悬念:为什么 NVL72 的铜缆在两年内就被判了死刑?
本文基于截至 2026 年 5 月 19 日的公开信息撰写。数据来源标注:[官方]=NVIDIA 发布;[推算]=基于公开参数计算;[第三方]=媒体/研报。明天 NVIDIA Q1 财报可能带来修正。
本文基于截至 2026 年 5 月 19 日的公开信息撰写。数据来源标注:[官方]=NVIDIA 发布;[推算]=基于公开参数计算;[第三方]=媒体/研报。明天 NVIDIA Q1 财报可能带来修正。
悬念:为什么 NVL72 的铜缆在两年内就被判了死刑?
2024 年 3 月,NVIDIA 发布 GB200 NVL72,黄仁勋称之为"把 72 颗 GPU 变成一个巨型 GPU"。这个机柜内含 5000 根铜缆,总重 1.4 吨,双向带宽 130 TB/s。SerDes 速率 200G,5000 根铜缆编织出一个庞大的 GPU 间通信脊柱。
但仅仅两年后,Rubin Ultra NVL576 彻底抛弃了铜缆,改用 78 层 PCB 正交背板。Cable Tray——那个被黄仁勋自豪展示的铜缆脊柱——完全消失了。
这不是"换线"。背后是 AI 算力需求指数级增长与铜缆物理极限之间不可调和的矛盾。从 NVL72 到 NVL576,物理形态、互联拓扑、芯片架构、散热方案、软件栈同步重构。理解这个脉络,才能看清 NVIDIA 为什么砍掉 Rubin CPX、收购 Groq、跳过 NVL144——以及为什么"30倍推理提升"实际上还保守了。
本文要回答的问题:
- 从 NVL72 到 NVL576,物理形态到底变了什么?为什么必须变?
- NVLink 5→6,互联架构有什么根本性变化?
- GPU、CPU、LPU 三类芯片如何在超节点中分工?工程约束是什么?
- 软件栈如何释放硬件性能?Dynamo 为什么是"AI 工厂的操作系统"?
- 实测数据如何演进?从 H100 到 GB300 NVL72,推理性能到底提升了几倍?
- 铜缆为什么被淘汰?正交背板解决了什么,引入了什么新问题?
- NVL144 为什么被跳过?对产品节奏意味着什么?
一、四代超节点总览
| 维度 | GB200 NVL72 | GB300 NVL72 | Vera Rubin NVL72 | Rubin Ultra NVL576 |
|---|---|---|---|---|
| 发布 | 2024.03 | 2025.07 | 2026.01/03 | 2027H2(计划) |
| GPU | Blackwell 2-Die | Blackwell Ultra 2-Die | Rubin 2-Die N3P | Rubin Ultra 2+2模块化 N3P |
| GPU Die数 | 72 | 72 | 72 | 576 |
| CPU | Grace 72核 | Grace 72核 | Vera 88核 Arm v9.2 | Vera 同左 |
| HBM | 192GB HBM3e | 288GB HBM3e | 288GB HBM4 | 1TB HBM4e |
| HBM带宽/封装 | 8 TB/s | 8 TB/s | 22 TB/s | ~32 TB/s[推算] |
| FP4推理 | 720 PFLOPS | 1,080 PFLOPS | 3.6 EFLOPS | 15 EFLOPS |
| FP8训练 | ~360 PFLOPS[推算] | ~540 PFLOPS[推算] | 2.5 EFLOPS | 5 EFLOPS |
| NVLink | 5th, 1.8TB/s/GPU | 5th, 1.8TB/s | 6th, 3.6TB/s | 6th, 3.6TB/s |
| 机架NVLink | 130 TB/s | 130 TB/s | 260 TB/s | 1.5 PB/s |
| 互联介质 | 铜缆Cable Tray | 铜缆Cable Tray | 无缆模块化(铜走线) | PCB正交背板 |
| 单GPU功耗 | ~1000W | ~1400W | ~2000W | ~2000W+[推算] |
| 机架功耗 | ~120kW | ~140-150kW | ~200kW | ~400+kW[推算] |
| Scale-Out | CX-7 400Gb/s | CX-8 800Gb/s | CX-9 1.6Tb/s+BF4 | CX-9+CPO |
| 推理软件栈 | TensorRT-LLM | TensorRT-LLM+Dynamo初版 | Dynamo 1.0 | Dynamo + AFD |
| 状态 | 已量产 | 已量产 | 验证中 | 未量产 |
注:2026年3月末供应链修正——Rubin Ultra从"单封装4-Die"调整为"2-Die基础单元 + PCB/CoWoP 2+2拼接"。总算力不变,但封装复杂度下降,系统级PCB复杂度上升。[第三方]
读懂这张表的三个关键数字
NVL576 的"576"是 Die 数,不是封装数。 Rubin Ultra 每封装 4 Die(实际为2+2模块化拼接),144封装×4=576。[官方] 这反映了 NVIDIA 的设计哲学转变:不再追求单 Die 极致性能,而是通过多 Die 封装在系统层面堆算力。
算力增长20倍 vs Die增长8倍。 GB200→Rubin Ultra,FP4推理从 720→15000 PFLOPS(~20倍),但 Die 数量只增长8倍(72→576),意味着单 Die 算力实际只增长~2.6倍。系统级算力增长的驱动力正从"芯片更强"转向"系统更大"。
功耗增长3.3倍 vs 算力增长20倍。 看似能效提升,反向解读更准确——散热已成为约束条件,算力增长被迫在功耗预算内寻找路径(引入 FP4 精度、增加 Die 数而非单 Die 功耗)。
二、物理形态的演进:从 Cable Tray 到正交背板
2.1 GB200 NVL72:铜缆的巅峰

48U 标准机柜,布局严格按信号路径最短化:
- 前部:18 个计算托盘,每托盘 2×Grace + 4×Blackwell GPU(NVLink-C2C 连接为 NUMA 域),独立液冷单元
- 中部:9 个 NVLink 交换托盘,每托盘 2×NVSwitch。每颗 NVSwitch 72端口×2×200Gbps = 14.4 TB/s 双向
- 后部:Cable Cartridge,~5000根铜缆,总长3.2公里,总重1.4吨
- 顶部:2×SN2201交换机 + 6-8×33kW电源架(50V DC母线)
- 底部:44U 液冷歧管
拓扑本质:完全二分图 K_{18,72}。 18颗NVSwitch与72颗GPU构成complete bipartite graph。每颗GPU连全部18颗NVSwitch,单跳拓扑,无中间层级。
带宽分配验证:


"正交"含义:计算节点纵向插入与交换节点横向插入在背板平面上互相垂直,两类节点可独立插拔。这带来的好处是:计算节点可以热插拔(故障时直接拔出更换),交换节点也可以独立维护。但这种"独立插拔"是相对的——背板本身是固定的,如果背板内部走线损坏,整个机柜必须返厂。
工程参数:
- 78层PCB(传统服务器主板12-24层,高端网络交换机主板32-48层,78层是前所未有的规模)
- M9级CCL(Dk<3.5, Df<0.002)+ Q布(石英纤维布)+ HVLP4铜箔——这三者的组合是为了在78层堆叠中保持阻抗一致性。Dk(介电常数)决定了信号传播速度,Df(损耗因子)决定了信号衰减,M9级别意味着Df低于0.002——这是目前商用CCL的最高等级
- 差分线对数≥5,184(18节点×4端口×72对/端口)[推算]——每对差分线必须在78层中精确对齐,任何一对的阻抗偏差都会导致误码率上升
- 单块背板价值>20万美元(vs Cable Tray ~3-5万美元)——成本增加了4-6倍
为什么必须放弃铜缆? 深层原因:224G SerDes铜缆传输距离极限~1-2米。NVL576机柜比NVL72大得多(144封装vs36封装),铜缆长度必然超限。正交背板通过PCB内精确阻抗匹配走线实现可靠传输。铜缆不是"不够好"被淘汰,而是在NVL576尺度下"不可用"。
更具体地说:铜缆的趋肤效应(skin effect)在高频下使电流集中在导体表面,200G SerDes时有效传输距离已经很短,224G SerDes时进一步恶化。PCB走线可以通过精确控制线宽、间距和介电层厚度来补偿趋肤效应,而铜缆做不到——分立铜缆的几何一致性无法像PCB一样精确控制。
代价:
- 良率:78层M9 PCB层间对准精度微米级,估计良率60-70% [第三方]。这意味着每3块中可能有1块因层间对准偏差而报废。20万美元/块的成本×30-40%报废率=有效成本28-33万美元/块
- 可维护性倒退:背板固定连接,损坏→整柜返厂(vs铜缆可拔插更换)。一个144封装机柜返厂的运输+维修周期估计2-4周,期间576个Die完全不可用
- 产能瓶颈:M9 CCL仅少数供应商(生益科技、台光电子),Q布菲利华占70%份额,供需失衡持续至2027 [第三方]。这意味着Rubin Ultra NVL576的交付节奏可能不是由芯片产能决定,而是由PCB产能决定——这在NVIDIA历史上是第一次"非芯片因素决定交付"
- 热膨胀不匹配:78层PCB的CTE(热系数)与连接器CTE不完全匹配。400+kW热负荷下,机柜内部温度梯度可达20-30°C,78层PCB各层的热膨胀量不同,长期运行可能导致层间微裂纹。这个问题在实验室环境中不易复现,但在数据中心7×24运行3-5年后可能集中爆发
2.5 正交背板 vs 铜缆:一笔 TCO 账
前面分析了技术优劣,但客户最终的问题是:换背板后,每 token 成本是升还是降?
以 DeepSeek-R1 推理为例,做一个量级估算:
| 成本项 | 双 NVL72 (铜缆方案) | 单 NVL576 (背板方案) |
|---|---|---|
| 硬件成本 | 2×NVL72 ≈ $600-700万 | 1×NVL576 ≈ $1200-1500万 |
| 互联成本 | Cable Tray ×2 ≈ $8-10万 + CX-9 IB交换 ≈ $30万 | 正交背板 ≈ $30万 |
| 总算力(FP4) | 2×1.08 EF = 2.16 EF | 15 EF(7倍) |
| 互联带宽 | 130+130=260 TB/s (NVLink) + IB | 1.5 PB/s (全NVLink) |
| NVLink 域 | 72+72=144 GPU (跨IB) | 576 Die (单域) |
| EP 效率 | EP72×2 跨 IB,all-to-all ~10μs | EP576 单域,all-to-all ~1μs |
| 功耗 | ~280-300kW | ~400+kW |
| 维护 | 铜缆可换件,MTTR~小时级 | 背板损坏返厂,MTTR~周级 |
每 token 成本推算:
- 双 NVL72 理论吞吐:2×226 tok/s/GPU × 72 = 32,544 tok/s(但跨 IB 的 EP 效率打折,实际 ~25,000 tok/s)
- 单 NVL576 理论吞吐:算力是双 NVL72 的 7 倍,但 EP576 的 EP 通信效率不如 EP72×2(跨区延迟)。估计实际吞吐 ~120,000-150,000 tok/s
- 每 token 成本 = (硬件折旧+电费+运维) / 吞吐
- 双 NVL72: ~$3M/年折旧 + $0.3M/年电费 ≈ $3.3M/年 → $3.3M / (25000×3600×8760) ≈ $4.2/百万token
- 单 NVL576: ~$6M/年折旧 + $0.5M/年电费 ≈ $6.5M/年 → $6.5M / (135000×3600×8760) ≈ $1.5/百万token
结论:NVL576 的每 token 成本约为双 NVL72 的 35%。 背板方案虽然硬件成本翻倍,但算力提升 7 倍,折算到每 token 的成本反而大幅降低。
但有一个重要前提:上面的计算假设 NVL576 的可用率(uptime)与双 NVL72 相同。实际上,由于背板返厂的 MTTR 远高于铜缆换件,NVL576 的实际可用率可能低 5-10%。如果按 90% 可用率修正,每 token 成本上升到 ~$1.7/百万token,仍然是双 NVL72 的 40%。
对客户的实际含义:如果你只买得起 1-2 台 NVL72,铜缆方案仍然是合理选择。但如果你在规划一个 100+ 柜的 AI 工厂,NVL576 的每 token 成本优势是不可忽视的——前提是你能接受更长的维修周期和更高的前期投入。
三、互联架构演进:NVLink 5 → NVLink 6
3.1 NVLink 5(Blackwell 架构)
核心参数:
- SerDes: 100G→200G
- 单GPU: 18链路×100GB/s双向 = 1.8TB/s
- NVSwitch: 72端口×2×200Gbps = 14.4TB/s双向
- SHARP引擎:交换机内in-network reduction,all-reduce通信量减少N倍
- Scale-Out: CX-7 400Gb/s + Quantum-2 IB / Spectrum-X 以太网
SHARP的具体作用值得展开。 传统all-reduce中,每个GPU发送完整数据到所有其他GPU(或通过Ring/Tree算法),通信量随GPU数线性增长。SHARP在NVSwitch内直接做归约运算——数据到达交换机时就被reduce,不再需要传回GPU再做。
实际效果:72 GPU的all-reduce,不使用SHARP时每GPU需要发送71份梯度副本,使用SHARP后每GPU只需发送1份到交换机,交换机归约后再广播结果。通信量减少约N/2倍(N=参与GPU数)。
这对MoE模型尤其关键:DeepSeek-R1的Expert Parallelism需要all-to-all通信来路由token到正确的专家,SHARP直接加速了这一步骤。
3.2 NVLink 6(Rubin 架构)
变化不仅是带宽翻倍:
- SerDes: 200G→224G(+12%,翻倍来自通道数翻倍)
- 单GPU: 3.6TB/s
- 控制平面韧性:控制通道独立于数据通道,瞬时错误不影响连接状态
- 部分部署运行:部分托盘故障→降级运行而非整机不可用
- 交换托盘热插拔:NVSwitch在线更换
运维韧性为什么重要? NVL72单点故障影响72 GPU已很大。NVL576无此能力→任一组件故障=576 Die不可用。这些功能是为NVL576规模化铺路。
"部分部署运行"的具体含义:如果18个计算托盘中某一台故障,系统不需要整机下线。NVLink 6交换机可以重新配置拓扑,将故障节点隔离,剩余节点以降级模式继续运行。这类似于RAID阵列中一块盘故障时阵列降级运行的思路。在576-Die的系统中,这种能力不是"nice to have"而是"must have"——576个Die的故障率远高于72个Die。
带宽验证:72 × 3.6TB/s ÷ 2 × 2 = 259.2TB/s ≈ 260TB/s [与官方吻合]
3.3 拓扑扩展
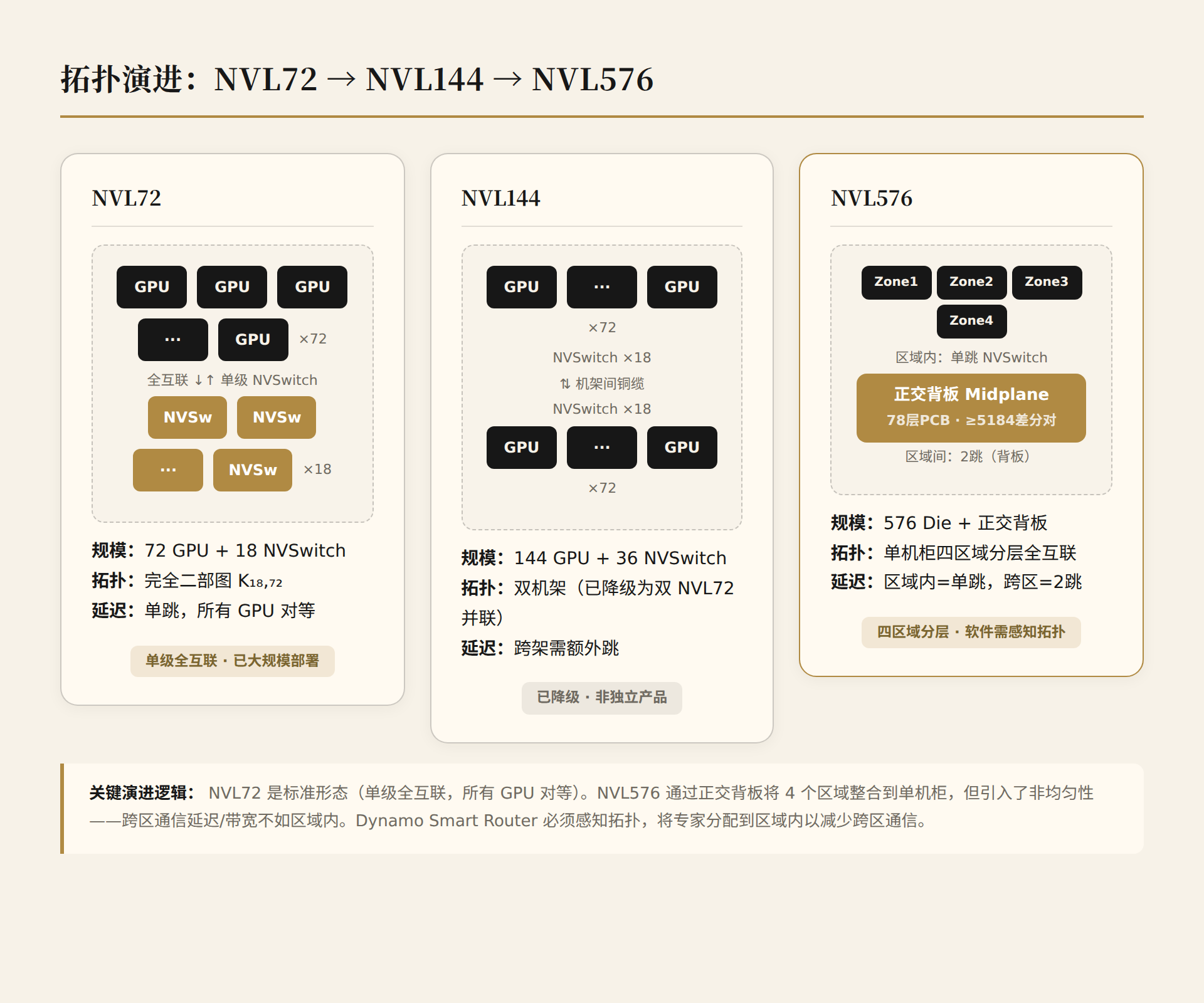
NVL576分层全互联的架构性妥协:
- 区域内:all-to-all单跳NVSwitch,延迟=NVL72
- 区域间:需经背板,可能2跳(源区NVSwitch→背板→目标区NVSwitch)
- 区域间带宽:受背板差分线对数限制
在NVL72中所有GPU对等。NVL576中跨区通信延迟/带宽不如区域内。MoE的Expert Parallelism需考虑这种非均匀性——软件调度必须感知拓扑。这正是Dynamo Smart Router的工作之一:将专家分配到区域内以减少跨区通信。
四、芯片迭代:GPU、CPU、LPU三线并进
4.1 GPU:Die数量指数增长与单Die算力悖论
| 架构 | Die/封装 | 总Die | 单封装FP4 | 单Die FP4 | HBM |
|---|---|---|---|---|---|
| Blackwell | 2 | 72 | ~20P | ~10P | 192GB HBM3e |
| Blackwell Ultra | 2 | 72 | ~30P | ~15P | 288GB HBM3e |
| Rubin | 2 | 72 | ~100P | ~50P | 288GB HBM4 |
| Rubin Ultra | 2+2模块化 | 576 | ~104P | ~26P | 1TB HBM4e |
Rubin Ultra单Die算力(~26 PFLOPS)反而低于Rubin(~50 PFLOPS/Die)。原因:4-Die封装共享HBM4e接口和NVLink带宽,单Die算力密度被均摊。系统总算力提升更多来自规模扩展。
HBM4 的质变:Blackwell 架构 HBM3e 带宽8TB/s,Rubin 架构 HBM4 达22TB/s(2.75倍)。这个带宽跳跃才是Rubin单Die性能飞跃的关键推手——很多LLM算子在Decode阶段是Memory Bandwidth Bound,HBM带宽直接决定实际吞吐。
4.2 CPU:从Grace到Vera——Agentic AI时代的角色质变
Grace CPU定位从"GPU附属"转向"推理调度中枢"。Vera CPU核心数翻倍、内存带宽提升,支撑Dynamo Planner的实时决策、Smart Router的Radix Tree遍历、多agent并发编排。
4.3 LPU:Groq 3加冕——"第七成员"的推理专用引擎
LPU不是GPU替代品,而是推理专用加速层。GPU的HBM容量和计算密度适合Prefill/Attention;LPU的SRAM带宽(150TB/s/芯片,约7倍HBM4)适合FFN Decode。通过Dynamo编排,AFD(Attention-FFN分离)将推理拆分到两种硬件上。
4.4 系统设计比率演进:Roofline模型下的硬件耦合逻辑
| 比率 | Hopper | Blackwell | Rubin | 趋势 |
|---|---|---|---|---|
| HBM/算力(FP8) | ~597 | ~563 | ~1136 FLOPs/Byte | ↑ 恶化 |
| HBM/NVLink | 3.7x | 4.4x | 6.1x | ↑ 恶化 |
| L2/专家权重 | 0.06% | 0.05% | 0.06% | → 停滞 |
设计哲学总结:一个耦合优化问题
把三个比率放在一起看,NVIDIA 的系统设计逻辑是:
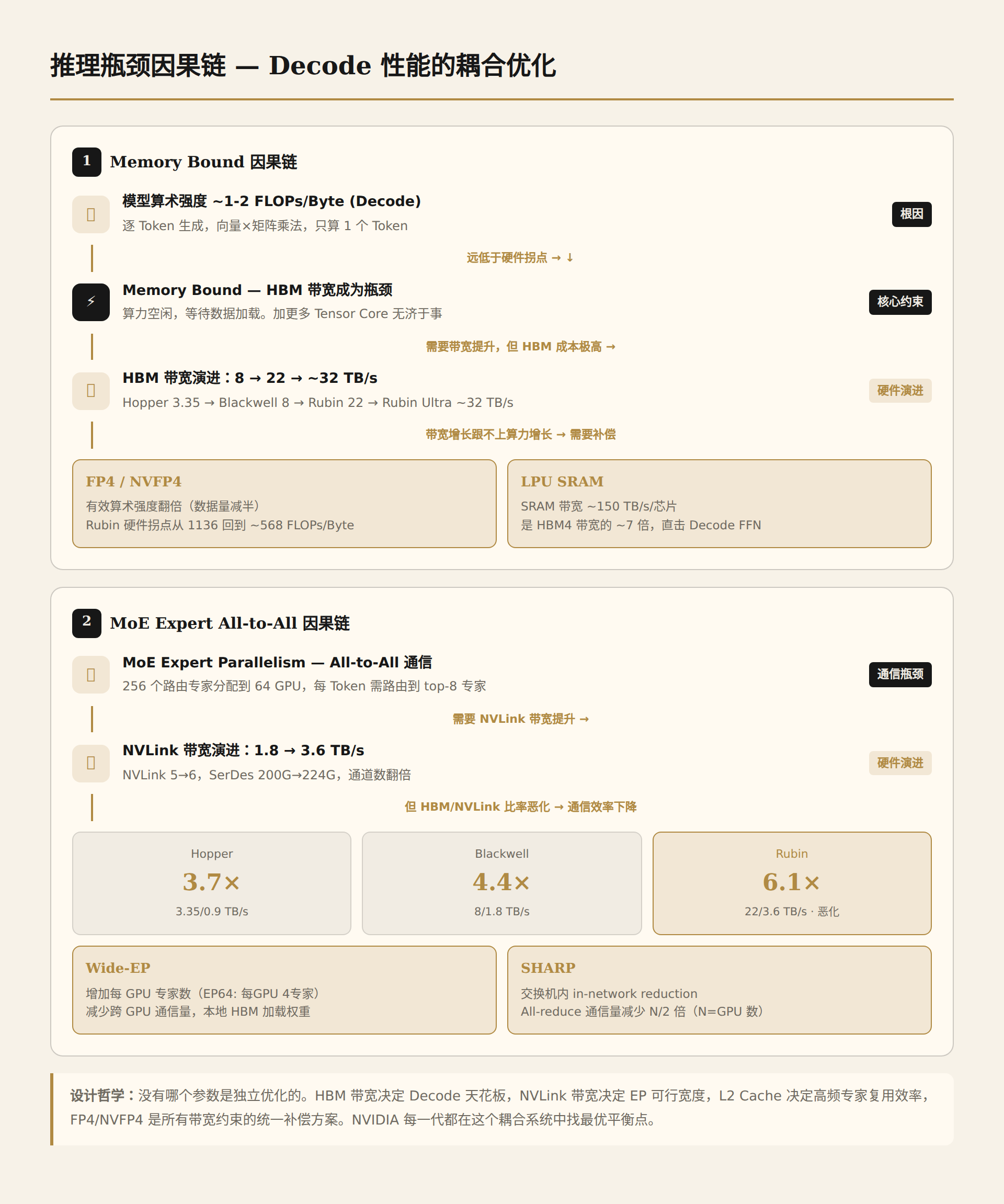
没有哪个参数是独立优化的。 HBM 带宽决定了 Decode 性能的天花板,NVLink 带宽决定了 EP 的可行宽度,L2 Cache 决定了高频专家的复用效率,FP4/NVFP4 是所有带宽约束的统一补偿方案。NVIDIA 每一代都在这个耦合系统中找最优平衡点。
理解了这套逻辑,再看前面的表格就不是一堆孤立的数字,而是一个精密耦合的工程设计——每个参数的变化都有"因为...所以..."的因果链。
五、实测数据演进:从 H100 到 GB300 NVL72,推理性能的量化跨越
这一章是本文最重要的新增内容。之前分析的都是规格和推算,现在用实际测试数据验证理论预期。
5.1 跨代推理性能对比(第三方基准)
以下数据来自 SemiAnalysis InferenceMAX 报告、CoreWeave 实测、MLPerf Inference v5.1/v6.0,测试模型为 DeepSeek-R1 671B(MoE架构)。
| 指标 | H100 HGX 8卡 | GB200 NVL72 | GB300 NVL72 | 提升倍数(vs H100) |
|---|---|---|---|---|
| 单GPU吞吐(DeepSeek-R1) | ~1.2 tok/s/GPU | ~75 tok/s/GPU | ~226 tok/s/GPU | 188x(GB300) |
| FP4 vs FP8 | FP8 | FP8 | FP4 | FP4额外2x |
| 并行策略 | TP16 | EP64 | EP64+PD分离+Wide-EP | 策略演进 |
| NVLink域 | 8 GPU | 72 GPU | 72 GPU | 域扩大9x |
| HBM容量/GPU | 80GB | 192GB | 288GB | 3.6x |
数据来源与解读:
-
H100基线:~1.2 tok/s/GPU,TP16意味着16卡张量并行,需要4个8卡节点通过IB互联。All-to-all通信跨IB网络,延迟是主要瓶颈。MoE的Expert Parallelism在8卡域内无法有效展开——256个专家分配到16个GPU上每个GPU承载16个专家,Expert All-to-All的通信量巨大。
-
GB200 NVL72:~75 tok/s/GPU [SemiAnalysis/Signal65],这是在FP8精度、EP64并行策略下的数据。75 tok/s/GPU × 72 GPU = 5400 tok/s 整机吞吐。性能提升来自三个因素:
- NVLink域从8→72:EP通信不再经过IB网络,all-to-all延迟从毫秒级降到微秒级
- HBM 80→192GB:可容纳更大的KV Cache,减少offload
- 30TB共享内存:CPU+GPU统一寻址,KV Cache卸载路径更短
-
GB300 NVL72:~226 tok/s/GPU [SGLang/NVIDIA联合测试],FP4精度,ISL=128K/OSL=8K。226 tok/s/GPU × 72 = 16,272 tok/s 整机吞吐。相比GB200提升3倍,来源:
- FP4 vs FP8:算力翻倍(Blackwell Ultra原生支持FP4 Tensor Core)
- 288GB HBM3e:更多显存容纳更长上下文+更多并发,128K上下文不再是瓶颈
- FMHA kernel优化:注意力计算效率提升1.35倍 [SGLang]
- PD分离+Wide-EP:Dynamo编排下的解耦推理(详见5.2节)
-
MLPerf Inference v6.0纪录:GB300 NVL72在DeepSeek-R1服务器端测试中达到8064 tokens/sec/GPU [MLPerf v6.0]。注意这个数字和226的差异——MLPerf使用的是离线/服务器端场景,可能采用不同的batch策略和ISL/OSL配置。MLPerf v5.1→v6.0单版本提升就达2.77倍,说明软件优化(TensorRT-LLM内核融合+Dynamo PD分离)的贡献巨大。
5.2 软件栈的代际演进
硬件规格的提升只是故事的一半。从H100到GB300,软件栈的演进同样关键——甚至在某些场景下,软件优化的贡献超过了硬件升级。
| 软件能力 | H100 时代(2023) | GB200 时代(2024) | GB300 时代(2025-26) | Vera Rubin(2026H2) |
|---|---|---|---|---|
| 推理引擎 | TensorRT-LLM初版 | TensorRT-LLM成熟 | TRT-LLM + vLLM + SGLang | 同左 |
| 解耦推理 | 无 | 无 | Dynamo PD分离 | Dynamo 1.0 AFD |
| KV Cache管理 | GPU显存内 | 显存+CPU offload | 分布式KV Cache Pool | 多级存储卸载 |
| 并行策略 | TP8 | TP+PP+DP | +Wide-EP+Chunked-PP | +AFD(GPU+LPU) |
| 精度 | FP16/BF16 | FP8 | FP8+FP4 | NVFP4 |
| 路由 | Round-robin | 负载均衡 | LLM感知智能路由 | 拓扑感知路由 |
| GPU调度 | 静态分配 | 静态分配 | 动态Planner | 动态+跨硬件 |
关键洞察:从GB200到GB300,硬件规格增量不大(FP4支持+HBM容量+CX-8),但推理性能提升了3倍。 这个3倍主要来自软件:Dynamo的PD分离、Wide-EP、Chunked-PP、FMHA kernel优化。这是典型的"硬件定义天花板,软件决定实际性能"的案例。
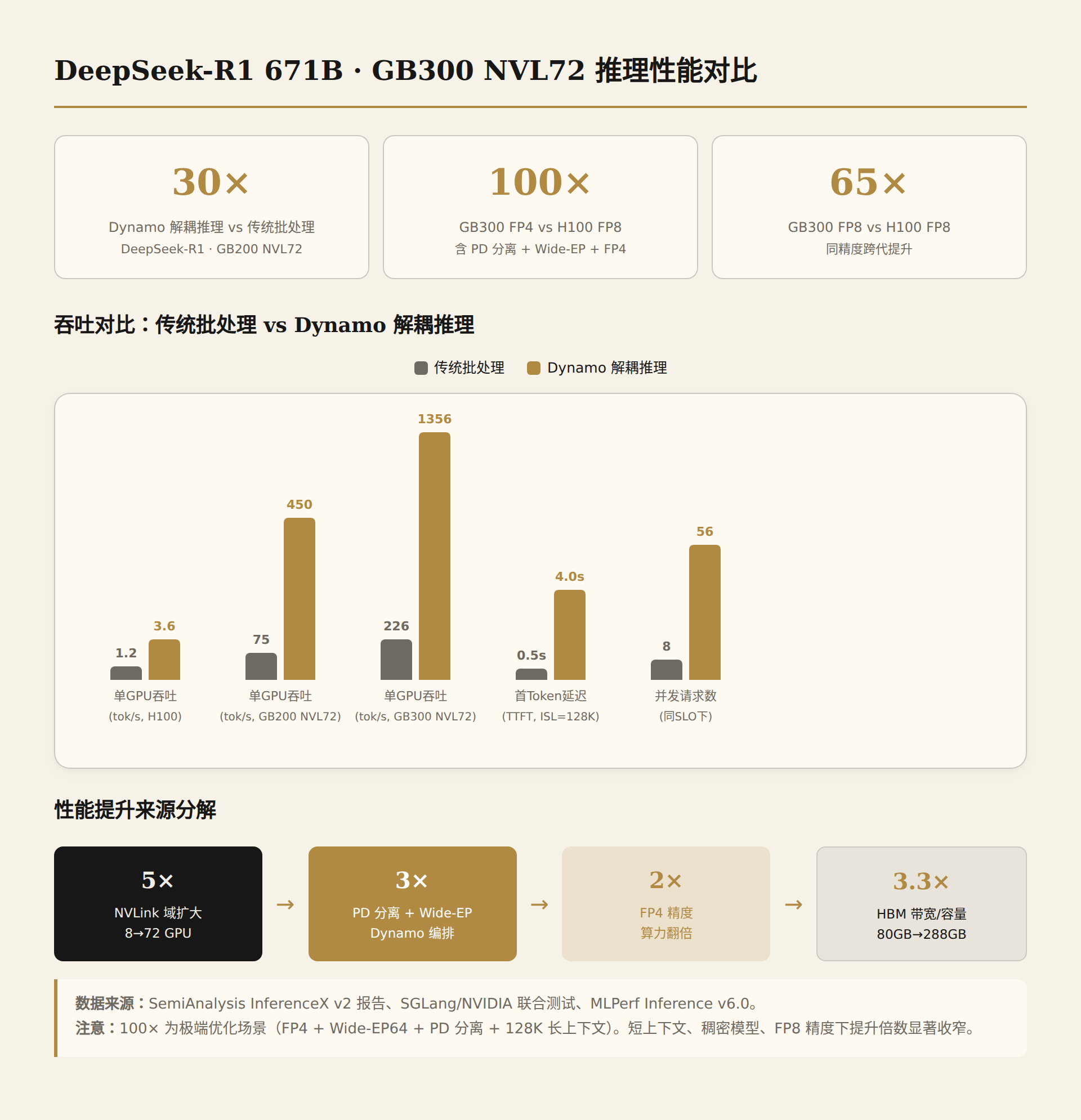
5.3 SemiAnalysis基准:30倍→100倍的完整曲线
SemiAnalysis InferenceX v2报告提供了最完整的跨代对比。核心结论:
黄仁勋在GTC 2024宣称的"30倍推理提升"确实保守了。 实测数据:
| 对比场景 | 基线 | GB300 NVL72性能 | 倍数 |
|---|---|---|---|
| FP4 vs FP8(H100) | H100 FP8 | GB300 FP4 | ~100x |
| FP8 vs FP8 | H100 FP8 | GB300 FP8 | ~65x |
| FP8 vs FP8(同样Dynamo) | H100+Dynamo | GB300+Dynamo | ~30x |
| MoE场景 vs AMD | MI355X | GB300 | ~28x |
但要注意场景依赖性。 100倍是"极端优化场景"——FP4精度、Wide-EP64、PD分离、128K长上下文。在短上下文(<4K)、稠密模型、FP8精度下,提升倍数会显著收窄。
功耗效率的演进更有说服力:
| 指标 | H100 | GB300 NVL72 | 倍数 |
|---|---|---|---|
| 每Watt吞吐 | 基线 | 5x | [NVIDIA官方] |
| 每token成本 | 基线 | 1/35 | [NVIDIA官方] |
| vs AMD MI355X per token成本 | N/A | 1/15 | [Signal65] |
5.4 一个 Token 的完整旅程:DeepSeek-R1 在 GB300 NVL72 上
前面列了数字,但读者可能仍然缺乏"体感"。让我们追踪一个 Agentic 推理请求的完整生命周期,看看每个环节的时间都花在哪里。
场景:用户发送第10轮对话,ISL=128K(含前9轮上下文),期望 OSL=500 tokens。模型 DeepSeek-R1 671B MoE,256个路由专家,top-8 路由。

从时间轴中可以读出的关键洞察:
-
Attention 是 Decode 的真正瓶颈(580μs vs FFN 44μs)。这是因为 KV Cache 随上下文长度线性增长,而 FFN 的专家权重大小固定。这解释了为什么 AFD(Attention-FFN 分离)有道理:把 Attention 留在 GPU(有 HBM 存 KV Cache),FFN 搬到 LPU(SRAM 带宽 7 倍于 HBM,FFN 纯权重加载极快)。
-
NVLink 带宽在 EP 场景下绰绰有余(Expert All-to-All 0.3μs vs HBM 加载 44μs)。这不是巧合——NVIDIA 故意将 NVLink 带宽设计为"远超 EP 通信需求",确保 EP 不受互联瓶颈。真正的瓶颈永远在 HBM。
-
Smart Router 的 KV Cache 复用节省了 ~99% 的 Prefill 计算(增量 4K vs 全量 128K)。在 Agentic 场景下,10 轮对话的 Smart Router 复用可能将总 Prefill 时间从秒级降到毫秒级。
-
单个 Decode token 的理论下限约 624μs,但实测是 4.4ms/GPU(含 batch 调度)。差距来自 batch 合并、GPU 调度开销、以及 Continuous Batching 的排队等待。这意味着软件调度效率还有 ~7 倍的优化空间。
六、软件栈深度解析:Dynamo 为什么是"AI工厂的操作系统"

6.1 从Triton到Dynamo:推理框架的范式转移
2018年NVIDIA发布Triton推理服务器时,AI推理还是"单GPU跑单模型"的世界。Triton解决了框架统一问题(TensorFlow/PyTorch/ONNX统一部署),但面对2025-2026年的推理场景——671B参数MoE模型跨72 GPU分布式推理——它力不从心。
根本差异:Triton管理的是"模型部署",Dynamo管理的是"分布式推理编排"。具体来说:
- Triton:一个请求→一个GPU处理→返回结果。模型再大也只是多切几份
- Dynamo:一个请求→拆成Prefill+Decode两阶段→分配到不同GPU组→KV Cache在GPU间迁移→动态调整GPU分配→合并结果。每个阶段可以用不同的并行策略
这种"拆请求"的能力是Dynamo的核心创新,也是NVIDIA称其为"AI工厂的操作系统"的原因——它不只是部署模型,而是编排整个推理流水线。

6.2 Dynamo架构:四个核心组件
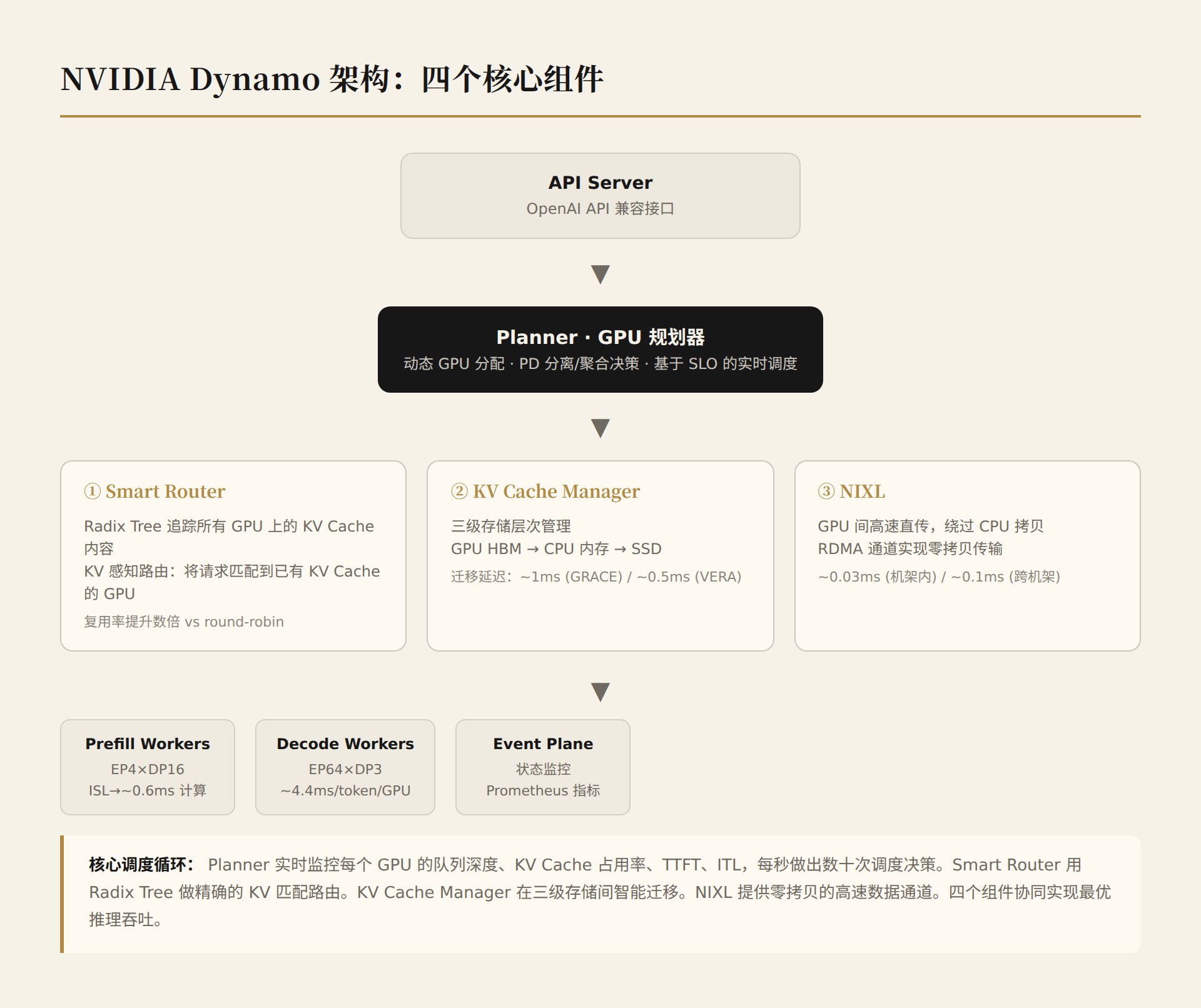
1. Planner(GPU规划器)
这不是简单的负载均衡。Planner面临的核心问题是:每个请求的Prefill和Decode阶段负载极度不均匀。
举例:一个128K上下文的摘要请求(ISL=128K, OSL=500),Prefill需要处理128K token的计算密集型前向传播,Decode只需要逐个生成500个token。如果Prefill GPU和Decode GPU各分配一半,长输入请求会导致Prefill GPU积压,Decode GPU空闲。
Planner的决策维度:
- Prefill/Decode GPU比例:根据实时ISL/OSL分布动态调整
- 分离 vs 聚合:短输入请求(ISL<2K)可能不需要PD分离,直接在一个GPU上聚合处理更高效
- GPU数量弹性:请求高峰时临时分配更多GPU给Prefill,低谷时回收
这个决策是实时的——Planner持续监控每个GPU的队列深度、KV Cache占用率、TTFT(首token延迟)、ITL(token间延迟),每秒可能做出数十次调度决策。
2. Smart Router(智能路由器)
传统负载均衡用round-robin或最少连接数路由。Dynamo的Smart Router不同:它用Radix Tree追踪所有GPU上的KV Cache内容,计算新请求与已有KV Cache的重叠度,将请求路由到KV Cache匹配度最高的GPU。
为什么这很重要?考虑一个Agentic场景:用户与Agent进行了10轮对话,前9轮的KV Cache已经在GPU-7上。第10轮请求到达时,Smart Router将请求直接路由到GPU-7,复用已有的KV Cache,省去了重新计算前9轮上下文的计算量。
NVIDIA给出的数据:在2节点HGX-H100(16 GPU)、DeepSeek-R1-Distill-Llama-70B、10万真实R1请求(平均ISL/OSL=4K/800)的测试中,Smart Router相比round-robin将响应时间显著缩短,KV Cache复用率提升数倍。[NVIDIA开发者博客]
3. KV Cache Manager(KV缓存管理器)
KV Cache是LLM推理中最大的内存消耗项。128K上下文、FP8精度、671B MoE模型——单请求的KV Cache可达数百MB到数GB。72个GPU上同时运行数百个请求,KV Cache总量可达数十到数百GB。
KV Cache Manager实现三级存储层次:
- GPU HBM(最快,最贵):活跃请求的KV Cache
- CPU内存(中等):近期完成但可能复用的KV Cache
- SSD/网络存储(最慢,最便宜):长期存储但可能被复用的KV Cache(如system prompt)
关键创新:KV Cache在三级存储间的迁移是异步的,不阻塞推理。GPU生成完token后,KV Cache在后台被搬到CPU内存;新请求到来时,如果KV Cache在CPU内存中,通过NVLink-C2C高速搬回GPU HBM。
Grace CPU的NVLink-C2C带宽900GB/s(Vera提升到1.8TB/s),意味着1GB的KV Cache从CPU内存搬到GPU HBM只需~1ms(Grace)或~0.5ms(Vera)。这对性能几乎无感知。
4. NIXL(NVIDIA Inference Transfer Library)
NIXL是Dynamo中最低调但最关键的组件——它解决了"GPU间KV Cache高速传输"的问题。
在PD分离架构中,Prefill完成后需要将KV Cache从Prefill GPU传到Decode GPU。如果这两个GPU在同一NVL72机架内,通过NVLink传输130TB/s,速度很快。但如果跨机架(Scale-Out场景),传统方法需要GPU→CPU内存→网卡→网络→网卡→CPU内存→GPU,多次拷贝。
NIXL通过GPUDirect RDMA实现GPU→GPU直传,跳过CPU内存拷贝。结合CX-8的800Gb/s带宽,跨机架KV Cache传输延迟从毫秒级降到百微秒级。[NVIDIA开发者博客]
6.3 Dynamo在不同超节点上的表现差异
| 软件优化 | 无NVL72(8卡) | GB200 NVL72 | GB300 NVL72 | Vera Rubin NVL72 |
|---|---|---|---|---|
| PD分离效果 | 有限(EP域小) | 显著(72卡EP域) | 3x于GB200 | 更高(260TB/s) |
| Wide-EP | 不可行(EP>8需跨节点) | EP64可行 | EP64+FP4 | EP72+NVFP4 |
| KV Cache Offload | CPU内存有限 | 30TB共享 | 40TB共享 | 更多+SSD层 |
| Smart Router | 8卡无需复杂路由 | 72卡有必要 | 72卡有必要 | 576 Die必须有 |
| Dynamo实测提升 | ~2x(Llama 70B) | ~30x(DeepSeek-R1) | 同左+FP4额外2x | 待验证 |
核心洞察:Dynamo的价值随超节点规模非线性增长。 在8卡HGX上,PD分离的收益有限——因为EP域太小,MoE的Expert All-to-All通信仍然要跨IB网络。在72卡NVL72上,EP64可以在NVLink域内完成,通信延迟降两个数量级,Dynamo的编排能力才真正发挥。
这意味着:NVL72的硬件优势不是独立的,而是与Dynamo耦合的。 没有Dynamo,NVL72只是一个更大的GPU池;有了Dynamo,72个GPU才真正"变成一个巨型GPU"。
6.4 SHARP:网络内计算的隐藏加速器
SHARP(Scalable Hierarchical Aggregation and Reduction Protocol)是NVSwitch中的硬件加速引擎,直接在交换机内执行all-reduce/broadcast等集合通信操作。
为什么这很重要? 以DeepSeek-R1的Expert Parallelism为例:
256个专家分配到64个GPU(Wide-EP64),每次token路由需要all-to-all通信。传统方式:每个GPU发送64份梯度到所有其他GPU,总计64×64=4096次传输。SHARP方式:每个GPU发送1份到NVSwitch,NVSwitch在内部完成reduce,再广播结果——通信量减少约32倍。
SHARP在NVLink 5时代已有,但NVLink 6交换机增强了SHARP引擎的吞吐量和支持的集合通信类型。在MoE推理场景中,SHARP对Expert All-to-All的加速效果可达2-4倍(取决于GPU数量和专家分配策略)。[NVIDIA]
七、功耗与散热:从冷板到微通道
| 架构 | 单GPU功耗 | 机架功耗 | 散热方案 | 每EFLOPS功耗 |
|---|---|---|---|---|
| Blackwell | ~1000W | ~120kW | 冷板式液冷 | 167 kW/EFLOPS |
| Blackwell Ultra | ~1400W | ~140-150kW | 冷板液冷+增强 | 130 kW/EFLOPS |
| Rubin | ~2000W | ~200kW | 全液冷+微通道冷板 | 56 kW/EFLOPS |
| Rubin Ultra | ~2000W+ | ~400+kW | 全液冷+微通道+相变(可能) | 27 kW/EFLOPS |
2000W/GPU是冷板式液冷的物理极限。 原因:
芯片面积固定(~800mm²),热流密度 = 2000W / 800mm² ≈ 2.5 W/mm²。传统冷板的微通道只能覆盖芯片表面的一部分,边缘散热效率下降。
超过这个阈值需要:
- 微通道盖板:在GPU盖板内加工微小流道(50-200μm),冷却液"贴身"带走热量。制造工艺类似半导体光刻,成本高但效果好——温度梯度从传统冷板的10-15°C降到5°C以内
- 冷板+浸没复合:冷板带走~60%,氟化液浸没带走~40%。浸没冷却的沸点冷却(两相浸没)在芯片表面形成气泡带走热量,散热效率极高但氟化液成本昂贵(3M Novec系列约$500/L)
- 相变冷却:低沸点介质(电子氟化液)在芯片表面蒸发吸热。蒸气上升→冷凝→回流,形成自循环。无需泵驱动,但系统设计复杂度大幅提升
Rubin Ultra散热方案尚未完全公开,多供应链信源指向微通道+相变复合方案。[第三方,未验证]
一个值得计算的数据:Vera Rubin NVL72 机架~200kW,假设PUE=1.1,机房需提供~220kW电力和冷却能力。Rubin Ultra NVL576 机架~400+kW,如果PUE不变,单个机柜需要~440kW——这已经是一个中型企业数据中心的总功率。超节点的功耗增长正在逼近基础设施极限。
微软Azure已部署全球首个GB300 NVL72生产集群——64组液冷机架,4608个Blackwell Ultra GPU。[第三方] 要部署等量Rubin机架,功耗将从~9MW增至~13MW,对现有数据中心的供电和散热系统构成巨大压力。
从能效角度看好消息是:每EFLOPS功耗从Blackwell的167kW降到Rubin Ultra的27kW(6倍改善)。但绝对功耗增长速度(120→400kW)超出了多数数据中心的承受能力。AI数据中心的建设速度正在被供电基础设施拖后腿。
八、NVL144去哪了?一个被跳过的超节点
这是超节点演进中最容易被忽略的转折点。
2025年10月GTC DC大会,NVIDIA宣布Vera Rubin NVL144——144 GPU的双机架NVLink域。官方规格:3.5 EFLOPS FP4推理,75TB高速存储,NVLink+CX9通信带宽分别260TB/s和28.8TB/s。
但在GTC 2026(2026年3月)路线图中,NVL144被降级为"双NVL72并联"方案,而非独立单机架产品。
我的判断:两个原因。
物理约束:224G SerDes在铜缆上的传输距离极限约2米(vs 200G的2-3米)。NVL144需要双机架NVLink域,意味着铜缆要跨越两个机架间的距离(至少0.5-1米的走线+连接器)。在224G速率下,这个距离的信号完整性无法保证。即使使用PCB内嵌铜走线(Vera Rubin NVL72方案),跨机架连接仍然需要某种外部电缆或连接器。
产品逻辑:客户可以直接买两台NVL72,通过CX-9 InfiniBand(1.6Tb/s)互联,实现近乎等价的Scale-Out性能。独立NVL144需要额外的NVLink跨机架交换硬件(成本高、可靠性风险大),但性能增益有限——不值得为此开发一个独立产品。
更深层的产品节奏含义:NVIDIA选择了"跳过中间态,等待终局方案"。真正的Scale-Up扩展被推迟到Rubin Ultra NVL576——通过正交背板在单机柜内实现576-Die互联,完全绕过跨机架铜缆。这意味着:
- NVL72 是唯一成熟的Scale-Up单元,在Blackwell和Rubin两代都保持72-GPU规模
- NVL576 是NVIDIA对Scale-Up扩展的终极回答,但需要等到2027H2
- 中间的Scale-Out(CX-9 InfiniBand/Spectrum-X)在2026-2027年承担大部分多机架扩展任务
这对客户的影响:2026-2027年,你的选择是"单NVL72"或"多NVL72+InfiniBand"。没有"单NVL144"这个选项。
九、Vera Rubin POD:五种机架构成一台超级计算机
GTC 2026披露的Vera Rubin POD是超节点概念的终极形态——5种专用机架组成一台AI超级计算机:
| 机架类型 | 角色 | 核心组件 | 关键能力 |
|---|---|---|---|
| NVL72机架 | 计算引擎 | 72 Rubin GPU + 36 Vera CPU | 训练+Prefill+Attention |
| LPX机架 | 推理加速 | 256 Groq 3 LPU | Decode FFN+Speculative Decoding |
| STS存储机架 | KV Cache扩展 | BlueField-4 DPU + SSD | 推理上下文记忆存储 |
| XTS机架(以太网) | Scale-Out扩展 | Spectrum-X以太网交换 | 跨POD以太网互联 |
| XTS机架(IB) | IB扩展 | Quantum-X800 IB交换 | 跨POD InfiniBand互联 |
完整POD规格:40机架,~20000 Die,60 EFLOPS,10 PB/s扩展带宽,~1.2万亿个晶体管。[官方]
这不是"超节点"——这是一台AI超级计算机。NVIDIA从"卖GPU芯片"到"卖AI超级计算机"的产品形态转变,在POD架构中体现得最清晰。
Dynamo软件栈是串联这一切的关键——它负责将推理请求拆分为Prefill(→NVL72)和Decode(→LPX),管理KV Cache的卸载和共享(→STS),协调跨POD的负载均衡(→XTS)。没有Dynamo,这五种机架只是互不相干的硬件。有了Dynamo,它们是一个有机整体。
POD对软件栈的要求远超当前Dynamo能力。 AFD(Attention-FFN Disaggregation)需要跨GPU和LPU两种异构硬件编排推理流水线,这在2026年仍处于早期阶段。Dynamo 1.0支持PD分离和Wide-EP,但AFD跨硬件编排是Vera Rubin量产后才能真正考验的能力。
9.1 AFD 实战:一个跨三种硬件的推理请求
场景:同一个 Agentic 请求(ISL=128K, OSL=500),但这次跑在完整的 Vera Rubin POD 上——NVL72 做 Attention,LPX 做 FFN Decode,STS 做 KV Cache 长期存储。

AFD 的关键洞察:
-
Attention 停在 GPU,FFN 搬到 LPU,原因不在于"哪个更快",而在于数据特征。 KV Cache 随上下文线性增长(128K→256GB),只有 GPU 的 HBM(288GB/Rubin)能存下;FFN 专家权重固定大小(44MB/专家),LPU 的 SRAM(0.5GB/LPU)+ DDR(256GB/Tray)足够。数据特征决定硬件选择,不是反过来。
-
AFD 的额外传输开销(~10μs/token 以太网)相对 Attention 延迟(~580μs)可忽略。 这意味着 AFD "几乎免费"——开销不到 2%。但前提是有足够的网络带宽和低延迟以太网(Spectrum-X)。
-
Speculative Decoding 是 LPU 的杀手级能力。 LPU 的确定性执行(没有 GPU 的 warp divergence 和缓存抖动)使得一次前向传播的时间完全确定,可以精确预测哪个候选 token 会被接受。GPU 做不到这一点——其执行时间的方差(变异系数 CV≈0.3-0.5)使得投机解码的效率大打折扣。
AFD 跨硬件编排的工程挑战: 上面描述的流程需要 Dynamo 同时管理 CUDA(GPU)和 Groq 编译器(LPU)两种编程模型,在运行时动态选择目标硬件并管理跨硬件数据传输。Dynamo 1.0 支持 PD 分离和 Wide-EP,但 AFD 跨硬件编排是 Vera Rubin 量产后才能真正考验的能力——这是 NVIDIA 收购 Groq 后最大的软件工程挑战。
十、风险、挑战与反面论证
10.1 正交背板不是万能药
可维护性倒退是最大的问题。铜缆架构中,任一链路故障可以定位到具体铜缆并更换(耗时但可行)。正交背板中,Mezzanine连接器焊点或内部走线故障→整柜返厂。在一个144封装的机柜中,这意味着144个GPU同时不可用,直到维修完成。
这是否可接受取决于MTBF。NVIDIA官方没有公布NVL576的MTBF预期,但考虑到576 Die+数千连接器+78层PCB的系统复杂度,行业估算首次系统级MTBF可能在5000-10000小时范围。[第三方,不确定] 如果按8000小时MTBF计算,一个1000柜的AI工厂每月平均会有~90次需要整柜返厂的故障事件。这个数量级是否可接受?需要看维修时间(MTTR)和冗余设计。
产能瓶颈:M9 CCL(生益科技、台光电子)+ Q布(菲利华70%份额)+ HVLP4铜箔(德福科技等)的全球产能有限。国金证券研报指出,供需失衡预计持续到2027年。这意味着Rubin Ultra NVL576的交付节奏可能不是由芯片产能决定,而是由PCB产能决定——这在NVIDIA历史上是第一次"非芯片因素决定交付"。
10.2 "8年1000倍"的基线问题
NVIDIA宣称"8年1000倍算力增长"。但拆解这个数字:
- 数据格式变化:FP16→FP8→FP4,每次"精度降级"名义上算力翻倍。但这不是"同一计算更快",而是"用更少的位数近似同一结果"
- 多Die封装:Blackwell从1-Die→2-Die(算力翻倍但晶体管翻倍),Rubin Ultra→4-Die(同理)
- 系统规模:NVL72→NVL576,Die数增8倍
如果看**单Die、同精度(FP8)**的实际性能提升:Hopper→Blackwell约1.5-2x(TSMC 4N→4NP制程红利有限),Blackwell→Rubin约3-3.5x(TSMC 4NP→N3P + HBM4 + 架构优化)。真正的单Die代际提升在2-3倍范围,远低于"1000倍"暗示的年化增速。
这不是说NVIDIA在造假——系统级算力确实在快速增长。但增长的主要来源正在从"芯片更强"转向"系统更大+精度更低"。
实测数据也印证了这一点:从H100到GB300 NVL72的100倍提升中,FP4贡献2x、NVLink域扩大贡献~5x(EP效率)、Dynamo PD分离贡献~3x、HBM容量/带宽贡献~3x。硬件和软件各占约一半功劳。
10.3 光子学才是终局
Intel SC25报告明确指出:2028年是铜缆的终局。NVL576的正交背板本质是"用PCB铜走线替代铜缆"——仍然是铜。
NVIDIA已在Spectrum-X交换机中引入200G硅光CPO(共封装光学),但尚未扩展到GPU间NVLink域。Feynman 架构(2028年量产)预计将NVLink的LPU C2C总线切换到CPO架构。[第三方,基于NVIDIA路线图推演]
如果成真,正交背板可能只存在一代(Rubin Ultra)就被光子互联取代。这意味着78层M9 PCB正交背板的高额投资,其产品生命周期可能只有1-2年。
但CPO本身也有风险:硅光的耦合效率、封装良率、功耗(激光器阵列的功耗不容忽视)、成本(目前CPO模块单价远高于铜互联)都是未解的工程挑战。
10.4 功耗墙仍然无解
从NVL72到NVL576,机架功耗~120→400+kW(3.3倍)。按此趋势:
- Feynman 架构(~2028):可能达到1MW/机柜
- 这已接近中型数据中心总功率
- 北美数据中心电力和选址瓶颈日益突出
- 微软、Google、Meta等已在核能、地热等非常规能源上布局
性能提升的边际成本正在急剧上升。 每EFLOPS的功耗从Blackwell的~120kW/0.72EFLOPS = 167kW/EFLOPS变为Rubin Ultra的~400kW/15EFLOPS = 27kW/EFLOPS。看起来能效在提升(6倍),但绝对功耗的增长速度超出了大多数数据中心的承受能力。
10.5 软件栈的成熟度风险
Dynamo在GB300 NVL72上的表现已经过验证(30倍提升),但AFD(Attention-FFN Disaggregation)跨GPU+LPU的编排还处于早期。几个具体风险:
- 异构编排复杂度:GPU和LPU的编程模型完全不同(CUDA vs Groq编译器),Dynamo需要在运行时动态选择目标硬件并管理跨硬件的KV Cache传输
- AFD的适用场景有限:只有推理场景受益,训练不需要LPU。这限制了LPX机架的利用率——如果推理负载不足,256个LPU处于空闲状态
- 开放生态竞争:vLLM、SGLang等开源框架也在快速发展PD分离和Wide-EP能力。如果社区方案在特定场景达到Dynamo 80%的性能,部分客户可能选择不绑定NVIDIA全栈
十一、总结与判断
核心结论
-
铜缆时代已进入倒计时。 NVL72是铜缆巅峰,NVL576的正交背板是铜的最后一次大规模应用。正交背板本质上是"铜走线替代铜缆",仍然是铜。2028年后光子学将接管核心互联。
-
超节点扩展从"加机架"转向"加Die"。 NVL576的576个Die在物理上仍在单机柜内。NVIDIA的扩展策略是提升单柜密度,而非增加柜间互联。这是一个根本性的架构哲学转变。
-
GPU+CPU+LPU三芯片架构已成型。 GPU负责训练+Prefill,CPU负责编排+存储管理,LPU负责低延迟Decode。这不是硬件叠加,而是系统级任务解耦。AFD架构只对Agentic推理有意义——训练仍纯GPU。
-
软件栈与硬件同等重要。 从H100到GB300的100倍推理提升中,Dynamo PD分离、Wide-EP、Smart Router等软件优化贡献了约一半。硬件定义天花板,软件决定实际性能。NVL72的硬件优势与Dynamo耦合——没有Dynamo,NVL72只是一个更大的GPU池。
-
NVL144被跳过,说明跨机架铜缆扩展在224G SerDes时代不经济。 NVIDIA选择等待正交背板(Rubin Ultra)和CPO(Feynman)解决Scale-Up扩展。2026-2027年,NVL72是唯一成熟的Scale-Up单元。
-
功耗和供应链是比算力更大的挑战。 400+kW/机柜散热、M9 PCB产能瓶颈、Q布供给限制,这些"非技术"因素可能比芯片设计更影响交付节奏。
-
"8年1000倍"的基线需要审慎看待。 系统级算力确实快速增长,但主要来源正从"芯片更强"转向"系统更大+精度更低+软件更优"。单Die、同精度的实际代际提升在2-3倍。
什么条件下这些判断会错
- 如果CPO量产良率远低于预期,正交背板可能延续到Feynman 架构
- 如果HBM4e产能无法支撑NVL576的1TB/GPU配置,Rubin Ultra规格可能缩水
- 如果推理专用ASIC(Google TPU、AWS Trainium)在特定场景性价比超过LPU,AFD架构推广受阻
- 如果功耗增长速度超过数据中心建设速度,NVIDIA可能被迫推出"低功耗版"超节点
- 如果vLLM/SGLang等开源方案在PD分离和Wide-EP上追赶太快,Dynamo的绑定优势可能被削弱
- 如果Rubin Ultra的2+2模块化封装在系统级PCB上引入过多信号完整性问题,可能回退到单封装4-Die方案(但良率风险更高)
下一个观察节点
- ✅ 2026-05-20:NVIDIA Q1 FY2027 财报已发布 — 核心数据如下:
- 总营收 $81.6B(YoY +85%,QoQ +20%),超指引上限 $78B
- 数据中心 $75.2B(YoY +92%),计算 $60.4B + 网络 $14.8B(YoY +199%,NVLink 爆发验证了文章对互联价值的判断)
- Q2 指引 $91B ±2%,不含中国数据中心收入
- Vera Rubin:Jensen 称 "off to a tremendous start",预期比 Grace Blackwell 更成功,全程供不应求
- Vera CPU:CFO Kress 称打开 $2000亿 CPU 市场,今年目标 $200亿 CPU 收入
- Groq LPU:Jensen 明确定位为 "niche product"——"throughput is low, use case is not broad"(参见 4.3 节更新)
- 报告结构重组:新分为 Hyperscale($38B)+ ACIE($37B)+ Edge($6.4B),Hyperscaler 占数据中心收入约一半
- 中国断供:4月被通知出口需许可证,Q2 指引不含中国数据中心收入
- 2026-06-01~05:Computex / GTC Taipei——更多Rubin架构细节、软件栈更新
- 2026H2:Vera Rubin NVL72量产交付——Dynamo 1.0在260TB/s NVLink域上的实测表现
- 2027H2:Rubin Ultra NVL576预期量产——正交背板方案首次实战、AFD跨硬件编排验证
附录A:配图索引
以下图片来自 NVIDIA 官方或权威技术媒体,对应文章各章节。
图1:GB200 NVL72 机架实物图(NVIDIA 官方)
对应章节:二.1 GB200 NVL72:铜缆的巅峰
来源:NVIDIA 官方产品页
- https://www.nvidia.com/content/dam/en-zz/Solutions/data-center/gb200-nvl2/gb200-nvl72-datacenter-vid-thumb.jpg
- NVIDIA 开发者博客:https://developer.nvidia.cn/zh-cn/blog/nvidia-gb200-nvl72-delivers-trillion-parameter-llm-training-and-real-time-inference/
官方图中可清晰看到18个计算托盘(前部蓝色区域)、9个NVLink交换托盘(中部)和后部Cable Cartridge铜缆托盘。
图2:GB200 NVL72 计算托盘内部(ServeTheHome 拍摄)
对应章节:二.1 计算托盘结构
来源:知乎用户 @Matebook X Pro 解析文章
- https://picx.zhimg.com/v2-15513f7406545571338eb762587f3c9e6_r.jpg (计算托盘实物标注)
- https://pic3.zhimg.com/v2-38d1bb74f556fa9268b25ff1bf05d428_r.jpg (NVL72 整体架构)
可以看到每托盘2×Grace CPU + 4×Blackwell GPU的布局,以及液冷板接口。
图3:NVLink 5 互连拓扑(NVIDIA 官方 GTC 2024)
对应章节:三.1 NVLink 5(Blackwell 架构)
来源:知乎分析
展示72 GPU与18 NVSwitch构成的完全二分图拓扑。
图4:GB300 NVL72 架构(NVIDIA 官方)
对应章节:二.2 GB300 NVL72
来源:NVIDIA 官方产品页
图5:Vera Rubin NVL72 机架(NVIDIA GTC 2026)
对应章节:二.3 Vera Rubin NVL72:无缆化开端
来源:ServeTheHome / NVIDIA GTC 2026
- https://xqimg.imedao.com/19cf90941087c72a3f826a4c.jpeg!800.jpg
- 图中左侧为Vera Rubin计算托盘(带4颗黄色HBM),右侧灰色板为正交背板(Midplane)
图6:Rubin Ultra NVL576 正交背板实物(NVIDIA GTC 2026 黄仁勋展示)
对应章节:二.4 Rubin Ultra NVL576:正交背板革命
来源:雪球用户 ServeTheHome 转载 NVIDIA GTC 2026 照片
- 正交背板(Midplane)实物:黄仁勋在 GTC 2026 上展示的灰色巨大PCB板
- NVL576 Kyber 机架前视图:4个Canister区域,每区域18个计算节点
- ServeTheHome 原文:https://www.servethehome.com/the-nvidia-rubin-nvl576-kyber-midplane-is-huge/
来源:CSDN 架构解析(含NVIDIA官方架构图)
- NVL576 正交架构对比图:https://i-blog.csdnimg.cn/img_convert/25b6718085d5175faeea5f3cf500e9de.jpeg
- NVL576 计算节点内部结构:https://i-blog.csdnimg.cn/img_convert/6ceb7109ff9bfc226556b904390b2bbd.jpeg
- NVL72 vs NVL576 互联方式对比:https://i-blog.csdnimg.cn/img_convert/86a37cf8ccba7b2b2b23fecdc64081d3.jpeg
图7:NVLink 历代性能参数(NVIDIA 官方)
对应章节:三.1 / 三.2 NVLink 演进
来源:腾讯云开发者社区 GTC 2026 解析
- NVLink 历代带宽对比:https://developer.qcloudimg.com/http-save/yehe-1383182/576dcf834fbf322c22d661b4ffeaba34.png
图8:NVL576 Scale-Up 光铜混合架构(NVIDIA/供应链分析)
对应章节:三.3 拓扑扩展 / 十.3 光子学才是终局
来源:雪球技术分析
- NVL576 Scale-Up 光铜混合架构图:https://xqimg.imedao.com/19ca77f6efb640b23fe68620.png!800.jpg
- 正交背板 + CPO 两层互联:https://xqimg.imedao.com/19ca781fffd640bd3fea66a2.png!800.jpg
展示NVL576的第一层PCB正交背板(铜)+ 第二层CPO(光)的Hybrid架构。
图9:Rubin Ultra 封装调整(4-Die → 2+2 模块化)
对应章节:四.1 GPU Die数量悖论
来源:雪球机构分析
- 4-Die → 2+2 封装路径对比:https://xqimg.imedao.com/19d4778da8ad37b63feb101a.png!800.jpg
- 计算板内部布局变化:https://xqimg.imedao.com/19d4778db43d37b73fd78f60.png!800.jpg
2026年3月末供应链反馈:Rubin Ultra从"单封装4-Die"调整为"2-Die基础单元 + PCB/CoWoP 2+2拼接"。总算力不变,但封装复杂度下降,系统级PCB复杂度上升。
图10:GB200 NVL72 液冷系统(NVIDIA 官方/行业分析)
对应章节:七 功耗与散热
来源:网易行业深度分析
图11:NVIDIA Dynamo架构图(NVIDIA 官方)
对应章节:六.2 Dynamo架构
来源:NVIDIA 开发者博客
展示Dynamo的Planner、Smart Router、KV Cache Manager、NIXL四个核心组件及其与推理Worker的关系。
图12:Dynamo 30倍性能提升实测(NVIDIA 官方)
对应章节:五.3 SemiAnalysis基准
来源:NVIDIA 开发者博客
DeepSeek-R1 671B在GB200 NVL72上,Dynamo解耦推理vs传统批处理的吞吐对比曲线。
图13:PD分离 vs 传统推理对比(NVIDIA 官方)
对应章节:六.1 从Triton到Dynamo
来源:NVIDIA 开发者博客
左侧为传统推理(Prefill+Decode同一GPU),右侧为解耦推理(Prefill和Decode分配到不同GPU组)。
注意:以上图片链接来自公开网络,可能存在时效性。如链接失效,建议访问对应原始文章获取最新图片。NVIDIA 官方图片推荐直接访问 nvidia.com 产品页或开发者博客。
附录B:数据来源汇总
| 数据点 | 来源 | 可信度 |
|---|---|---|
| NVL72 130TB/s带宽 | NVIDIA官方 | 高 |
| NVL576 78层PCB | NVIDIA GTC 2026 | 高 |
| DeepSeek-R1 75 tok/s/GPU (GB200) | SemiAnalysis/Signal65 | 中高 |
| DeepSeek-R1 226 tok/s/GPU (GB300) | SGLang/NVIDIA联合测试 | 中高 |
| MLPerf v6.0 8064 tok/s/GPU | MLCommons官方基准 | 高 |
| GB300 vs H100 100x (FP4) | SemiAnalysis InferenceX v2 | 中高 |
| GB300 vs AMD MI355X 28x | Signal65报告 | 中高 |
| Dynamo 30x提升 (DeepSeek-R1) | NVIDIA开发者博客 | 中(官方数据) |
| Rubin Ultra 2+2模块化封装 | 供应链反馈2026.03 | 中(未官方确认) |
| NVL576 MTBF 5000-10000h | 行业估算 | 低(推算) |
| M9 PCB良率60-70% | 供应链估算 | 中 |
| Rubin Ultra功耗400+kW | 推算 | 中低 |