2026年5月,三件事几乎同时发生:AMD Venice 搭载台积电2nm启动量产,成为全球首款2nm HPC处理器;NVIDIA Vera CPU 首批交付 OpenAI 和 Anthropic,88核自研Arm核心,性能测试宣称"前所未见";英特尔透露 AI 集群中 CPU:GPU 配比正从 1:8 向 1:4 甚至 1:1 演进。与此同时,花旗预测 2030 年服务器 CPU 市场将达 1320 亿美元,其中"Agentic CPU"这一新品类以 185% 的年复合增速飙涨。
过去三年,所有人的目光都盯在 GPU 上。CPU 在 AI 服务器里只是"喂 GPU 的人"。但现在,CPU 正从配角变成瓶颈。
一、为什么 AI 推理需要这么多 CPU
训练和推理对 CPU 的需求完全不同。
训练阶段,GPU 负责几乎所有的重计算——大矩阵乘法、梯度反传、参数更新。CPU 的工作很简单:解压数据、分词、批处理调度、把数据喂给 GPU。这时候 GPU:CPU 配比可以到 8:1 甚至更高,CPU 12% 的数据中心算力预算就够了。
推理阶段,尤其是 Agent 推理,事情变了。
一个 Agent 请求不是一次模型调用,而是一整套工作流:检索上下文、调用工具(搜索、数据库、API)、路由到不同模型、评估中间结果、维护长上下文状态、再决定下一步。GPU 负责模型前向计算,但任务编排、线程调度、进程管理、沙箱执行、KV Cache 管理、采样和 guardrails 处理——这些全是 CPU 的活。
SemiAnalysis 首席分析师 Dylan Patel 的判断很直接:AI 工作负载正从简单文本生成向复杂智能体和强化学习演进,CPU 正面临"极其严重的产能短缺"。有研究表明,在 Agent 工作负载中 CPU 开销占比最高可达 90.6%,GPU 反而经常处于等待状态。
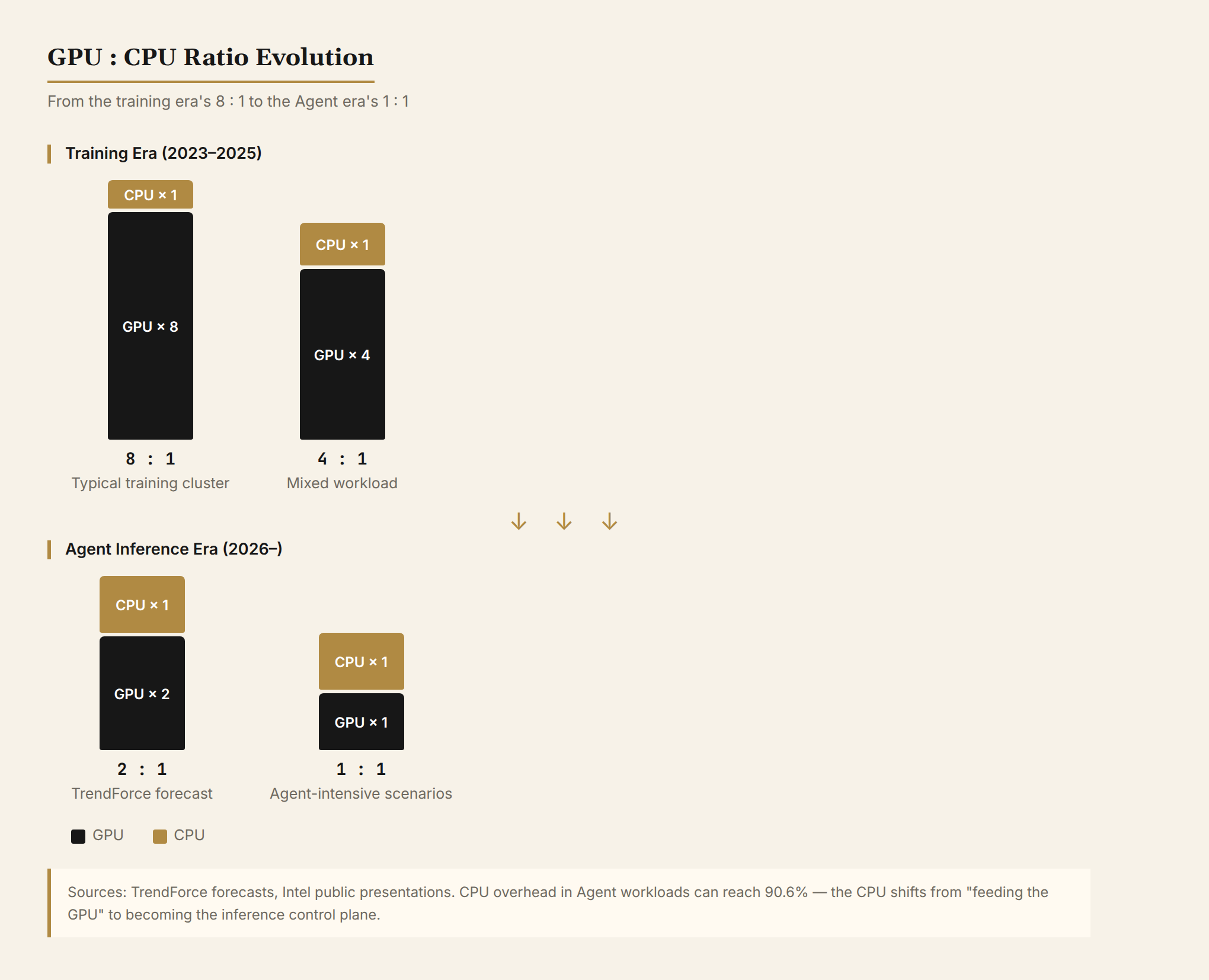
结果:配比从训练时代的 1:8(1颗CPU配8颗GPU)快速向 1:4、1:2 甚至 1:1 演进。TrendForce 预测 Agent 时代这个比例会到 1:1 到 1:2。英特尔自己也说,AI 训练阶段 GPU:CPU 是 8:1,现在降到 4:1,未来可能 1:1 甚至反转。
CPU 不只是"喂 GPU 的人"了。它是 AI 推理的控制平面。
二、三巨头的 CPU 新牌
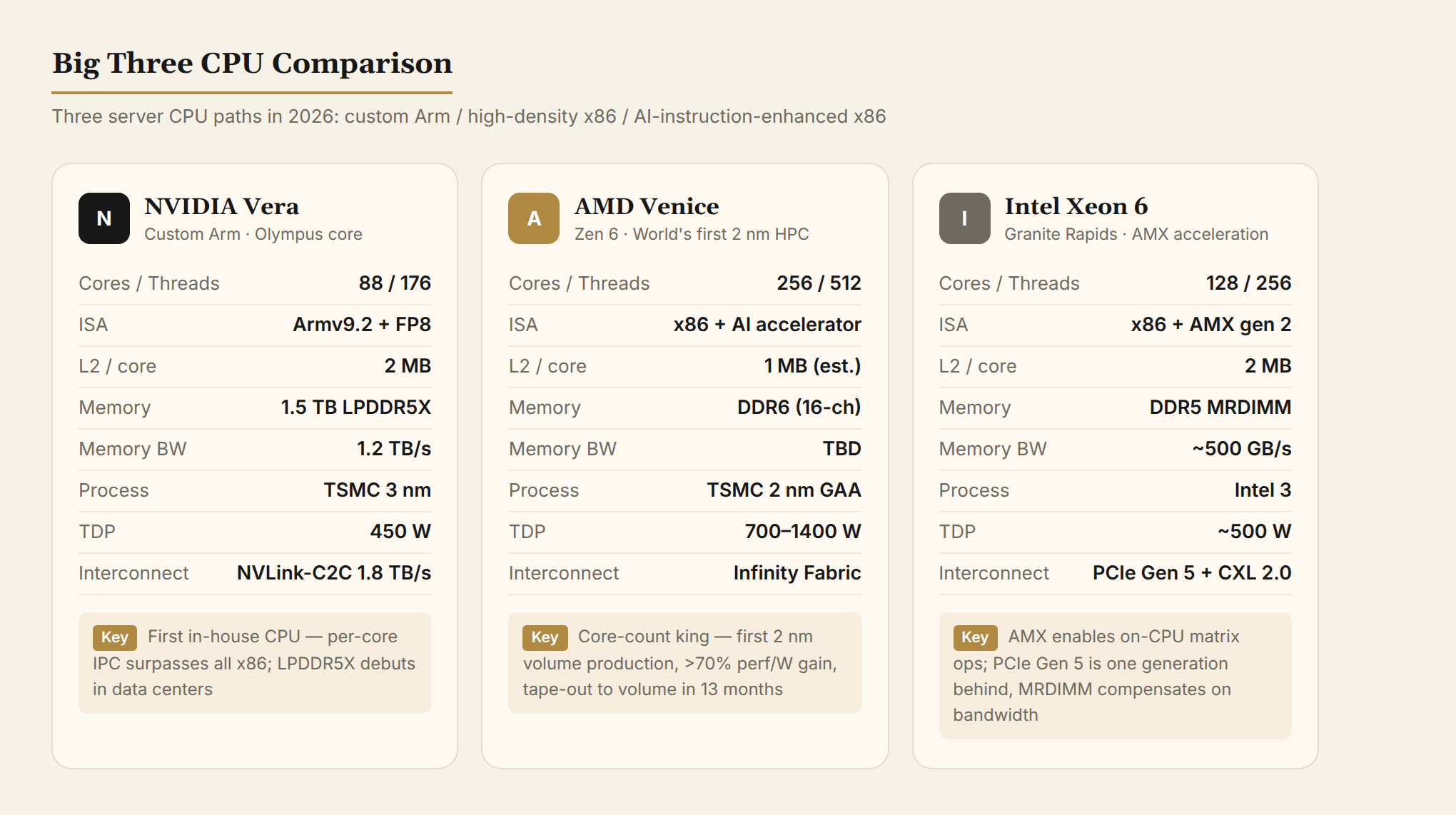
NVIDIA Vera:从 GPU 公司变成 CPU+GPU 双寡头
Vera 是 NVIDIA 第一颗"真正自研"的 CPU。前代 Grace 用的是 Arm 公版 Neoverse V2 核心,Vera 换成了 NVIDIA 自研的 Olympus 核心——NVIDIA 不再拿别人的底子做优化,而是从架构开始重新设计。
核心规格:
- 88 个 Olympus 核心,176 线程(空间多线程,类似 SMT 但不共享 ALU)
- Armv9.2 指令集,支持 FP8(8位浮点,AI 推理专用精度)
- 每核 2MB L2 缓存(Grace 的两倍),164MB 统一 L3
- 1.5TB LPDDR5X 系统内存,1.2TB/s 内存带宽
- NVLink-C2C(NVIDIA 自研芯片间互联协议)带宽 1.8TB/s
- PCIe Gen 6 + CXL 3.1(Compute Express Link,允许 CPU 和设备共享内存池的协议)
- TDP 450W,台积电 3nm
一个值得注意的选型:Vera 是全球首款在数据中心用 LPDDR5X 的 CPU。传统服务器 CPU 用 DDR5 或 HBM(High Bandwidth Memory,GPU 常用的堆叠内存),LPDDR5X 以前只出现在手机和轻薄本。NVIDIA 选它的理由是能效——LPDDR5X 高带宽低功耗,每瓦性能行业领先。代价是单颗 CPU 消耗大量 LPDDR5X 颗粒,大规模出货可能拉紧供应链。
首批客户已交付:OpenAI、Anthropic、CoreWeave、Meta、Oracle。Vera 有两种交付形态——独立 LPX 服务器和 Vera Rubin NVL72 机架的主机 CPU。NVIDIA CFO 说 CPU 业务(独立 CPU + 超级芯片内置 CPU)要吃 200 亿美元。
Phoronix 首批基准测试(2026年5月26日):
测试由 Phoronix 的 Michael Larabel 在 NVIDIA 圣克拉拉总部完成,覆盖代码编译、Python 性能、OpenJDK Java、AV1 视频编码、7-Zip 压缩、LuaJIT、ClickHouse 数据库、Renaissance JVM 等企业级负载。
| 对比项 | 结果 |
|---|---|
| vs 72核 Grace(前代) | 综合几何平均快 63% |
| vs AMD EPYC 9575F(64核 Zen 5,5GHz) | 综合几何平均快 10% |
| vs Intel Xeon 6980P(128核 Granite Rapids) | 综合几何平均快 55% |
| 7-Zip 单核 | 比所有 x86 芯片高 ~20% |
| Linux 内核编译 | 比 x86 处理器快 2倍(NVIDIA 官方数据) |
| vs 所有 ARM 服务器芯片 | "轻松超越" Ampere、Google Axion、Microsoft Cobalt |
关键细节:Larabel 评价 Vera "展现出的与 Intel/AMD x86_64 的竞争力,是我在任何其他 ARM 或非 x86_64 处理器上从未见过的"。不过测试范围由 NVIDIA 指定,不代表全场景表现。功耗数据未开放监测。Phoronix 尚未公布每瓦效能数据。
更重要的是单核表现。过去 ARM 服务器芯片靠堆核数拉总分,单核始终是短板。Vera 在单线程编译中只有 EPYC 9575F 能压过它,Linux 内核构建甚至反超排到第一。从"靠核数堆分"到"单核也能掰手腕",这是 ARM 服务器芯片的标志性转变。
Olympus 怎么做到单核 IPC 这么强?
NVIDIA 没有公开 Olympus 的微架构白皮书,但从规格、行业规律和 NVIDIA 的技术积累可以拆出几个关键因素:
1. 自研 vs 公版的根本差异。 Grace 用的是 Arm 公版 Neoverse V2 核心——Arm 设计的通用方案,要在所有客户的需求之间做平衡。Olympus 是 NVIDIA 从零设计的,只服务一个场景:AI 数据中心。这意味着 NVIDIA 可以针对 AI 工作负载的特征(长上下文、高频工具调用、状态管理)做激进的架构取舍,不需要兼顾通用性。
2. 超大 L2 缓存。 每个 Olympus 核心配 2MB L2,是 Grace(1MB)的两倍,也远超典型服务器核心(Zen 5 是 1MB,至强是 2MB 但核心数少)。L2 越大,cache miss 越少,IPC 上限越高。编译类负载对 L2 命中率特别敏感——这解释了为什么 Vera 在 Linux 内核构建中表现突出。
3. 1.2TB/s 内存带宽消除瓶颈。 IPC 不只看计算能力——如果数据供不上,再宽的执行单元也是空转。LPDDR5X 1.2TB/s 的带宽让 cache miss 的惩罚从数百周期缩短到几十周期。对比:Zen 5 的 DDR5 典型带宽约 460GB/s,Vera 的内存带宽是它的 2.6 倍。
4. 可能采用更宽的解码/执行引擎。 Arm 公版 Neoverse V2 是 4-wide 解码。苹果自研 M 系列做到了 8-wide,单核 IPC 冠绝行业。NVIDIA 有同样动机走宽解码路线——自研架构不需要兼容 Arm 公版核心面积的约束。7-Zip 单核比 x86 高 20%,暗示执行端宽度或指令融合策略有优势。
5. 十二年的自研 CPU 经验。 Olympus 不是 NVIDIA 第一次做 CPU。2014 年 Tegra K1 里的 Denver 核心采用 VLIW + 动态二进制优化——用软件优化流水线排布来压 IPC。Denver 在当时的移动场景里单核性能碾压同期 Cortex-A15。虽然 Olympus 大概率不是 VLIW(服务器场景的软件多样性不适合 VLIW),但 NVIDIA 在微架构设计和验证上的方法论已经积累了 12 年。
6. 3nm 工艺。 更高的晶体管密度意味着 NVIDIA 可以把更多晶体管花在分支预测器、预取器、重排缓冲区(ROB)等 IPC 关键模块上,而不需要担心面积和功耗超限。
简言之:Olympus 的单核优势不是某一项黑科技,而是自研架构带来的系统性红利——更大的缓存、更宽的执行引擎、更快的内存、更自由的微架构取舍。这是苹果路线在服务器 CPU 上的第一次成功复现。
AMD Venice:全球首款 2nm HPC 处理器
2026 年 5 月 21 日,AMD 宣布第六代 EPYC "Venice" 启动量产爬坡。这是全球首颗上台积电 N2(2nm)工艺的高性能计算 CPU,也是 Zen 6 架构的首秀。
核心规格:
- Zen 6 架构,96 核标准版 + 256 核高密度版(512 线程)
- 相比上代 Turin(Zen 5):性能和能效提升超 70%,线程密度提升超 30%
- 支持 PCIe Gen 6、DDR6(注意是 DDR6 不是 DDR5)
- TDP 700-1400W,首次进入千瓦级功耗
- 2025 年 4 月流片,13 个月转量产
256 核 512 线程是什么概念?现役 Turin 最高 192 核 384 线程,Venice 直接拉到 256 核。对于 Agent 推理这种"多智能体并发、每个智能体独立执行工作流"的场景,核心数就是并发能力。
苏姿丰把服务器 CPU 的长期 TAM 预测从 600 亿翻倍到 1200 亿以上。花旗给得更激进——1315 亿。
后续路线图:Venice 之后还有 "Verano",专门针对 AI Agent 负载优化,强化 LPDDR 内存集成和能效。
英特尔 Granite Rapids:守住 x86 阵地
英特尔在 CPU 上走了不同的路——不追核心数极限(至强 6 最高 128 核),但在 AI 加速指令集上投入最大。
核心动作:
- 至强 6(Granite Rapids)内置 AMX(Advanced Matrix Extensions,Intel 在 x86 中加入的矩阵运算硬件加速器),直接在 CPU 上做 INT8/BF16 矩阵运算
- AMX 从 Sapphire Rapids 引入,到 Granite Rapids 是第二代:TMUL(Tile Matrix Multiply Unit)单元可做 8×8 tile 矩阵乘加
- 128 核 + 144MB L3 + DDR5-6400(MRDIMM 可达 8800 MT/s)+ CXL 2.0
- PCIe Gen 5(落后一代),但内存带宽通过 MRDIMM(Multiplexed RDIMM,一条内存条上多路复用带宽)补到约 500GB/s
- TDX(Trusted Domain Extensions,英特尔机密计算指令集)支持
英特尔的逻辑:GPU 做不了的事——工具调用、状态管理、数据编排——CPU 要尽量做得更快。AMX 让 CPU 在不需要 GPU 的场景(小批量推理、预处理、后处理)也能跑矩阵运算,省掉 GPU 调度的开销。
三、CPU 技术的三个快速推进方向
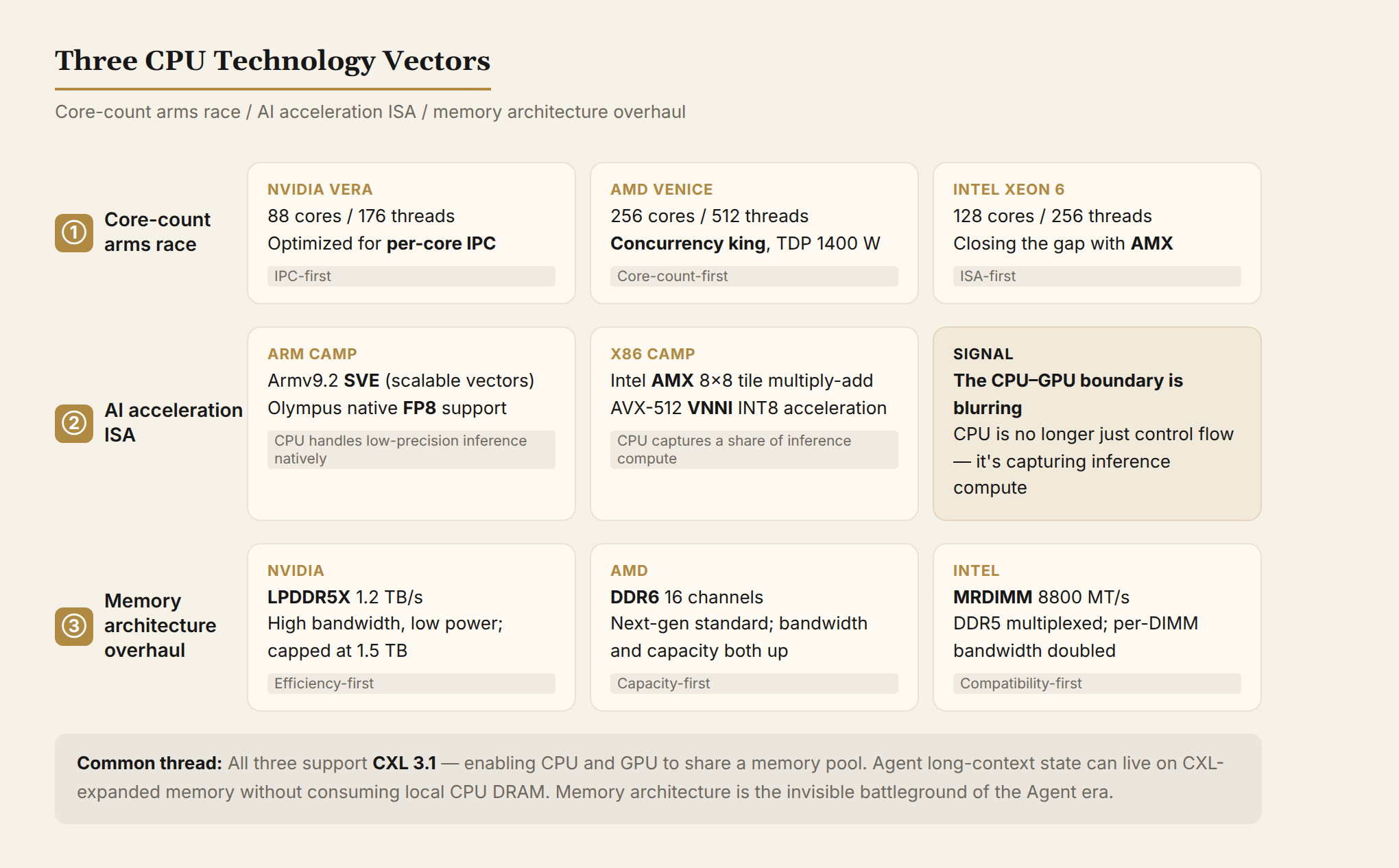
1. 核数军备竞赛:从 64 核到 256 核
Agent 推理是天然的并发场景。一个用户请求可能拆成多个子任务,每个子任务又是独立的工具调用链。这意味着 CPU 需要同时管理几十到上百个执行上下文。
三家的应对:
- AMD Venice:256 核 512 线程,芯片级并发之王
- NVIDIA Vera:88 核 176 线程,走单核性能+能效路线
- 英特尔至强 6:128 核,AI 指令集弥补核心数差距
核数不是越多越好。256 核意味着芯片面积大、功耗高(Venice TDP 高达 1400W)、散热压力陡增。但对于"CPU 瓶颈"的 Agent 场景,多核并发是刚需。
2. AI 加速指令集:CPU 也在做张量计算
CPU 不只是"通用处理器"了。三家都在给 CPU 加 AI 加速单元:
x86 阵营(Intel/AMD):
- Intel AMX:硬件级 tile 矩阵乘加,INT8 推理吞吐量较纯 AVX-512 提升 4 倍
- AMD Zen 6 引入类似 AI 加速单元(细节待 Computex 披露)
- AVX-512 VNNI(Vector Neural Network Instructions,面向 INT8 推理的向量指令集):每条指令完成 64 个 INT8 乘加
Arm 阵营(NVIDIA/自研/云厂商):
- Armv9.2 SVE(Scalable Vector Extension,可变长度向量指令,宽度从 128 位到 2048 位)
- NVIDIA Olympus 支持 FP8(8位浮点精度):CPU 核心直接做低精度浮点运算
- AWS Graviton、Google Axion 等云厂商自研 Arm CPU 也在加 AI 加速
信号:CPU 和 GPU 的边界在模糊。CPU 不只做控制流了,它也在抢一部分推理算力——尤其是低延迟、小批量的场景。
3. 内存架构大改:LPDDR5X、MRDIMM、CXL
Agent 推理有两个内存特征:长上下文(KV Cache 可能到十几 GB)和高频随机访问(状态管理、工具调用)。
- NVIDIA Vera 选 LPDDR5X:高带宽(1.2TB/s)+ 低功耗,但容量受限(1.5TB)
- AMD Venice 支持 DDR6:DDR6 内存标准(带宽和容量较 DDR5 同步提升)
- Intel 至强 6 支持 MRDIMM:多路复用 DDR5,单条带宽翻倍到 8800 MT/s
- CXL 3.1:三家都支持。CXL(Compute Express Link)允许 CPU 和 GPU 共享内存池,Agent 的长上下文状态可以放在 CXL 扩展内存上,不占 CPU 本地内存
内存架构是 Agent 时代的隐形战场。谁能更快地读写状态、谁能更高效地管理上下文,谁就更适合做 Agent 控制平面。
四、x86 vs Arm:谁在接增量?
美银证券的判断值得注意:到 2030 年,服务器 CPU 价值份额中,Intel 和 AMD 各占约 28%,Arm 商用 CPU 约 7%,Arm 定制/ASIC 约 37%。
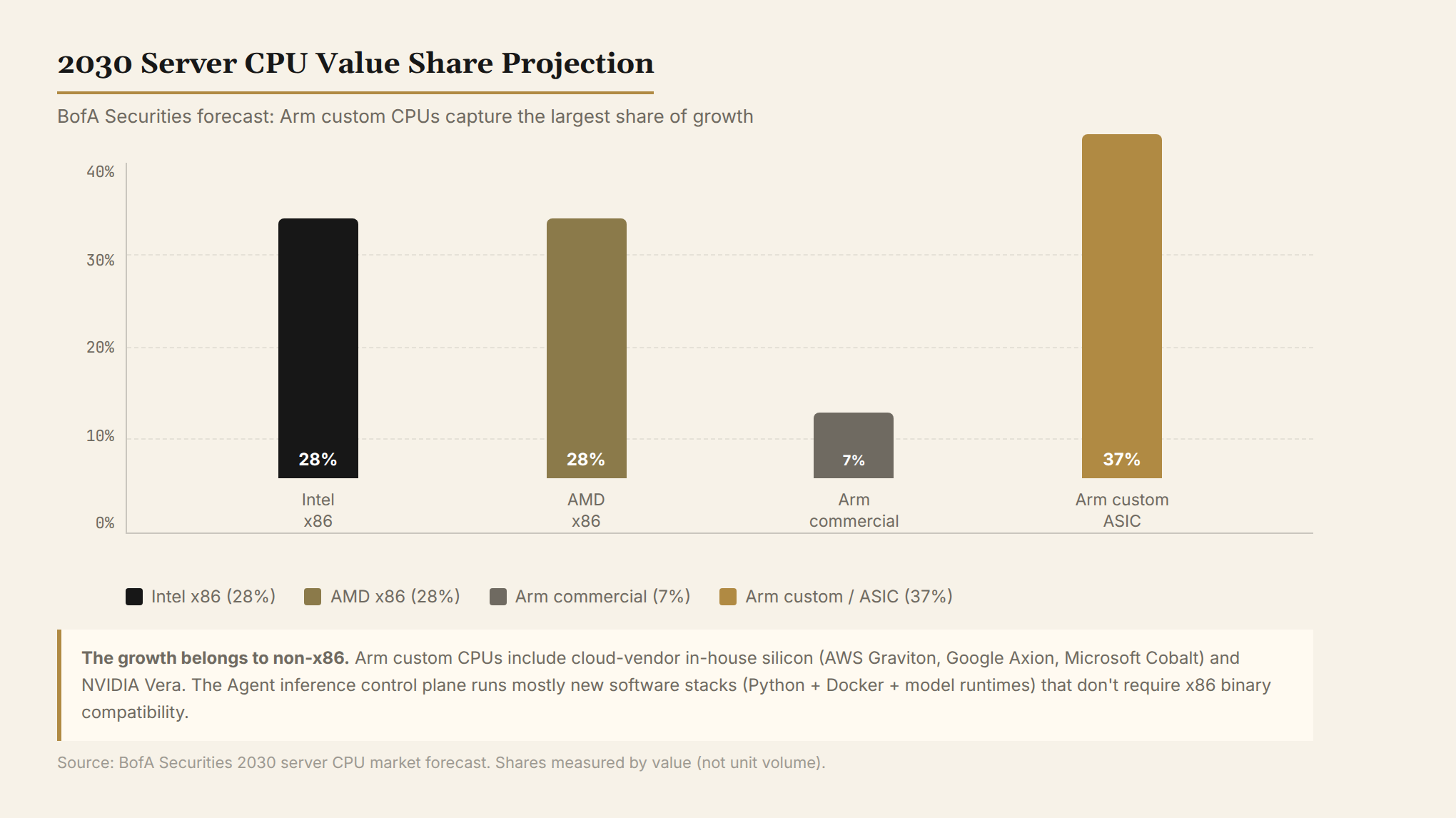
增量不在 x86 手里。
Arm 定制 CPU 指的是云厂商自研(AWS Graviton、Google Axion、Microsoft Cobalt)和 NVIDIA Vera。这些芯片不走 x86 兼容路线,而是为特定工作负载(Agent 编排、推理控制平面)从头设计。
对 Intel 和 AMD 来说,这不是好消息。x86 的护城河是生态兼容性——几十年积累的软件栈。但 Agent 推理的控制平面软件大多是新的:Python 运行时、容器沙箱、KV Cache 管理、工具调用框架——这些不需要 x86 二进制兼容。Arm 能跑,而且往往更省电。
AMD 在 x86 里是最强的一方(Zen 架构能效持续领先),但增量市场里 Arm 定制 CPU 吃得更快。NVIDIA 则因为 Vera + 全栈 CUDA 生态,既吃 GPU 预算又吃 CPU 预算。
五、中国 CPU 格局:四条路线,谁在吃到 Agent 红利
2025 年,中国 PC 与服务器 CPU 国产化率首次突破 20%,2026 年 Q1 已冲到 25%。政务云国产化率 94.7%,金融和电信超过 30%,连最难啃的服务器市场也从两年前的 10% 飙升到了 25%。
这不是政策驱动的数字游戏——2026 年 Q1 海光在手订单 128 亿元排产到三季度,龙芯 3A6000 出货破百万片,飞腾服务器 CPU 出货同比增 60%。国产 CPU 正从"能用"走向"好用"。
x86 兼容路线:海光领衔
海光信息是目前国产商用服务器 CPU 的绝对龙头。通过 AMD Zen 架构永久授权,海光 5000(7nm)/6000(5nm)性能接近国际主流,x86 生态 100% 兼容,客户迁移成本几乎为零。2025 年营收 143.77 亿元,2026 Q1 营收 40.34 亿元(同比+68%),在手订单 128 亿元。国产 x86 CPU 市占约 28%-30%。
海光的优势是"借船出海"——最快路径拿到高性能产品。短板也明显:依赖 AMD 授权,自主可控性受限;CPU TDP 250W,功耗偏高;没有移动 CPU 布局。更关键的是,AMD 授权的海光是 Zen 3 架构,与 AMD 当前的 Zen 5/Zen 6 已有两代差距,未来授权升级存在不确定性。
兆芯走差异化路线——x86 授权中 Windows 兼容性最好的玩家,主打商业办公和教育市场。下半年发布的 KX-8000 主频将逼近 4GHz。兆芯的定位更像"信创桌面 CPU 的性价比之选",不追高性能服务器。
ARM 路线:鲲鹏 + 飞腾分治
华为鲲鹏的核心竞争力不是芯片本身,而是全栈生态闭环——芯片 + 欧拉 OS + 高斯数据库 + 华为云,光合组织合作企业超 5000 家。在金融和电信信创市场,鲲鹏市占率超 50%。鲲鹏 950 已发布,96 核/192 核版本专门针对 AI 大模型和超算优化。
鲲鹏在 ARM 服务器 CPU 方面是国产第一梯队,但鲲鹏 920 到 950 的迭代速度(四年一代)远慢于国际同行——AMD EPYC 是两年一代。高端型号鲲鹏 950-96 预计 2026Q4 量产,当前高端市场竞争力仍不足。
飞腾是 ARM 信创出货冠军——累计销量破 1300 万片,政务办公首选。D3000(桌面)功耗仅 18W,腾云 S5000C(64核服务器)已进入头部云厂商供应链。但飞腾的制程停留在 14nm,与台积电 2nm/3nm 差距明显,高端性能有上限。
自主指令集路线:龙芯的生态拐点
龙芯中科是中国唯一全栈自研 CPU 企业——LoongArch 指令集 100% 自研,无海外授权依赖。3A6000 桌面 CPU SPEC CPU2006 单线程定点 51 分,日常办公已有较好流畅度。3C6000 服务器 CPU 16-64 核正在推进。
2026 年 5 月,龙芯 3A6000 出货量突破 100 万片——这不是一个销售数字,而是跨过"生态拐点"的标志。龙芯浏览器和二进制翻译技术让原有 x86 应用可以在 LoongArch 上运行,已适配 2 万+ 软件,覆盖税务、教育、党政等核心场景。2026 Q1 订单超 82 亿元,全年预计扭亏。
龙芯的定位是安全可控等级最高的路线——党政军、涉密领域的首选。短板是性能仍有差距(单核性能约为 Intel 同代的 60%-70%),生态迁移需要额外适配成本。
申威走 SW-64 完全自主架构,定位军工/超算专用,自主可控等级最高,但不参与商用市场竞争。
RISC-V:开源免费的新变量
RISC-V 是唯一不需要向任何国外公司交授权费的 CPU 指令集。对中国 CPU 产业来说,它的战略价值在于"永不担心被断供"。
阿里平头哥的玄铁系列是 RISC-V 阵营的代表。2026 年 5 月,玄铁 9 系列全球首次成功适配 Android 16 系统,通过 6.8 万余项核心测试——这意味着 RISC-V 芯片正式进入主流消费电子生态。进迭时空 K3 芯片适配鸿蒙 6.1,中科院发布"如意"原生系统,RISC-V 的软硬件生态正在快速打通。
但 RISC-V 目前主要覆盖嵌入式和端侧场景,服务器级高性能 CPU 还处于早期。芯来科技、算能等厂商在推进 RISC-V 服务器芯片,但性能和生态与 x86/Arm 还有显著差距。集微网判断 RISC-V 的"黄金契机"来自 CPU 超级周期,但要在服务器市场形成真正竞争力,可能还需要 3-5 年。
四条路线的份额和趋势
| 路线 | 代表厂商 | 2026 市占(国产内部) | 优势 | 短板 |
|---|---|---|---|---|
| x86 兼容 | 海光、兆芯 | ~35% | 生态无缝迁移,商用首选 | 授权依赖,自主性受限 |
| ARM | 鲲鹏、飞腾 | ~40% | 低功耗,信创出货量大 | 制程差距(14nm),高端竞争力不足 |
| 自主指令集 | 龙芯、申威 | ~20% | 完全自主,涉密首选 | 性能差距,生态迁移成本 |
| RISC-V | 玄铁、芯来、算能 | ~5% | 开源免费,不被断供 | 服务器场景不成熟,生态早期 |
整机厂商:谁在帮国产 CPU 落地
国产 CPU 能出货,离不开整机厂商的适配和集成。整机厂商是 CPU 进入客户机房的最后一公里。
IDC 2025 年数据,中国 x86 服务器整机厂商份额:
| 厂商 | 2025 市占 | 同比变化 | 定位 |
|---|---|---|---|
| 浪潮信息 | 31.3% | ↑(2024年 27.8%) | 第一,AI 服务器龙头,存储业务中国前二 |
| 超聚变 | 12.7%(x86 口径) | ↑ | 第二,国产化服务器销售额第一,液冷服务器连续四年第一 |
| 新华三(紫光) | 12.5% | — | 第三,AI 算力基建营收同比+45% |
| 联想 | 10.7% | — | 第四,AI 服务器收入同比+50%,ISG 全年盈利 |
| 中兴 | 8.5% | — | 第五,运营商市场强势 |
| 华为(鲲鹏服务器) | 不在 x86 口径内 | — | ARM 服务器,运营商集采 ARM 占比 65% |
值得关注的几个信号:
超聚变的崛起是这轮最戏剧化的故事。华为 2021 年把 x86 服务器业务剥离给河南国资,五年内营收从 100 亿飙到 582 亿(2025 年),2026 年 5 月申报创业板 IPO,估值最高 800 亿。超聚变是昇腾生态最高等级伙伴,昇腾出货金额和出货量排名第一——这意味着它吃到的不只是通用服务器红利,还有 AI 加速器国产替代的红利。液冷服务器连续四年第一,累计部署超 10 万个液冷节点,是头部互联网客户超节点液冷整机首选。
联想 ISG 的转折点来了。基础设施方案业务集团(ISG)全年营收超 1360 亿元,同比+32%,首次全年盈利。AI 服务器收入同比+50%,订单储备超 1400 亿元。联想董事长杨元庆判断"未来 GPU 服务器 70% 用于推理,30% 用于训练"——如果这个判断成立,Agent 推理对 CPU 密集型整机的需求还会继续放大。
浪潮信息虽然仍是第一(31.3%),但增速主要来自 AI 服务器和存储。2026 Q1 净利润 6.05 亿元,同比+30.7%。浪潮是海光 x86 CPU 最大的整机适配方之一,海光在浪潮平台的出货量占海光总出货的相当比例。
整机厂商的格局意味着:国产 CPU 的出货不只是在实验室里跑分,而是已经通过整机厂商进入了运营商、金融、互联网头部客户的机房。超聚变 2025 年 582 亿营收、1 万多家客户的体量,说明国产 CPU 服务器已经从"能用"走向了"规模化采购"。
趋势判断:
-
x86 兼容路线短期最强,长期受限于授权。 海光吃到了这波 Agent CPU 红利的主力——x86 生态兼容性让客户迁移成本最低。但 AMD 授权版本落后两代,且未来升级有不确定性。
-
ARM 路线增量最大。 运营商集采 ARM 架构服务器占比已达 65%。鲲鹏 950 在 AI 场景的优化如果能赶上 Agent 推理浪潮,有机会在国产 AI 集群里占住核心位置。
-
龙芯的"百万片出货"是标志性事件。 它证明了完全自主 CPU 可以从政策驱动走向市场驱动。如果 LoongArch 在 Agent 框架上跑通(Python + Docker + 推理引擎),进入门槛比传统企业级低得多。
-
RISC-V 是 3-5 年后的变量。 玄铁适配 Android 是生态破局的关键一步。但服务器市场需要高性能核心、成熟的操作系统支持、完整的开发工具链——这些 RISC-V 还在建设中。
六、判断
-
CPU 的"超级周期"是真实的,不是概念炒作。 GPU:CPU 配比从 8:1 向 1:1 演进,意味着 CPU 需求量增长 4-8 倍。这不是 GPU 被替代,而是 Agent 推理引入了全新的 CPU 密集型工作负载。
-
NVIDIA 是这轮最大的赢家。 它不只卖 GPU,还卖 Vera CPU,甚至单独卖 CPU 机架。从"GPU 公司"变成"AI 基础设施公司",CPU 是关键拼图。
-
x86 不会死,但增量被 Arm 吃掉。 Intel 和 AMD 还能守住存量(企业级、数据库、传统云),但 Agent 推理这个新方向的 CPU 预算,大部分会流向 Arm 定制芯片。
-
AMX/FP8 等 AI 加速指令是 CPU 的"第二曲线"。 CPU 不只做通用计算了,它在抢一部分推理算力。这让 CPU 和 GPU 的边界进一步模糊。
-
中国 CPU 的进入门槛比想象中低。 Agent 软件栈是新的,x86 兼容不是硬约束。制程差距是长期挑战,但在 Agent 场景下,架构优化(核心数、内存带宽、指令集)可以部分弥补制程劣势。
数据截止:2026年5月28日。国际部分技术参数来自 AMD 官方公告、NVIDIA GTC 2026 发布、GF证券/花旗/美银证券研报、SemiAnalysis 分析,以及 Phoronix 的 Vera 早期基准测试。国内数据来自 IDC 中国服务器市场报告、各公司财报及公告、集微网分析。部分规格(Zen 6 AI 加速单元细节、DDR6 参数)需等 Computex 2026 正式披露。