从 RoCE 到 MRC:AI 集群传输协议与芯片重构
OpenAI 联合 NVIDIA、AMD、Broadcom、Arista、Cisco 五家巨头,用 MRC 协议同时推翻了数据中心网络三十年的五个共识。把智能从交换机推到网卡,让交换机回归无状态转发--这个设计哲学转变的背后,是一整套芯片层面的架构重构。
本文是「AI 训练网络技术全景」的姊妹篇之二,聚焦传输协议与芯片实现。姊妹篇之一「从 CLOS 到 ZCube:智算集群网络拓扑演进」深入分析拓扑设计的物理层创新。全景综述篇见「AI 训练网络技术全景:从 CLOS 到 ZCube,从 RoCE 到 MRC」。
131,072 块 GPU 的网络难题
2025 年底,OpenAI 的生产集群跑着 131,072 块 GPU。按传统的 InfiniBand 或 RoCEv2 网络来建,这个规模会碰上三个天花板:
第一,ECMP 哈希冲突。 传统网络用哈希把流量分散到多条等价路径上。但哈希是概率性的--当集群里有上万条链路、每秒数十亿个 packet,必然出现 hot-spot。某条链路被两个大流量同时选中,延迟飙升,AllReduce 等集体通信的尾巴延迟拖垮整个训练 step。
第二,PFC 的连锁反应。 RoCEv2 依赖 Priority Flow Control 实现无损网络--接收端 buffer 快满了就发 pause frame 让发送端停下。但在大规模 Clos 拓扑里,pause frame 会沿着网络向上游传播,形成 incast 风暴。更糟糕的是,不同优先级的 pause frame 可以互相死锁。规模越大,PFC 越不可控。
第三,动态路由的收敛延迟。 BGP/OSPF 在链路故障后需要重新计算路由表。在一个 10 万 GPU 的集群里,收敛可能需要几十毫秒到几百毫秒。训练 job 对延迟极其敏感--一次路由收敛就可能导致 AllReduce 超时,整个 job 从 checkpoint 重启。
OpenAI 的回答是 MRC(Multipath Reliable Connection)--一个从零开始设计的网络传输协议。它不只解决了上述三个问题,而是从根本上改变了"网络中的智能应该放在哪里"。
五个被推翻的共识
MRC 同时推翻了数据中心网络设计三十年来形成的五个共识。不是修修补补,是逐条推翻。

1. ECMP 哈希 → Entropy Value 包 Spraying
旧做法: 交换机用五元组哈希选择下一跳。同一 flow 的所有 packet 走同一条路径。路径选择完全由交换机决定,终端(NIC)没有控制权。
MRC 做法: 每个 QP(Queue Pair)维护 128-256 个 Entropy Value(EV),每个 EV 映射到一条端到端路径。NIC 发包时 round-robin 遍历所有 active EV,把 256 条路径同时用起来。
为什么: ECMP 的根本问题是粒度太粗--一个 flow 只能走一条路。在 AllReduce 场景下,少数几个大 flow 就能把某条链路打满。EV spraying 把每个 QP 的流量打散到 256 条路径上,从根本上消除了 hot-spot。
生产数据: OpenAI 报告 256 条路径均匀分摊流量,带宽利用率从 ECMP 的 ~60% 提升到 ~95%。
2. PFC 无损网络 → 禁用 PFC,允许丢包
旧做法: RoCEv2 用 PFC pause frame 实现无损网络。Buffer 快满就 pause,保证不丢包。代价是 incast 风暴和死锁风险。
MRC 做法: 直接禁用 PFC。允许交换机丢包。丢包的后果由 NIC 自己处理--通过 selective ACK 精确重传丢失的 packet。
为什么: 在 10 万 GPU 集群里,PFC pause frame 的传播链太长,任何一环出问题都可能引发级联故障。MRC 的哲学是:与其花大力气保证网络不丢包,不如让丢包成为常态,然后在终端高效处理。这和互联网的设计哲学一致--TCP 就是在一个会丢包的网络之上实现可靠传输。
3. 单路径有序交付 → 乱序直写
旧做法: RoCEv2 要求 packet 按 PSN(Packet Sequence Number)顺序到达。接收端发现 PSN 不连续就丢弃乱序 packet,触发 go-back-N 重传。
MRC 做法: 256 条路径同时发包,packet 必然乱序到达。MRC 不但不要求有序,还专门设计了 Out-of-Order Direct Write--每个 packet 自带 RDMA 虚拟地址和 remote key,不管到达顺序,直接写入对应的内存位置。
为什么: 如果要求有序交付,256 条路径中任何一条慢了,都会阻塞整个 QP。这等于把并行路径的优势全部抵消。乱序直写让每条路径可以独立前进,互不干扰。只有当某个地址范围的所有 packet 都到齐了,才生成 CQE(Completion Queue Entry)通知上层。
4. 动态路由 → SRv6 uSID 静态源路由
旧做法: 交换机运行 BGP/OSPF/IS-IS,动态计算路由表。链路故障后触发路由收敛,所有受影响的 flow 重新选路。
MRC 做法: 用 SRv6 uSID(16-bit 压缩段路由)在发送端指定完整路径。路径信息编码在 IPv6 目的地址里。交换机不需要运行任何路由协议--它只做一件事:匹配目的地址前缀,左移 16 bit,转发到对应端口。路由表在交换机启动时写入,之后不变。
为什么: 动态路由在大规模集群里有两个致命问题:收敛延迟(故障后流量中断)和 ECMP 哈希不可控(收敛后流量分布不均)。静态源路由把路径控制权交给发送端 NIC--NIC 知道哪些 EV 是健康的、哪些是拥塞的,可以主动选择好路径,不需要等网络收敛。
5. 交换机做拥塞控制 → 交换机只做 ECN 标记
旧做法: 交换机通过 PFC pause frame 和 ECN(Explicit Congestion Notification)参与拥塞控制。网络和终端协同调节发送速率。
MRC 做法: 交换机的角色被简化到极致--转发 packet,标记 ECN,什么都不管。ECN 标记带有 EV tag,NIC 收到后知道具体是哪条路径拥塞,标记对应 EV 为 congested,换一个 EV 继续发包。不降速,只换路。
为什么: 交换机不维护 per-flow 状态,不知道哪个 QP 在用哪条路径。让它做拥塞控制是"用错误的信息做错误的决策"。NIC 有完整的 EV 状态,能做出精准的路径选择。
MRC 不是唯一的答案:UET 在并行演进
MRC 和 UET(Ultra Ethernet Transport,UEC 1.0 规范)不是竞争关系,而是互补关系。MRC 论文明确说"借鉴了 UET 的多项技术"。
共享的核心概念:包喷射(packet spraying)、乱序放置、选择性重传、packet trimming、禁用 PFC。这些是两家独立得出相同结论的技术方向--说明行业对 RoCEv2 的局限性有共识。
关键差异:
| 维度 | MRC | UET (UEC 1.0) |
|---|---|---|
| 设计哲学 | 最小化修改 RoCEv2 RC 传输层 | 全新传输栈(75% 来自 HPE Slingshot) |
| 软件接口 | RDMA Verbs(Write + WriteImm 子集) | libfabric v2.0 |
| 源路由 | SRv6 uSID 静态源路由 | 无(依赖交换机路由) |
| 拓扑 co-design | 多平面 Clos 两层拓扑 | 独立于拓扑 |
| 生态进度 | OpenAI/Microsoft 大规模生产验证 | 规范 2025 年 6 月发布,落地中 |
| 芯片支持 | ConnectX-8 / Thor Ultra / Pollara | Pollara 400(首款完全兼容) |
MRC 走的是实用主义路线--在现有 RDMA 生态上做最小扩展,部署门槛低。UET 走的是全新传输栈路线--从 API 层开始重新设计,理论上更干净但迁移成本更高。
这对选择者意味着什么:如果已有 RDMA 应用和 Verbs 软件栈,MRC 的迁移路径更平滑。如果是新部署且愿意投入软件栈重构,UET 的设计更前瞻。AMD 的 Pollara 同时支持两者,是一个聪明的对冲策略。
四协议完整对比
| 维度 | RoCEv2 | MRC | UET (UEC 1.0) | InfiniBand |
|---|---|---|---|---|
| 多路径 | 无(ECMP 流级) | ✅ 包喷射 128-256 路径 | ✅ 包喷射 | ✅ 自适应路由 |
| 丢包恢复 | Go-Back-N/选择性重传 | 选择性重传 + trimming | 选择性重传 + trimming | 链路级+传输级重传 |
| 流控 | PFC(无损) | 禁用 PFC | Credit-based | Credit-based |
| 源路由 | 无 | SRv6 C-SID | 无 | 无 |
| 故障恢复 | 秒级(路由收敛) | 微秒级(NIC 绕行) | 毫秒级(待验证) | 秒级(Subnet Manager) |
| 部署复杂度 | 中 | 中高 | 高 | 中(NVIDIA 一体化) |
| 成本 | 低 | 中 | 中 | 高 |
| 适用规模 | ≤64K GPU | 100K+ GPU | 100K+ GPU | ≤64K GPU(经济规模) |
| 软件接口 | RDMA Verbs(全部) | RDMA Verbs(Write+WriteImm) | libfabric v2.0 | RDMA Verbs |
| 生态成熟度 | ★★★★★ | ★★★★(OpenAI/MS 生产) | ★★★(规范刚发布) | ★★★★★(NVIDIA 全栈) |
InfiniBand 的角色: NVIDIA 通过收购 Mellanox 主导 IB 生态。XDR(800 Gb/s)正在部署(Quantum-X800 + ConnectX-8),GDR(1600 Gb/s)在路线图。IB 技术优势(原生无损、超低延迟 1-2μs、全栈兼容)与劣势(成本高、供应商锁定、运维人才稀缺)并存。Gartner 预测到 2029 年 >65% 生成式 AI 集群将基于以太网,IB 退守对延迟极端敏感的高端细分。
标准化格局
当前 AI 网络协议标准呈"三线并行":
| 项目 | 组织 | 状态 | 说明 |
|---|---|---|---|
| RFC 9800 | IETF | ✅ 已发布 | SRv6 压缩段列表(C-SID/uSID) |
| RFC 9743 | IETF | ✅ 已发布 | 新拥塞控制规范指南 |
| MRC 1.0 | OCP | ✅ 2026.05 | OpenAI 牵头,开放许可 |
| UET 1.0 | UEC | ✅ 2025.06 | 120+ 公司成员 |
| 802.3df | IEEE | ✅ 2024 | 800G 以太网标准 |
| 802.3dj | IEEE | 推进中 | 1.6T 以太网(200G/lane),预计 2026-2027 |
| XDR | IBTA | ✅ 2023.10 | 800 Gb/s InfiniBand |
三条路线不互斥:MRC 借鉴 UET 技术,SRv6 服务于 MRC 源路由需求,IETF 提供底层源路由基础设施。
协议核心机制
EV 四状态机
每个 EV 有四个状态,对应一条路径的健康程度:
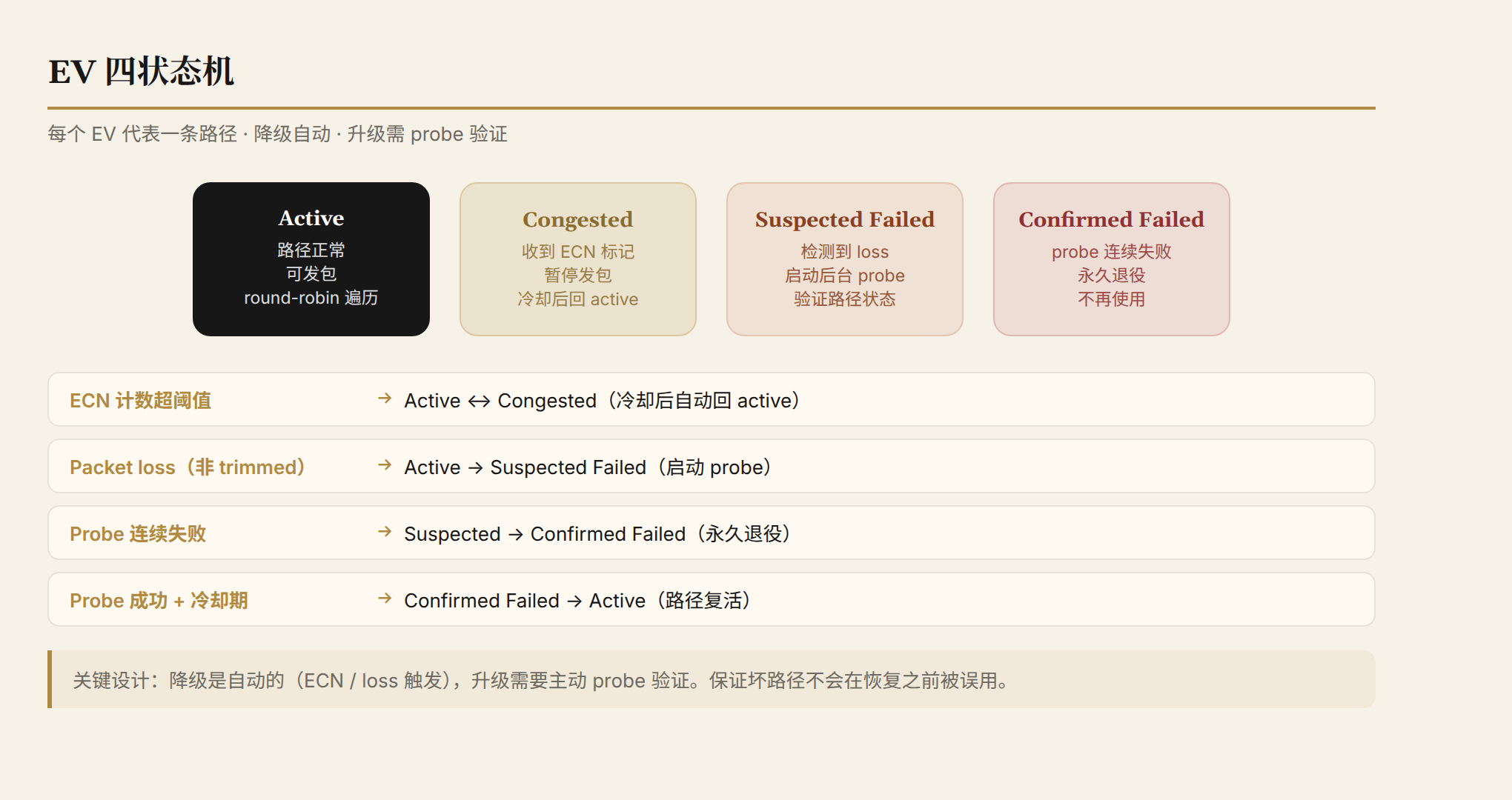
- Active:路径正常,可以发包。发送端 round-robin 遍历所有 active EV。
- Congested:收到带 EV tag 的 ECN 标记后进入。该 EV 暂停发包,等待冷却后回到 active。
- Suspected Failed:检测到 packet loss(非 trimming)后进入。启动后台 probe 检测路径是否真的断了。
- Confirmed Failed:probe 连续失败。该 EV 被永久退役,不再使用。
状态转换的关键设计:降级是自动的(ECN 触发、loss 触发),升级需要主动 probe 验证。 这保证了坏路径不会在恢复之前被误用。
SRv6 uSID:为什么不是标准 SRv6
SRv6(Segment Routing over IPv6)在运营商网络已经有成熟应用。但 MRC 选择了 uSID(Micro SID,RFC 9800)这个压缩变体,而不是标准 SRv6。这不是随意选择。
标准 SRv6 的问题:每个 segment 是一个 128-bit SID,多个 SID 组成 SRH(Segment Routing Header)--一个变长扩展头。交换机芯片的 parser 需要跳过 SRH 才能读内层 header。在大带宽场景下,处理变长头的延迟不可控,很多芯片做不到线速。
uSID 的解法:把多个 16-bit 的 uSID 压缩进一个 128-bit 的 IPv6 目的地址。不需要 SRH 扩展头。交换机的转发操作变成三步:
- 匹配目的地址前 48 bit(本机 locator)
- 目的地址左移 16 bit(下一个 uSID 移到前面)
- 查静态转发表,转发到对应端口
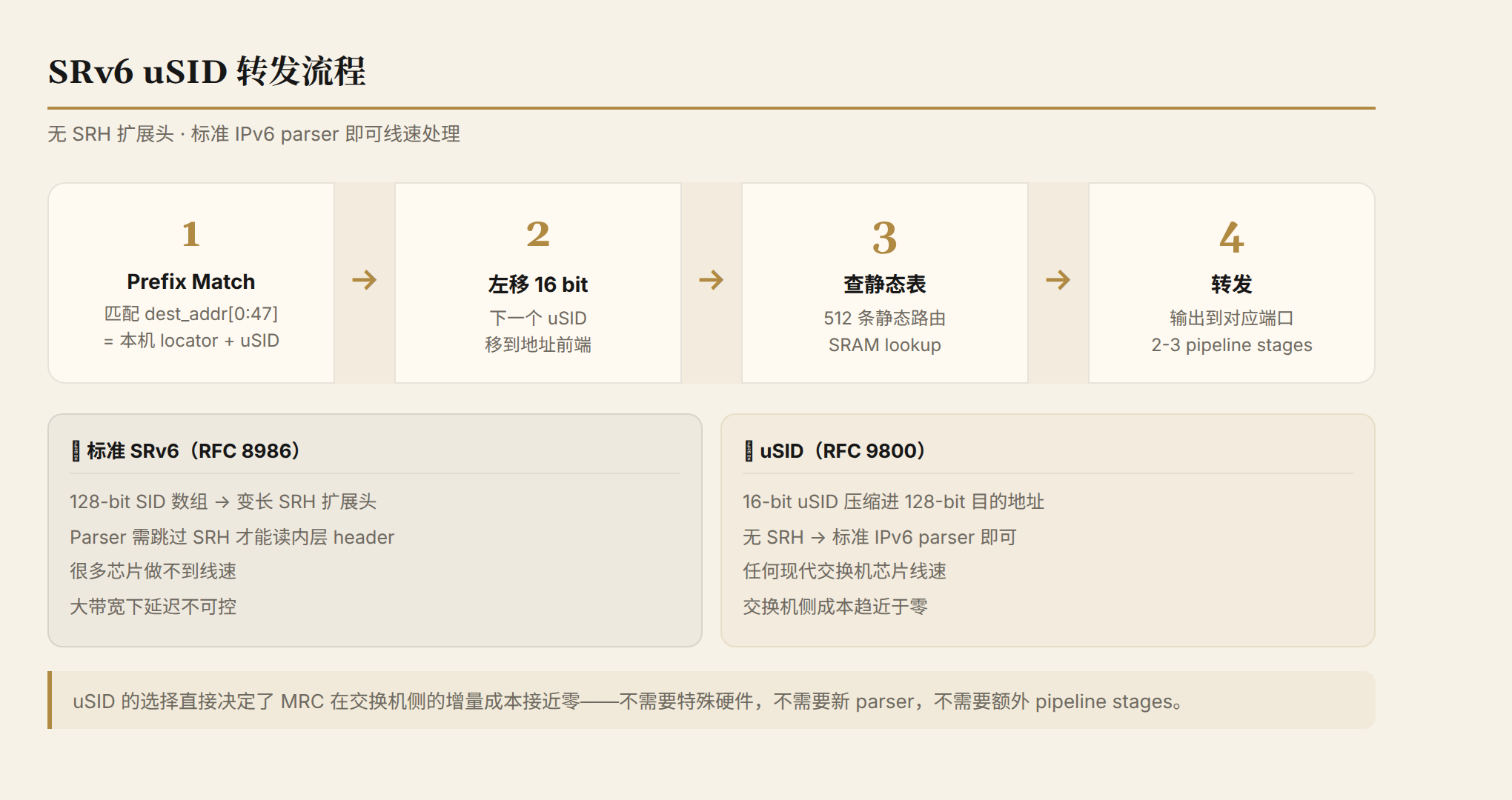
这个三步操作只需要 2-3 个 pipeline stage,任何现代交换机芯片都能线速完成。标准 IPv6 parser 就够了,不需要任何特殊硬件。
这是一个关键的设计决策:uSID 的选择直接决定了 MRC 在交换机侧的成本趋近于零。
Packet Trimming:拥塞不丢包,但也不传数据
Packet trimming 是 MRC 的一个精巧设计:当交换机检测到拥塞,它可以选择不丢弃整个 packet,而是只保留 header、剥离 payload,把 trimmed header 作为 priority packet 转发给接收端。
接收端 NIC 收到 trimmed header 后知道两件事:
- 路径还活着(只是拥塞)→ 发 NACK 触发重传
- 不需要等待 timeout → 降低重传延迟
如果 NIC 完全没收到 packet(连 header 都没有),就知道路径可能断了 → 退役对应 EV。
这个设计把丢包事件分成了两种语义:"拥塞丢包"用 trimming 处理(路径还在),"故障丢包"用 EV 退役处理(路径可能断了)。 精确区分两种情况,让恢复策略更有针对性。
芯片层面:NIC 要什么
协议设计是一回事,把它烧进硅片是另一回事。MRC 对 NIC 的硬件要求是结构性的--不只是多加几个寄存器,而是需要新的 IP 核。
Per-QP 状态:从 512 字节到 16KB
传统 RoCE 的 QP(Queue Pair)context 非常轻量--PSN、内存窗口、几个指针,大约 256-512 字节。
MRC 让这个数字暴增到 ~16KB per QP:
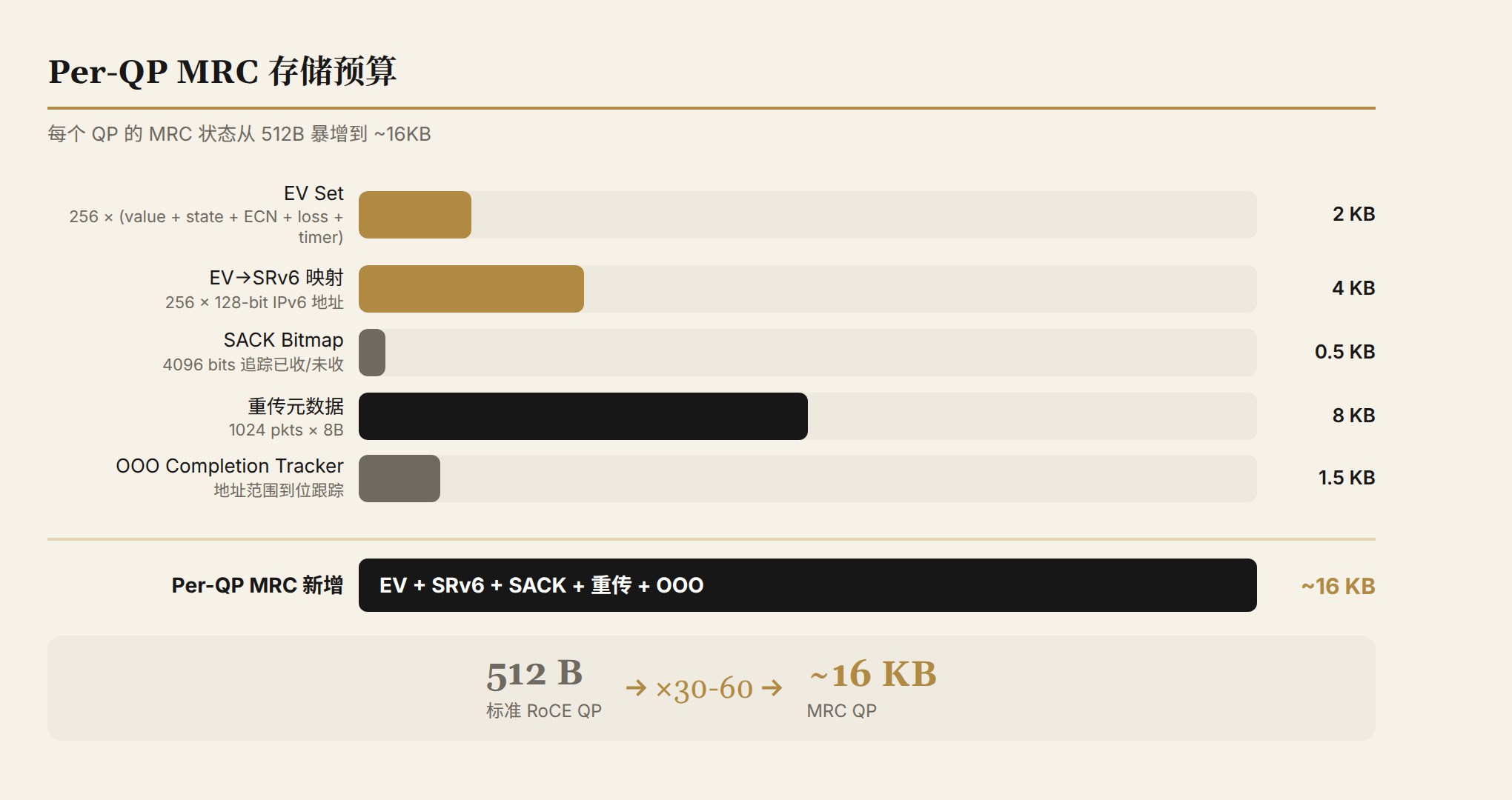
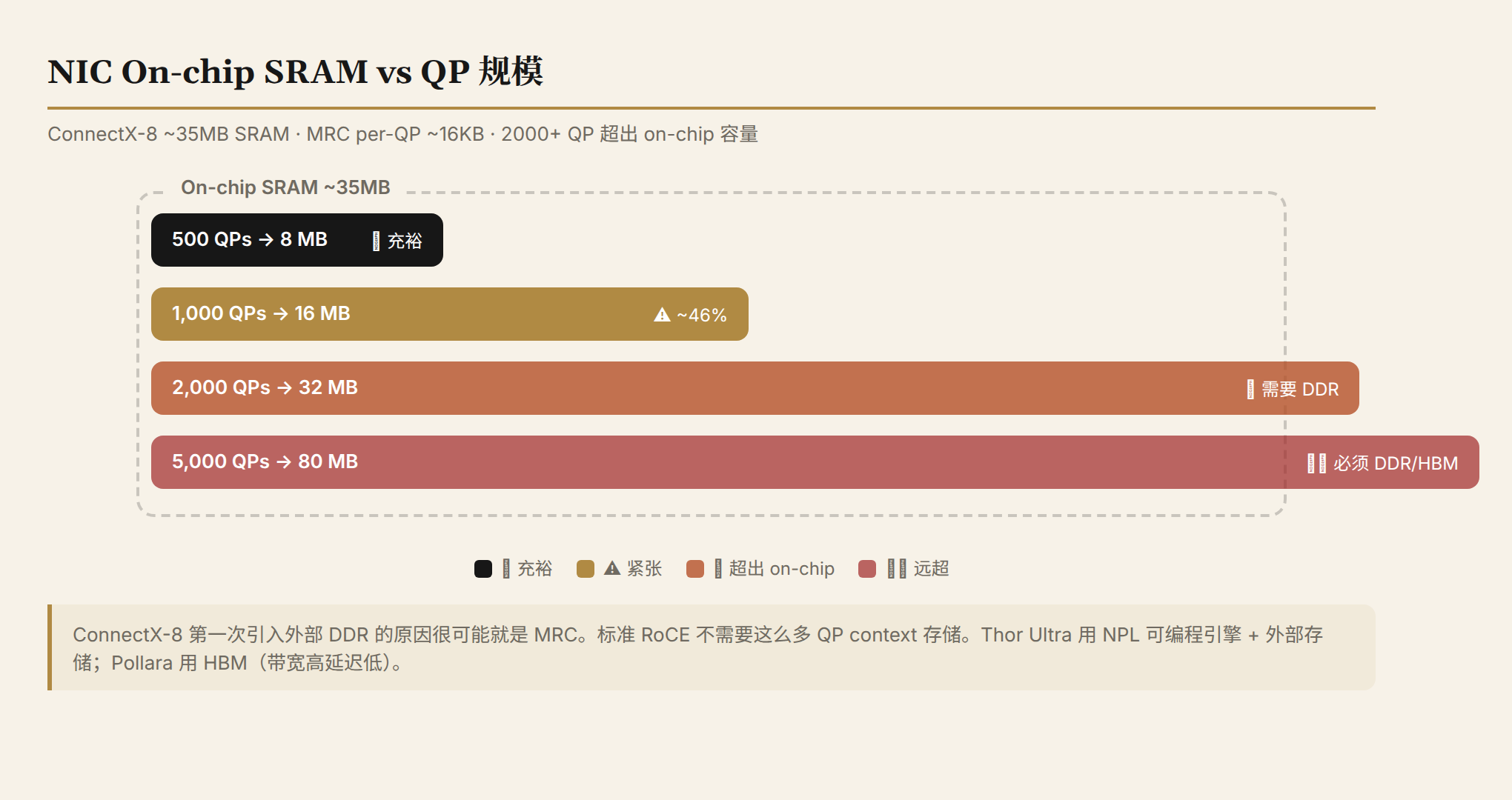
16KB 听起来不多。但一个 800G NIC 在全负载下可能有 1,000-5,000 个活跃 QP:
| 活跃 QP | MRC 存储 | On-chip SRAM (~35MB) | 需要外部存储? |
|---|---|---|---|
| 500 | ~8 MB | ✅ 充裕 | 不需要 |
| 1,000 | ~16 MB | ⚠️ ~46% | 紧张但可行 |
| 2,000 | ~32 MB | ❌ 超出 | 需要 DDR 缓存 |
| 5,000 | ~80 MB | ❌ 远超 | 必须 DDR/HBM |
30-60 倍的 per-QP 存储增长,直接解释了为什么 ConnectX-8 第一次引入了外部 DDR。 标准 RoCE 不需要这么多存储--40 个 QP × 512B = 20KB,轻松放进 on-chip SRAM。MRC 的 1000 个 QP × 16KB = 16MB,开始逼近 on-chip 极限。
六个新硬件 IP
MRC 需要 NIC 芯片加入以下硬件 IP,传统 RoCE NIC 不具备:
- RDMA OOO write engine - 传统 RDMA 假设有序交付,IP 核不支持乱序写入。需要新设计。
- EV state machine - 256 个 per-QP,微秒级状态转换。需要专用 SRAM + 控制逻辑。
- SRv6 uSID encap/decap - 发送端把 EV 映射为 IPv6 目的地址(组合逻辑),接收端剥离。
- SACK bitmap + selective retransmit - per-QP bitmap 精确追踪已收/未收 packet,硬件重传队列。
- ECN-to-EV mapper - 不做 rate control,做路径选择。收到 ECN 标记后定位到具体 EV 并标记为 congested。
- Probe engine - 后台路径探测,硬件定时器 + packet 生成/解析。
粗估硅片增量:~20-30% die area vs 同代 RoCE NIC。 主要增量来自 EV state SRAM(256 × 16KB = 4MB per QP set × N QPs)。在 5nm 工艺下约 $10-20 die cost 增量。
三家 NIC 的三种策略
NVIDIA ConnectX-8、AMD Pollara、Broadcom Thor Ultra 都声称支持 MRC,但实现路径不同:
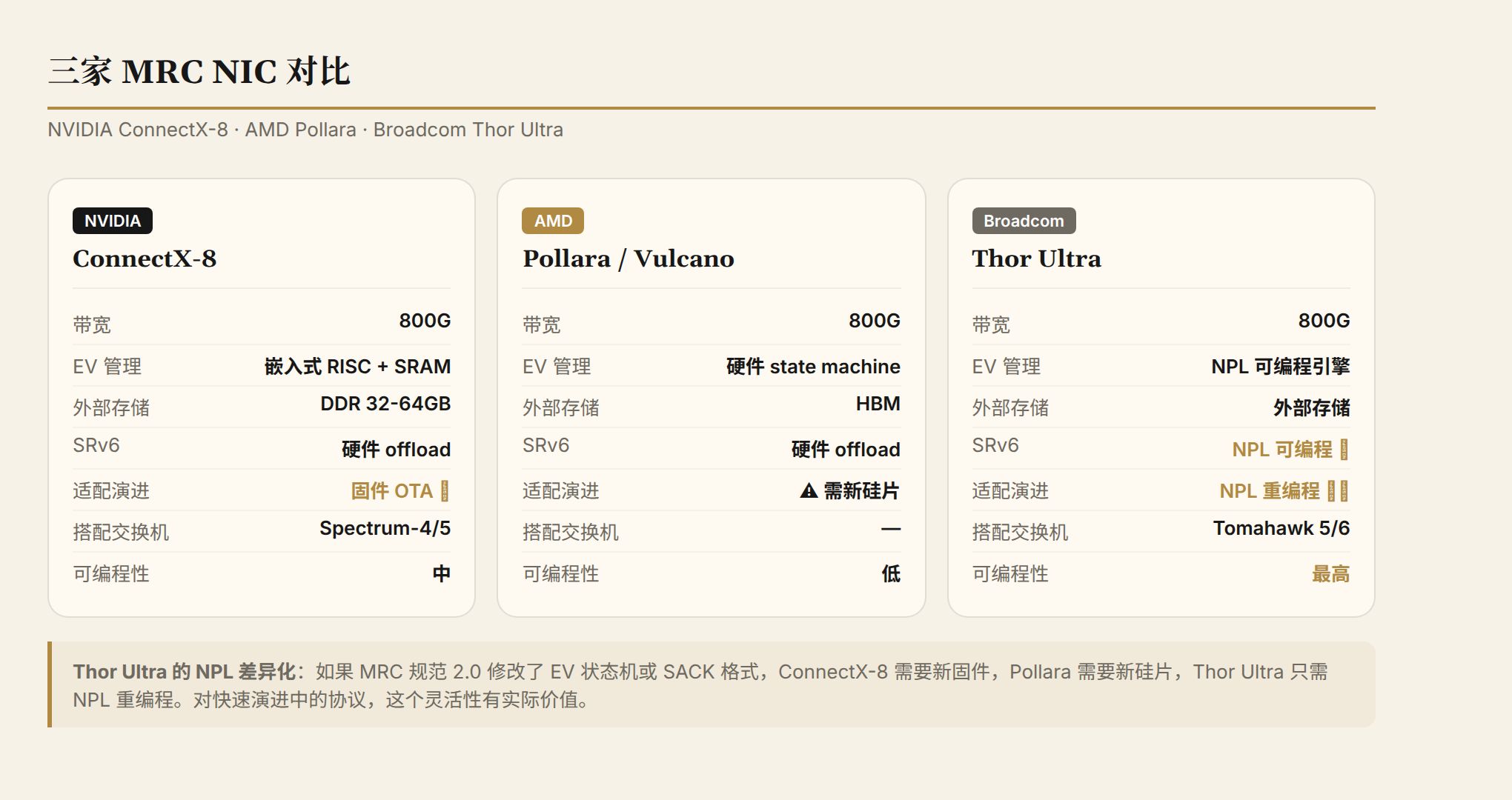
ConnectX-8 用嵌入式 RISC 核 + 专用 SRAM 管理 EV 状态,热 QP 放 on-chip,冷 QP 溢出到外部 DDR。固件 OTA 可以更新 MRC 逻辑,适应规范演进。
AMD Pollara 把 EV state machine 烧成固定硬件逻辑,状态存储放在 HBM(带宽高延迟低)。性能可能最好,但如果 MRC 规范 2.0 修改了 EV 状态机,需要新一代硅片。
Broadcom Thor Ultra 用 NPL(Network Programming Language)实现 MRC 逻辑。NPL 可以在芯片出厂后重新编程--如果 MRC 规范演进,只需要更新 NPL 微码,不需要新硅片。这个灵活性对 MRC 这种快速演进中的协议有实际价值。
芯片层面:交换机反而变简单了
MRC 对交换机的改变是反直觉的:加了一点点东西,省掉了大量东西。
加法
| 功能 | 硬件需求 | 难度 |
|---|---|---|
| SRv6 uSID 线速转发 | 48-bit prefix match + 128-bit 左移 + SRAM lookup = 2-3 pipeline stages | 中 |
| 静态路由表 | 512 entries × 8 bytes ≈ 4KB | 低 |
| ECN per-port 开关 | 512 bits | 低 |
| Packet trimming | Ingress buffer 裁剪 + priority forwarding,~1-2MB | 中 |
减法
| 传统功能 | MRC 还需要吗? | 释放的资源 |
|---|---|---|
| BGP/OSPF/IS-IS FIB | ❌ 不需要 | 几 MB TCAM + 控制面 CPU |
| Large ECMP groups (256+ members) | ❌ 不需要 | 大量 TCAM |
| PFC pause frame 处理 | ❌ 禁用 | ~50MB buffer + pipeline 逻辑 |
| Link-layer retransmission | ❌ 不需要 | Ingress pipeline 简化 |
| PFC deadlock 检测 | ❌ 不需要 | 控制逻辑简化 |

以 Spectrum-4(51.2T, ~256MB buffer)为例:
MRC 新增消耗约 4-5MB(trimming 暂存 + SRv6 header 开销)。但禁用 PFC 释放了约 50MB buffer,加上不再需要 LPM TCAM 和 ECMP groups TCAM。净效果是 buffer 更宽裕了,TCAM 压力降低了。
102.4T 代的 Tomahawk 6 更有意思--它的 buffer 只有 267MB(比 Spectrum-4 多 11MB,但带宽翻倍,每 bit buffer 下降了 34%)。MRC 省掉的 PFC buffer 恰好弥补了这个缺口。而且 Tomahawk 6 原生支持 Cognitive Routing 2.0(智能负载均衡)和 Packet Trimming(CSIG 模块),这些特性不是 MRC 后加上去的,是芯片设计时就内置了。
131K GPU 集群的真实拓扑
OpenAI 的生产集群用 51.2T 设备(128×400G 交换机)部署 8 个并行网络平面:

关键参数:
| 层级 | 每 plane | 8 planes |
|---|---|---|
| T0(接入层,128×400G) | 64 台 | 512 台 |
| T1(汇聚层,128×400G) | 32 台 | 256 台 |
| 合计 | 96 台 | 768 台 |
| 100G 光模块 | ~49K | ~393K |
拓扑细节: 每个 GPU 配一块 800G NIC,breakout 成 8×100G--每条 100G 连一个 plane。T0 交换机 128×400G breakout 成 512×100G,其中 256 下行连 NIC,256 上行连 T1。
故障恢复
论文报告了几个生产环境的故障恢复案例:
| 故障 | 恢复行为 |
|---|---|
| T0 交换机重启 | 训练 job 短暂降速 1-2 秒,不需要 restart |
| 4 条链路同时 flap | 训练短暂降速后自愈 |
| T1 交换机重启 | 受影响 plane 的 NIC 退役对应 EV,其余 plane 不受影响 |
T0 交换机重启不用重启训练 job--这在传统 RoCE 网络里不可想象。 传统网络里,交换机重启意味着所有经过它的 flow 中断,AllReduce 超时,job 从 checkpoint 重启。MRC 里,NIC 检测到路径失败后退役对应 EV,自动切换到其他路径,上层几乎无感知。
O(N) Scaling
从 131K 扩展到 500K GPU:
| 131K | 500K | 变化 | |
|---|---|---|---|
| 交换机数量 | 768 台 | ~3,000 台 | 线性 |
| 每台交换机路由表 | 512 条 | 512 条 | 不变 |
| 每台交换机 buffer 需求 | 同 | 同 | 不变 |
每台交换机只关心本地端口的静态路由表。集群翻倍只需要加交换机,不需要改路由协议、不需要重新规划拓扑。这个 O(N) 的 scaling 特性直接来自静态路由--没有 BGP 收敛延迟、没有 ECMP 哈希重分布。
定量性能:MRC 在生产环境的表现
MRC 论文和 OpenAI 公开资料报告了以下生产环境数据:
带宽利用率
- ECMP (RoCEv2):~60% 带宽利用率(flow collision 导致链路空转)
- MRC EV spraying:~95% 带宽利用率(256 条路径均匀分摊)
- 提升:~58% 的有效带宽增加
故障恢复
| 故障场景 | MRC 行为 | 传统 RoCEv2 行为 |
|---|---|---|
| T0 交换机重启 | 训练 job 降速 1-2 秒后自愈 | 所有经过该交换机的 flow 中断,AllReduce 超时,job 从 checkpoint 重启 |
| 4 条链路同时 flap | 训练短暂降速后自愈 | PFC 风暴扩散,多 job 受影响 |
| T1 交换机重启 | 受影响 plane 的 NIC 退役对应 EV | BGP 收敛秒级延迟,训练中断 |
关键数据:OpenAI 报告训练过程中热重启 4 台 T1 交换机,无需协调训练团队,任务继续运行。这在传统 RoCE 网络里不可想象。
中国产业:差距在哪
硬件差距
交换机芯片:盛科的 GoldenGate 系列做到 25.6T,而 NVIDIA Spectrum-4 和 Broadcom Tomahawk 5 已经是 51.2T,Tomahawk 6 做到了 102.4T。中国交换机芯片在容量上差了一代。
但交换机差距的影响在缩小——MRC 简化了交换机需求(减法 > 加法),国产交换机只要支持 SRv6 uSID 线速转发就可以用。华为 CloudEngine XH9000(350ns 超低时延)和新华三 S9828-128EP(102.4T)在硬件规格上已经不落后。真正的差距在 NIC。
NIC 芯片:没有对标 ConnectX-8、Pollara、Thor Ultra 的产品。800G 智能 NIC(带 MRC 支持)目前是空白。这是最关键的短板——MRC 的智能全部在 NIC,NIC 不支持 MRC 就等于不支持这个协议。
光模块:中际旭创、新易盛等厂商在 800G/1.6T 光模块领域已进入全球第一梯队,光模块不是瓶颈。
软件差距
NOS(网络操作系统):没有任何国产 NOS 做过 MRC 适配。SRv6 uSID 的 16-bit 压缩格式和标准 SRv6 的 parser 路径不同,即便硬件支持 SRv6,也需要专门验证 uSID 的线速转发。华为 VRP 和新华三 Comware 在 SRv6 标准格式上有支持,但 uSID 需要专门的开发验证。
MRC 管理平面:SRv6 uSID 的路径计算、uSID 分配、故障后路径重算需要成熟的管理编排工具。OpenAI 没有公开这部分的实现细节。
MRC 对中国厂商的机会
开放标准的意义:MRC 是 OCP 开放规范,不像 InfiniBand 被 NVIDIA 独家控制。中国厂商可以基于开放规范开发兼容产品,没有专利壁垒。这比追赶 InfiniBand 现实得多。
交换机先行的路径:由于 MRC 简化了交换机需求,中国交换机厂商(华为、新华三、锐捷)可以较快速地支持 MRC。第一步是 SRv6 uSID 线速转发——这主要是固件工作,硬件基础已经具备。
NIC 是追赶难点:需要从零设计 EV 状态机 + OOO write engine + SACK bitmap 等硬件 IP。考虑到 die cost 增量 20-30%,这需要相当于 ConnectX-7/8 级别的芯片设计能力。短期看,与 Broadcom/AMD 合作集成可能是更现实的路径。
核心壁垒
差距不在协议——MRC 的论文是公开的,OCP 规范也在标准化过程中。真正的壁垒是规模验证。OpenAI 在 131,072 块 GPU 上跑了数月的生产数据,证明 MRC 在大规模下的可用性。后来者需要同等规模的验证,否则没有人敢在一个 10 万 GPU 集群上赌新协议。
这不是技术问题,是信任问题。
MRC 与非对称拓扑的协同:源路由让拓扑自由了
MRC 的设计假设是多平面两层 Clos——这是 OpenAI 的实际部署拓扑。但 MRC 的核心机制(SRv6 静态源路由 + 包喷射 + 禁用 PFC)对拓扑结构本身是中性的:只要每对 GPU 之间有多条路径,MRC 就能工作。
这意味着 MRC 可以与非对称拓扑(如 ZCube)组合,而且有天然优势。
ECMP 要求对称,源路由不需要
传统 RoCEv2 + ECMP 的组合隐含了一个约束:多条路径必须"等价",才能用哈希均匀分配。对称拓扑(如传统 Fat-Tree)天然满足这个条件,但非对称拓扑(如 ZCube 首尾层 2n 端口 vs 中间层 3n 端口)的路径数量和带宽可能不等。
MRC 的 SRv6 源路由绕开了这个约束:路径不是被"分配"的,而是被"编码"的。NIC 知道每条路径的完整信息(带宽、延迟、当前状态),可以在包级别做精确调度——不需要路径"等价"。
短路径放大包喷射的效果
MRC 的包喷射在短路径上效果更好:路径越短,包到达接收端的时间窗口越窄,乱序程度越低,NIC 端的 reorder buffer 和 SACK 逻辑越简单。ZCube 的 2 跳直径(vs 三层 Clos 的 5-7 跳)在这个维度上是最优配合。
路径多样性要求 k≥2
MRC 的 EV 包喷射需要每流至少 2 条独立路径才能发挥作用(1 条路径 = 无需包喷射)。ZCube 的 k=2 配置(每个 GPU 2 个 NIC 端口连 2 个不同交换机)恰好提供最小可工作配置。k=3 或更高时,MRC 的路径多样性更充分,但硬件成本也更高——这是一个拓扑-协议联合优化的问题,目前 ATOP 的搜索空间还没有把 MRC 的包喷射效率纳入目标函数。
未探索的联合优化空间
ZCube + MRC 的组合打开了一个未被探索的优化空间:如果 ATOP 在搜索拓扑时同时考虑 MRC 的 EV 状态机参数(路径数量、EV 集合大小、故障检测阈值),能否找到比独立优化更好的拓扑-协议联合解?这是当前研究中明确的空白。
→ 拓扑演进的完整分析见姊妹篇之一「从 CLOS 到 ZCube」。
判断
MRC 会成为 AI 集群网络的标准吗?
大概率会,但不是短期。
有利的因素:
- OpenAI 已经在生产环境跑了 131K GPU,有真实数据
- NVIDIA、AMD、Broadcom 三家 NIC 巨头同时支持--生态覆盖面足够
- 交换机侧的增量成本几乎为零(甚至净减),部署阻力小
- O(N) 的 scaling 特性让超大规模集群的网络管理从噩梦变成线性增长
需要观察的:
- MRC 目前只有 OpenAI 一家在生产环境验证。需要更多大规模部署案例
- SRv6 uSID 的管理平面(路径计算、uSID 分配)复杂度不低,需要成熟的编排工具
- 标准 RoCEv2 + 精细调优在中小规模集群里仍然够用,MRC 的优势要到多大集群才不可替代?
对网络芯片产业的影响
NIC 厂商:MRC 让 NIC 的复杂度和 die cost 增加了 20-30%。这对 NVIDIA 和 Broadcom 来说是可接受的(它们已经在高端 NIC 市场有利润空间),对后来的进入者意味着更高的技术门槛和投入。
交换机厂商:短期影响小(MRC 甚至简化了交换机)。长期影响在于:当 NIC 承担了越来越多的网络智能,交换机是否会被进一步“管道化”?如果网络智能都集中在 NIC,交换机只需要做无状态线速转发,那它的价值增值空间在哪?
从 RoCEv2 迁移到 MRC:需要换什么
读者最关心的问题:如果我现在用 RoCEv2,怎么迁移到 MRC?
必须换的:
- NIC:必须换或升级为支持 MRC 的 NIC(ConnectX-8 / Thor Ultra / Pollara)。传统 RoCE NIC 没有 EV 状态机和 OOO write engine,无法通过固件升级支持 MRC
- 交换机固件:需要支持 SRv6 uSID 线速转发。好消息是大多数现代交换机芯片(Tomahawk 5+、Silicon One G200+)硬件已支持,只需要固件更新
可以保留的:
- 交换机硬件:不需要换。MRC 甚至简化了交换机(减法 > 加法)
- 光模块/线缆:完全复用
- 物理布线:不需要重新布线(但多平面拓扑需要重新规划逻辑连接)
- 应用软件:MRC 兼容 RDMA Verbs API(Write + WriteImm 子集),应用层代码可能不需要改
迁移路径建议:
- 先确认交换机是否支持 SRv6 uSID(查看芯片规格和固件版本)
- 采购 MRC NIC 替换现有 NIC
- 更新交换机固件启用 uSID 转发
- 在小规模测试集群上验证 MRC 功能和性能
- 逐步推广到生产集群
注意:多平面拓扑是 MRC 的推荐拓扑,但不是必须的。可以在现有 Clos 拓扑上先启用 MRC(利用其多路径和快速故障恢复),后续再考虑多平面拓扑优化。
声明: 本文基于 arXiv 论文 2605.04333(OpenAI MRC 协议规范)、OpenAI 官方博客、NVIDIA/AMD/Broadcom 厂商博客、以及 Edgecore/STORDIS 等产品资料进行交叉验证后撰写。不构成投资建议。文中数据截至 2026 年 6 月 1 日。