDes,同一个 SerDes 可用于所有类型流量,免转换。这直接降低了芯片面积(不需要双份 SerDes)和物理时延(不需要协议转换)。
Lane 速率定位
灵衢的 118 Gbps/Lane(Mode-1)介于以太网 106.25 Gbps(Mode-2 / 802.3ck)和 NVLink/UALink 的 224 Gbps 之间。这个速率选择是工程权衡:
- 比以太网快 11%,在总线级互联中有带宽优势
- 不追求 NVLink 的 224 Gbps,降低了 SerDes 设计难度和功耗
- 结合大规模全互联(8192 卡),用并行 Lane 数量弥补单 Lane 带宽差距
但需要诚实地说:单 Lane 带宽的差距意味着灵衢在同等互联域规模下需要更多的 Lane 数,这增加了引脚占用和线缆复杂度。在芯片面积和功耗受限的封装内(如 Chiplet),Lane 数量是硬约束。
6.2 链路层
链路层基于 Flit 传输:
- Flit:最小传输单元,20 Byte
- Block:32 个 Flit(640 Byte)
- Packet:1-16 个 Block(640 Byte - 10 KB)
链路层提供 CRC 校验和可选的链路层重传。重传机制是"远端检测、源端重传"。接收端发现丢包后向发送端请求重传,而不是发送端盲目重传。这种方式更高效,但需要接收端维护额外的重排序缓冲区。
6.3 网络层和传输层
网络层负责路由转发,支持多路径和虚通道以避免死锁。
传输层的设计是灵衢的一个亮点:三种模式按需选择。
| 模式 | 开销 | 可靠性 | 适用场景 |
|---|---|---|---|
| UTP | 最高 | 完整可靠传输 | 需要严格保证的数据传输 |
| CTP | 中等 | 精简可靠传输 | 平衡性能和可靠性 |
| RTP | 最低 | 无传输层保障 | 时延敏感、可容忍少量丢包 |
| TP Bypass | 零 | 无传输层 | 最极端时延要求的同步内存访问 |
对比 NVLink 和 PCIe:
- NVLink 没有传输层概念,硬件直接保证可靠性。
- PCIe 有完整的传输层(Transaction Layer + Data Link Layer),但无法 Bypass。
- 灵衢的灵活性在这里体现:对于 MoE 推理中频繁的 All-to-All 小消息通信,Bypass 模式可以显著降低时延;对于模型参数的大块传输,UTP 模式提供可靠保障。
6.4 编程模型
灵衢提供两种内存访问语义:
同步语义:Load/Store
- 计算单元直接发起 L/S 指令,通过 UB Controller 访问远端内存
- 时延:百纳秒级
- 适用于细粒度、频繁的内存访问(如梯度同步、参数更新)
异步语义:URMA(Unified Remote Memory Access)
- 类似 RDMA,但集成在 UB 协议栈内,不需要额外的 RDMA NIC
- 支持 64B - 4KB 变长单事务操作
- 适用于大块数据传输(如 All-Reduce、Broadcast)
两种语义共享同一个多端口带宽池,通过多路径传输充分利用物理带宽。
七、第三方支持灵衢需要改什么
技术分析到这里,一个自然的问题是:假设灵衢协议完全开放,一个 GPU 厂商或整机厂商想要支持 UB,改动有多大?
答案是:涉及从芯片到软件的全栈。这一章可以当清单看,不需要细读每一项,但要感受一下工程量。
7.1 芯片层面
GPU/NPU 芯片
这是改动最大的部分。当前 GPU/NPU 芯片的 IO 接口主要是 PCIe Controller(连接 CPU)和私有高速互联接口(如 NVLink、Infinity Fabric)。要支持灵衢,需要:
-
集成 UB Controller IP:UB Controller 是灵衢协议栈的硬件实现,包括物理层(PHY + SerDes)、链路层、网络层、传输层和事务层的硬件逻辑。这不是一个简单的 PCIe Controller 替换。UB 协议栈比 PCIe 复杂得多,支持同步/异步内存语义、多路径路由、链路层重传等特性。
-
集成 UMMU 模块:UMMU(UB Memory Management Unit)负责全局地址翻译和访问鉴权。每个 UBPU 都需要 UMMU 来把远端的 UBA(UB Address)翻译为本地物理地址,同时做权限检查。UMMU 的设计思路类似 IOMMU,但需要支持 UB 特有的 EID + Token 鉴权模型。
-
分配 EID 和路由表:每个 UBPU 需要一个全局唯一的 EID,以及由 UBFM 下发的路由表。这需要芯片上有专门的配置寄存器和与 UBFM 通信的管理接口。
-
NoC 集成:UB Controller 需要与芯片内部的 NoC(片上网络)对接。计算单元(AI Core、Tensor Core 等)通过 NoC 访问 UB Controller,发起 Load/Store 或 URMA 操作。NoC 的设计需要考虑 UB 的多端口、多路径特性。
-
SerDes/PHY IP:如果采用 PHY Mode-1(118 Gbps/Lane),需要支持灵衢特定频点的 SerDes IP。好消息是,已有第三方 IP 厂商在做 UB PHY 兼容。牛芯半导体已公开宣布完成了 UB PHY IP 的兼容验证,芯原股份提供 Chiplet 集成服务。这意味着第三方芯片厂商不一定需要自研 SerDes。
CPU 芯片
CPU 的改动比 GPU 更复杂,因为 CPU 需要在内核态管理 UB 的页表和地址空间:
-
I/O Die 集成 UB 协议栈:华为自己的鲲鹏处理器已经在 I/O Die 中集成了 UB Controller。第三方 CPU 厂商需要做同样的集成。
-
内核页表管理改造:Linux 内核需要支持 UB 的 UBA 地址空间,把远端内存映射到进程的虚拟地址空间。这需要修改内核的页表管理、内存管理子系统。
-
URMA 异步接口:CPU 需要支持 URMA 异步操作,这可能需要新增指令或微架构改动。
DPU/网卡
传统 RDMA NIC 的角色会被 UB Controller 替代。因为 UB 原生支持 URMA 异步内存访问,不需要额外的 RDMA 协议栈。但 DPU 仍然有存在价值:卸载安全、压缩、存储等高级功能。
7.2 板卡与主板层面
主板布线
当前主板的标准 IO 接口是 PCIe Slot。支持 UB 后需要:
- UB Port 替代或并存 PCIe Slot:每个 UB Port 需要多 Lane 的 SerDes 通道,布线密度和信号完整性要求远高于 PCIe。一块承载 64 NPU 的主板需要数百条高速差分对,PCB 层数可能从当前的 16-20 层增加到 24-32 层。
- 光电混合布线:Rack 内用电缆直连(短距),Rack 间用光模块(长距)。主板需要同时预留电信号通道和光模块接口位置。OBO(On-Board Optics)方案把光模块直接焊在主板上,缩短电信号路径,但增加了组装和返修难度。
- 供电和散热:UB Controller 本身的功耗不可忽视。每个 UB Controller 需要独立供电,加上高密 SerDes 的功耗,主板的供电设计需要重新规划。散热方面,UB Port 区域的局部热密度可能比 GPU 区域还高。
机柜设计
Atlas 950 的机柜是围绕 UB 设计的,不是传统 GPU 服务器的拼装:
- 单 Rack 64 NPU + 4 CPU + 1 备板,机柜内部用 FullMesh 电缆直连,不需要交换机。
- 16 个 Rack 组成 8192 卡超节点,Rack 间通过一层 UB Switch 互联。
- 液冷是标配,高密布线加上高功耗芯片,风冷方案基本不可行。
7.3 系统设计层面
从"CPU 中心"到"对等网络"
传统服务器的系统设计以 CPU 为中心:CPU 管理 PCIe 总线,控制内存分配,协调所有外设。GPU 之间如果想通信,要么经过 CPU(通过系统内存中转),要么走私有通道(NVLink),两条路都有局限。
灵衢架构把系统设计逻辑推倒重来:所有组件都是 UBPU,地位平等,通过 EID 寻址,直接 P2P 通信。CPU 不再是交通枢纽,而是和 NPU、DPU 一样的网络节点。
这意味着:
-
内存模型变了。传统架构下,每台服务器有自己的本地内存,跨节点访问需要 RDMA。灵衢架构下,所有 UBPU 的内存组成一个全局地址空间(UBA),任何 UBPU 可以通过 Load/Store 直接访问远端内存,就像访问本地内存一样。UMMU 硬件模块负责地址翻译和权限检查,对应用透明。
-
启动和发现机制变了。传统服务器的启动流程是 BIOS → 引导 → OS。灵衢超节点的启动流程需要 UBFM 先发现所有 UBPU、分配 EID、配置路由表,然后各个节点才能开始工作。这是一个分布式系统的启动问题,复杂度远高于单机。
-
容错模型变了。传统集群靠上层软件(如 checkpoint-restart)处理节点故障。灵衢在硬件和协议层提供分级容错:物理层动态降 Lane、链路层重传、网络层重路由。目标是单个 UBPU 或单条链路故障时,整个超节点在微秒级恢复,上层应用无感知。这个目标很激进,实际做到什么程度需要大规模部署验证。
-
资源调度变了。传统集群调度器分配的是"机器"(CPU+GPU+内存的组合)。灵衢超节点的调度单位可以更细:UB Partition 支持在硬件层面把 NPU、内存、带宽切分给不同租户,微秒级动态调整。这为多租户共享超节点提供了硬件级隔离。
7.4 软件层面
软件适配是灵衢落地的另一个大工程。
操作系统
openEuler 已经集成了 UB Service Core,提供灵衢的完整软件栈。但第三方操作系统(Ubuntu、CentOS、Debian 等)需要自行适配。主要改动:
- 内核内存管理:支持 UBA 地址空间,把远端内存映射到进程的虚拟地址空间。这不是简单的 mmap。UMMU 需要和内核的页表管理协同工作,处理缺页中断、TLB 一致性等问题。
- 设备驱动模型:传统 Linux 的设备模型基于 PCIe 总线(device/driver/bus 三层)。UBPU 不是 PCIe 设备,需要新的驱动框架。openEuler 的实现是把 UBPU 抽象为一种新的总线类型。
- NUMA 扩展:传统 NUMA 拓扑描述的是 CPU 和内存的亲和性。灵衢架构下,NPU、DPU、SSU 都是 NUMA 节点,拓扑描述和调度策略都需要扩展。
通信库和框架
华为开源了 openFuyao 通信库(类似 NCCL 的角色),支持灵衢的原生语义。但主流 AI 框架(PyTorch、JAX、DeepSpeed)的底层通信都基于 NCCL 或 Gloo,适配灵衢意味着要么重写通信后端,要么在 openFuyao 上做一个 NCCL 兼容层。
兼容层的可行性和性能损耗是关键问题。华为已经做了部分工作:openFuyao 提供了类 NCCL 的 API 接口,降低了迁移门槛。但 All-to-All、All-Reduce 等集体通信操作的性能高度依赖底层硬件拓扑,灵衢的 FullMesh 拓扑和传统 Clos 拓扑差异很大,通信算法需要重新调优。
编译器
灵衢的 URMA 异步语义和 Load/Store 同步语义需要编译器感知。具体来说:
- 编译器需要知道哪些数据在本地、哪些在远端,据此选择同步还是异步语义。
- 对于分布式训练中的梯度同步,编译器需要生成 URMA 操作而非传统的 MPI 调用。
- 华为在毕昇编译器中做了这部分工作,但第三方编译器(LLVM、GCC)的适配还没有公开进展。
判断:软件适配的工作量不小,但比硬件适配更容易推进。原因是软件适配可以分阶段,先做 NCCL 兼容层让主流框架跑起来,再逐步优化到灵衢原生语义。硬件适配没有这种"先跑起来"的中间态。
八、NVLink Fusion:NVIDIA 的防御性转身
从这章开始,分析视角从"灵衢是什么"切换到"灵衢面对什么"。
8.1 NVIDIA 为什么要"开放"NVLink
2025 年 6 月,NVIDIA 发布了 NVLink Fusion。要理解这个动作,需要先理解 NVIDIA 为什么能靠 NVLink 铁矿独占 AI 算力市场这么久。
NVLink 不是孤立存在的技术。它和 CUDA、NVSwitch、SHARP 引擎、NCCL 通信库构成了一个紧密耦合的体系:
- CUDA 的 Unified Memory 依赖 NVLink 做透明跨 GPU 内存访问
- Tensor Parallelism 依赖 NVLink 的低时延 All-to-All
- NCCL 的 All-Reduce 实现依赖 NVSwitch 的 SHARP 引擎做网内归约
- CUDA 的编程模型假设所有 GPU 在一个统一的地址空间里
这套体系让 NVIDIA 的客户一旦用上 CUDA,就很难离开 NVLink 生态。NVLink 的封闭性不是副作用,而是设计目标。
NVLink Fusion 打破了这个封闭性的一部分,但只是一小部分。核心内容:允许第三方芯片(CPU、DPU、定制加速器)集成 NVLink 接口,参与 NVLink 互联域。
8.2 NVLink Fusion 的设计约束
NVLink Fusion 的"开放"是精心限定边界的:
限制一:GPU 不开放。 第三方芯片只能做 NVLink Domain 中的"叶子节点",不能做 GPU。你不能用 NVLink Fusion 把自己的 AI 加速器接入 NVIDIA 的 GPU 集群,只能接入 CPU 或 DPU。AI 加速器之间的互联仍然只走 NVLink,而 NVLink 只在 NVIDIA GPU 之间工作。
这个限制的逻辑很清楚:NVLink 是 NVIDIA GPU 市场份额的护城河。开放 GPU 间互联等于把护城河填了。但开放 CPU/DPU 接入可以扩大 NVLink 的互联域范围,让 NVIDIA 的机架级方案(NVL72)更完整。
限制二:需要 IP 授权。 NVLink Controller IP 需要从 NVIDIA 获取授权,条款、定价和限制都由 NVIDIA 决定。这不是一个开放标准,而是一个许可模式。拿到授权意味着你的芯片设计流程中有一部分必须经过 NVIDIA 的审核和配合。
限制三:规模上限不变。 NVLink 5 的互联域上限是 72 个 GPU(NVL72)。NVLink Fusion 增加了 CPU 和 DPU 节点,但 GPU 数量上限不变。NVIDIA 的架构路线图显示,Rubin Ultra NVL576 可能把这个上限推到 576,但那仍然是 NVLink 6 的内部演进,不是 Fusion 带来的。
8.3 NVLink Fusion 的前瞻性分析
从技术前瞻的角度,NVLink Fusion 暴露了 NVIDIA 面对的一个结构性问题:单芯片算力增长放缓,互联域需要扩大,但 NVLink 的 FullMesh 拓扑在大规模时工程成本急剧上升。
NVIDIA 的解法是在 NVLink 之上叠加 NVSwitch 做交换式互联。NVL72 用了一级 NVSwitch,NVL576 可能用两级。交换式互联的好处是可扩展,坏处是每增加一级交换,时延增加 100-200 纳秒。在 MoE 推理这种对时延极度敏感的场景,多一级交换就意味着显著的吞吐损失。
NVLink Fusion 的真正价值可能不在于"开放",而在于让 NVIDIA 的客户可以在 NVLink 互联域内混用自有芯片。AWS 的 Trainium4 就是第一个公开的案例--AWS 可以把自研的 Trainium 芯片和 NVIDIA GPU 放在同一个 NVLink 互联域内。这意味着云厂商可以构建"NVIDIA GPU + 自研加速器"的混合集群,而不用完全依赖 NVIDIA。
对灵衢的含义:NVLink Fusion 证明了"专用互联协议对外开放"是行业趋势。灵衢走的是同一条路,但更激进。NVLink Fusion 的限制(GPU 不开放)意味着真正想做自有 AI 加速器的厂商仍然需要 NVLink 以外的方案。灵衢和 UALink 都是候选。
九、UALink 与 SUE:两条开放路线的设计哲学
灵衢在国际上面对的不只是 NVIDIA,还有两条设计哲学完全不同的开放互联路线。
9.1 UALink:从 Infinity Fabric 到开放标准
2025 年 4 月,UALink 联盟发布 1.0 规范。2026 年 4 月,2.0 规范发布,新增在网计算、Chiplet 规范和管理性规范。
UALink 的技术基因:IF 五代积累的工程经验
理解 UALink 为什么能快速推出 1.0 和 2.0 规范,需要看到它背后的技术积累。AMD 的 Infinity Fabric 已经经历了五代演进(见第四章),从 CPU 内部互联一直做到 CPU+GPU+DPU 的系统级互联。UALink 的核心设计团队来自 AMD,协议的很多关键设计直接继承了 IF 的工程经验:
- Load/Store 内存语义:IF Gen3 在 MI250 中就已经实现了 GPU 间的 Load/Store 直连。UALink 把这个能力标准化,让任何厂商的加速器都能用统一的语义访问远端内存。
- 缓存一致性:IF Gen4 在 MI300 中实现了 CPU 和 GPU 共享内存的缓存一致性。UALink 的共享内存模型直接基于这个经验。灵衢目前没有明确的缓存一致性支持,这是 UALink 的一个结构性优势。
- Chiplet 集成:IF 从 Gen1 就在解决 Chiplet 间的通信问题。UALink 2.0 的 Chiplet 规范支持 UCIe 3.0,让芯片厂商可以在 Chiplet 层面集成 UALink 接口,这直接来自 AMD 的 Chiplet 实战经验。
但 UALink 不是 IF 的开放版本。 IF 是 AMD 的私有协议,UALink 是联盟标准。两者之间的关系类似 ARM 的 AMBA 和 UALink:前者是厂商私有,后者是开放标准,但设计基因有明显的传承。
UALink 的设计出发点
UALink 核心问题是:能不能用开放标准提供 NVLink 级别的互联能力?
NVLink 的核心能力有三个:
- 总线级低时延(百纳秒)
- Load/Store 内存语义(GPU 可以直接读写远端内存)
- 全互联拓扑(机架内所有 GPU 之间无阻塞通信)
UALink 1.0 的设计针对这三个能力逐一回应:
- 时延:UALink Switch 的时延目标随端口数变化,128 lane 时小于 200ns,512 lane 时小于 300ns。这个时延范围与 NVSwitch 处于同一量级。
- 内存语义:UALink 专门强调自己是"唯一针对 Scale-Up AI 的内存语义解决方案"。它支持 Read、Write 和 Atomic 三种事务,跨加速器直接内存访问。协议效率声称达到 94%+。
- 规模:1.0 支持 1024 个加速器。2.0 的 Chiplet 规范支持 UCIe 3.0 集成,意味着可以在 Chiplet 层面把 UALink 接口集成到 SoC 内。
UALink 2.0 的前瞻性
2.0 规范加入了几个关键能力:
- 在网计算(In-Network Compute):在交换机内执行集合通信操作(如 All-Reduce),类似 NVIDIA 的 SHARP。这降低了端点的 CPU 开销和网络带宽消耗。
- 链路弹性(Link Resiliency):链路故障时自动降速或重路由,不需要人工干预。这是大规模部署的刚需。
- 链路折叠(Link Folding):多条低速链路聚合为一条逻辑高速链路。这让系统可以在不同速率的物理层之间灵活组合。
- 可管理性规范:引入集中式管控架构,使用 gNMI、YANG、SAI、Redfish 等标准协议。这意味着 UALink 网络可以被现有的网络管理工具直接管理。
- 安全模块(UALinkSec):硬件级加密和认证,支持 AMD SEV、Arm CCA、Intel TDX 等可信执行环境。这对云厂商多租户场景很关键。
UALink vs 灵衢:设计哲学的差异
两者定位几乎重合,但设计哲学不同:
| 维度 | UALink | 灵衢 |
|---|---|---|
| 基因 | Infinity Fabric 演进 | 全新自研 |
| 物理层 | 基于以太网物理层(200GBASE-KR1/CR1) | 自定义 PHY Mode-1 + 兼容以太网 PHY Mode-2 |
| Lane 速率 | 200-224 Gbps | 118 Gbps |
| 最大规模 | 1024 加速器(1.0),可扩展 | 8192 UBPU |
| 开放性 | 联盟标准,100+ 成员 | 华为自研,协议公开,硬件 IP 未开放 |
| 在网计算 | 2.0 支持 | 无公开信息 |
| Chiplet 集成 | UCIe 3.0 兼容 | 无公开信息 |
UALink 的优势在于 Lane 速率(200 Gbps vs 118 Gbps)和生态起点(100+ 联盟成员 vs 华为一家)。灵衢的优势在于组网规模(8192 vs 1024)和实际部署经验(Atlas 950 已量产)。
但 UALink 有一个灵衢没有的结构性优势:它的物理层基于以太网。 这意味着 UALink 可以复用以太网成熟的 SerDes IP、光模块和线缆生态。芯片厂商不需要为 UALink 定制新的 PHY IP,只需在以太网物理层之上实现 UALink 协议栈。这大幅降低了第三方适配的门槛。
UALink 的风险:联盟内部利益不一致。AMD 想推 Infinity Fabric 演进路线,Broadcom 想卖交换芯片,Google 和 Meta 想降低对 NVIDIA 的依赖,Intel 想确保自家加速器不被边缘化。UALink 2.0 一次发布四项规范,推进速度不慢,但"敌人的敌人是朋友"的联盟能否持续高效协作,是最大的不确定性。
9.2 博通 SUE:用以太网吃掉 Scale-Up
博通没有选择做新协议,而是用以太网做 Scale-Up 互联。这个路线的设计哲学是:不追求极致性能,用生态成熟度和成本优势覆盖 80% 的场景。
Tomahawk Ultra 的设计思路
2025 年 7 月,博通发布 Tomahawk Ultra,这是一款专门为 Scale-Up Ethernet 设计的 51.2Tbps 交换芯片。它不是简单的以太网交换机,而是针对 AI 工作负载做了深度定制:
- 64 字节小包全线速:传统以太网交换机追求大包吞吐,小包性能严重下降。Tomahawk Ultra 在 64 字节小包场景下也能跑满 51.2Tbps,时延控制在 250 纳秒以内。这对 MoE 推理中高频的小消息 All-to-All 通信至关重要。
- 精简报头:将以太网报文头部从 46 字节精简到 10 字节,大幅提升小包的有效载荷比率。
- 链路层无损传输(LLR)+ FEC:在链路层就完成错误恢复,避免上层重传。配合基于信用的流控(CBFC),构建接近无损的交换网络。
- 网内集合计算(INC):在交换层对 All-Reduce 等集合操作做网内归约,类似 NVIDIA 的 SHARP。
这些优化让以太网在 Scale-Up 场景的时延从传统的微秒级下降到亚微秒级。虽然还是比 NVLink/UALink 的百纳秒级慢 3-5 倍,但对于很多场景已经"够用"。
Tomahawk 6 的前瞻性
2025 年 6 月量产的 Tomahawk 6 更激进:单芯片 102.4Tbps 交换容量,512 个 200G SerDes 通道,3nm+Chiplet 制程。它同时支持 Scale-Up 和 Scale-Out,意味着一个芯片可以同时处理机架内和跨机架的通信。
Tomahawk 6 的关键设计选择:
- 统一 Scale-Up/Scale-Out:不再需要为机架内和跨机架通信准备两种不同的交换芯片。一个芯片两种用途,降低系统复杂度和成本。
- 原生 CPO(共封装光学):光引擎和交换 ASIC 封装在同一基板上,信号传输路径缩短到 2 厘米以内。这大幅降低了功耗和时延,是 AI 集群大规模部署的关键技术。
- 100 万+ XPU 集群支持:自适应路由算法和大规模拓扑支持,面向未来百万级加速器集群。
SUE 对灵衢的含义
回顾 InfiniBand vs 以太网的历史:InfiniBand 在时延和带宽上都优于以太网,但以太网凭借成本和生态优势,把 InfiniBand 挤到了 HPC 小众市场。
同样的故事可能在 Scale-Up 互联领域重演。如果以太网能做到"80% 的性能、50% 的成本、10 倍的生态成熟度",大多数厂商会选择以太网。Tomahawk Ultra 的 250 纳秒时延虽然比灵衢的百纳秒慢,但对于大多数训练任务来说差距不大。真正拉开差距的是 MoE 推理中高频的小消息 All-to-All,而博通正在用精简报头和 CBFC 等手段缩小这个差距。
灵衢的真正竞争者可能不是 UALink,而是 SUE。 UALink 联盟执行力存疑,但博通是一家执行力极强的公司,且以太网生态已经运转了几十年。如果博通在 2027-2028 年把以太网 Scale-Up 做到实用水平,灵衢的时间窗口会急遽收窄。
十、生态落地:谁会用灵衢
技术和竞争分析都说完了。最后一个问题,也是最实际的问题:除了华为自己,谁会用它?
华为体系内的确定性
灵衢在华为体系内的落地是确定的:
- 昇腾 + 鲲鹏:已集成 UB Controller,从芯片到系统到软件全栈打通。
- Atlas 产品线:Atlas 300(推理卡)、Atlas 500(边缘)、Atlas 800(训练服务器)、Atlas 900/950(超节点)都已支持或规划支持灵衢。
- 华为云:ModelArts 平台的训练集群底层已经用灵衢互联。
- openEuler + openFuyao:软件栈开源,降低客户适配门槛。
这个基本盘不小。华为在国内 AI 算力的市场份额已超 60%,政府、金融、能源、运营商等关键领域的国产化采购几乎是确定性增量。
第三方芯片厂商的决策
这是灵衢能否突破"华为生态"的关键。第三方 AI 加速器厂商(壁仞、燧原、沐曦、天数智芯等)面临一个选择题:
选项 A:加入灵衢生态
- 优势:可以直接接入华为的 Atlas 超节点体系,获得华为云、华为渠道的部署机会。在国内政企市场,这条路的商业逻辑很强。
- 代价:核心互联 IP 依赖华为(UB Controller、UBFM),芯片设计自主性受限。而且需要投入大量工程资源适配 UB 协议栈,对于现金流紧张的创业公司来说,这是一笔不小的成本。
选项 B:走以太网优化路线
- 优势:复用以太网生态,适配成本低,不依赖单一供应商。如果未来 UEC 标准成熟,可以无缝升级。
- 代价:性能上限受以太网时延制约,在大规模 MoE 推理场景可能不如灵衢。
选项 C:等 UALink 中国版(OISA)
- 优势:如果 OISA 标准落地,可以获得类似 UALink 的开放互联能力,同时保持国产自主。
- 代价:OISA 目前还在标准讨论阶段,落地时间不确定。等待意味着失去 2026-2027 这个国产算力采购窗口。
现实判断:短期内(2026-2027),选项 B 对大多数国产 AI 芯片厂商是最务实的选择。原因不是以太网技术最优,而是它"够用、不绑、不赌":产业链现成、人才池最大、跟着 UEC 标准走就行。只有客户明确要求万卡级全互联时,灵衢(A)或 HSL 才进入考量。选项 A 的渠道优势确实存在,但对芯片厂商来说,渠道是租来的,互联 IP 是锁进去的——短期跟着项目走选 A 可以理解,但长期看,不绑死一个供应商才有战略空间。
云厂商的选择
国内云厂商的态度更微妙:
- 阿里云:有自研的 EthLink/Eth-X 路线,不太可能全面拥抱灵衢。但阿里云也在卖昇腾实例,可能做有限度的灵衢支持。
- 腾讯云:没有自研互联协议,但也没有公开表态支持灵衢。更可能走以太网路线。
- 百度智能云:有自研的昆仑芯片,互联方案已明确走以太网路线。天池 256 卡超节点(2026 年 6 月上市)基于自研高带宽交换机,不走灵衢。百度的选择进一步印证了以太网路线对第三方厂商的吸引力。
- 字节跳动:自研 ZCube 架构走以太网路线,明确不走灵衢。
云厂商的核心考量是不被单一供应商锁定。灵衢的封闭性(核心 IP 来自华为)让云厂商天然警惕。
国内 GPU 互联标准:谁能跑出来?
回到一个更本质的问题:国内 GPU 互联标准,最终谁能跑出来?后来者还有没有机会?GPU 厂商要不要自研互联技术?专注互联技术的独立厂商能不能活?
先看格局。 目前国内互联赛道上有四类玩家:
- 华为灵衢 — 自研总线协议,绑定昇腾生态,IP 完全自持
- 海光 HSL — IF 授权路线,正在做开放化,角色相对干净
- 以太网路线 — 阿里 EthLink、百度天池,复用 UEC 生态
- OISA — 标准讨论阶段,落地时间不确定
谁能跑出来? 要分两个市场看。
在政企和国产化采购市场,灵衢大概率是事实标准。这个市场的客户不需要选择,因为他们买的是华为 Atlas 整机柜,灵衢是标配。华为的渠道优势在这个市场几乎是不可逾越的。海光 HSL 能切走一部分(海光自己的客户 + 不想被华为绑死的政企),但不太可能动摇灵衢的基本盘。
在互联网和商业市场,以太网路线大概率是主流。百度天池、阿里 EthLink 已经用真金白银投了票。这个市场的客户有自研能力,不需要谁"授权"互联协议,他们需要的是高性能交换机和好的调度软件。以太网生态天然满足这个需求。
所以真正的问题是:国内会不会形成一个统一的互联标准?
大概率不会。国内 AI 算力市场会像全球市场一样分裂——华为系用灵衢,AMD 系用 HSL,互联网系用以太网。唯一的变数是:如果某一天国产 GPU 真的需要互联互通(比如异构集群混合调度),谁能提供跨厂商的互联抽象层?这个位置目前是空白的,也是最大的机会窗口。
GPU 厂商要不要自研互联技术?
大多数情况下,不需要。
互联协议的开发门槛极高——SerDes PHY、FEC 编解码、链路训练状态机、大规模路由算法,每一层都需要数年的工程积累。对大多数 GPU 厂商来说,投入互联研发的资源远不如投入到计算核心和软件栈上。
正确的策略是:选一个现有路线接入,把工程资源集中在差异化上。 寒武纪选择接入灵衢,壁仞选择兼容 CUDA 生态走 PCIe+以太网,都是务实的策略。自研互联只在一种情况下有意义:你的芯片规模已经大到需要定制互联才能发挥性能,而这大约需要年出货量 10 万片以上的规模。
专注互联技术的独立厂商有没有机会?
有,但窗口很窄,商业模式需要想清楚。
全球范围内,专注互联 IP 的公司活得好不多。博通的交换芯片 + SUE 路线之所以有竞争力,是因为博通本身就是交换芯片巨头,SUE 是它的能力延伸,不是从零开始的创业方向。
国内的独立互联厂商(比如提供 PHY IP 的牛芯半导体、提供 Chiplet 互联的芯原股份)的定位更现实:做 IP 供应商,不做标准制定者。向多家 GPU 厂商提供 UB/HSL/以太网的 PHY IP 和控制器 IP,赚取授权费和版税。这个商业模式可行,但天花板也很明显——互联 IP 的市场远小于 GPU 本身的市场。
真正有想象力的路径是:成为跨厂商互联抽象层的提供者。不是做一个新的协议,而是做一套软件 + 固件,让灵衢、HSL、以太网之间可以互通。这需要同时理解总线协议和以太网,需要做协议转换和路由优化,难度极高。但如果有人做到,这就是国产 AI 算力互联互通的基石,价值远超单一协议的 IP 授权。
不过坦率说,这个方向目前还看不到清晰的商业验证。需要有人先做出来,再找客户买单。
十一、核心判断
技术分析做了十章,把判断沉淀下来。五条,按重要性排序。
判断一:灵衢是华为"互联补算力"战略的命门
华为的 AI 算力战略核心逻辑是"用数学补物理,非摩尔补摩尔"。单芯片受制程限制做不过 NVIDIA,就用互联优势把更多芯片粘在一起,靠系统级吞吐取胜。灵衢是这个战略的基础设施。如果灵衢失败(大规模组网不可靠、时延不达预期、或第三方芯片厂商拒绝适配),华为的整个超节点战略就会动摇。
判断二:灵衢的竞争窗口在 2026-2027,比预想的更短
2026-2027 年是灵衢的关键窗口期。原因:
- UALink 2.0 已发布,实际产品 2027 年下半年大规模出货,比预期快。
- AMD Helios 平台 2026 年下半年交付,将证明 UALink+以太网的双层架构可行。
- 海光 HSL 1.0 已发布,虽然生态刚起步,但海光全栈开放的策略正在吸引国产芯片厂商。
- 博通 Tomahawk Ultra 已经量产,以太网 Scale-Up 的性能在快速逼近总线级。
灵衢的时间窗口不是 3 年,可能只有 1.5-2 年。如果 2027 年底之前不能建立明确的生态优势,来自 HSL、UALink 和以太网的三面夹击会让灵衢退回到华为内部。
判断三:灵衢在国内的核心威胁是海光 HSL 的开放性优势
NVLink 是一个封闭但统治性的互联标准。所有 NVIDIA GPU 必须用 NVLink,没有选择。灵衢做不到这个地位,因为华为没有 NVIDIA 那样的芯片市场统治力。
在国内市场,灵衢面临的问题更具体:海光 HSL 正在做灵衢做不到的事--成为国产芯片的统一互联标准。HSL 的优势不是技术更强(IF 授权的带宽可能不及灵衢的 118 Gbps),而是"角色干净":海光不和其他 GPU 厂商竞争核心算力市场,它提供互联协议让其他厂商接入,这种定位天然更容易被接受。
灵衢的应对策略应该是进一步开放:不只是协议规范公开,还要开放 UB Controller IP、提供免费授权、建立独立的技术委员会。但这意味着华为要放弃对灵衢的控制权,这个决策很难做。
第三方芯片厂商的优选路径是以太网路线,这不仅仅是技术判断,也是商业决策:
- 技术层面:以太网路线零供应商绑定、产业链现成、人才池最大,迭代跟着 UEC 标准走就行。只有客户明确要求万卡级全互联时,灵衢或 HSL 才进入考量。不是以太网技术最优,而是"够用、不绑、不赌"。
- 商业层面:芯片厂商选互联路线,本质上是在选生态站位。选灵衢意味着跟华为深度绑定,连 UB Controller 都要向华为拿 IP;选 HSL 意味着跟海光结盟;选以太网意味着谁都不用跟。在一个供应链安全感极度敏感的市场里,这个选择往往不是纯粹的技术比较,而是商业信任和风险偏好的综合结果。百度天池、阿里 EthLink 都走以太网路线,不是因为它们不懂总线协议的优势,而是因为这是商业上最可预测的选择。
判断四:灵衢真正的风险不在技术层面
技术层面,灵衢的五层协议栈设计是扎实的,118 Gbps/Lane 的速率虽然不及 NVLink 6 但在工程上合理,8192 卡无收敛全互联的组网能力是目前公开方案中最大的。
但灵衢面临的风险不在技术层面:
- 国产芯片厂商的依赖恐惧:没有人愿意把核心互联交给一个既是供应商又是竞争对手的公司。华为既是昇腾芯片的厂商,又掌握灵衢的核心 IP,这种双重角色会让第三方厂商犹豫。
- 商业信任比技术参数更难解决:第三方厂商选互联协议,不只是在比带宽和时延。他们要评估的是:如果选了灵衢,三年后华为会不会在接口上做差异化?会不会在固件更新上优先服务昇腾?供应链安全审查时,用灵衢会不会被视为"深度依赖华为"?这些顾虑不是技术文档能打消的。
- 标准话语权的博弈:灵衢是华为自研协议,不是开放标准。即使协议规范公开,核心专利和硬件 IP 仍然在华为手里。OISA、UALink 等开放标准的存在,会持续给灵衢施加"不够开放"的压力。
- 出口管制的非技术约束:灵衢的 SerDes 速率和大规模组网能力可能触碰出口管制的敏感线。如果国际环境进一步收紧,灵衢的海外推广可能受阻。
判断五:灵衢最大的商业价值在推理,不在训练
这个判断可能反直觉:大多数人认为大规模训练是灵衢最大的用武之地。但仔细想:
- 训练任务对互联的需求是脉冲式的,在梯度同步时需要大带宽 All-Reduce,其他时间通信密度不高。
- MoE 推理对互联的需求是持续性的,每次推理都触发 All-to-All 通信(专家路由),对时延极度敏感。百纳秒级的 Load/Store 直接内存访问,对 MoE 推理的吞吐提升远大于对训练的提升。
- 随着推理算力需求超过训练(行业趋势),灵衢在推理场景的价值会越来越大。
DeepSeek V4-Pro 在昇腾千卡集群上的稳定训练(MFU 34.9%)已经证明了灵衢在训练场景的可行性。但灵衢更大的商业价值可能在 MoE 推理。特别是 PD 分离架构下,Prefill 和 Decode 之间频繁的 KV Cache 传输,灵衢的统一内存语义可以提供比 RDMA 更低的时延。
十二、结语
回到标题:灵衢是中国算力突围的互联赌注。
华为赌的是:在 AI 算力时代,互联比单芯片更重要,而一个统一的、从物理层到事务层全覆盖的协议栈,优于现有协议的拼凑组合。这个赌注有道理。MoE 架构的普及确实让互联成为瓶颈,单靠"更快更大的 GPU"已经不够了。
但赌注能不能赢,不完全取决于技术。灵衢需要回答三个问题:
- 第三方会不会跟进? 没有生态的互联协议只是一个私有方案。灵衢需要证明自己不只是华为的内部工具。
- 时间窗口够不够宽? 2026-2028 年的窗口期,灵衢需要从 8192 卡扩展到更大规模(华为已经透露 10 万卡级别的规划),同时把可靠性打磨到生产级。
- 开放性怎么做? 协议规范公开是第一步,但不够。UB Controller IP 的授权模式、UBFM 固件的开放程度、openFuyao 的社区治理结构,这些才是决定"开放"成色的指标。
华为说"用数学补物理",灵衢就是那个数学。但数学能不能补上制程的差距,最终要看有多少人愿意用这套数学。