2026年5月25日,华为何庭波在 ISCAS 2026 上发布"韬定律",声称以"时间缩微"替代"几何缩缩"——不依赖更小的制程,靠架构创新提升性能。三天前,北大团队宣布"真3D"EDA 工具原型。再往前一个月,美国 SkyWater 与 MIT/Stanford 联手制造出全球首个碳纳米管单片3D芯片原型。而台积电正在把 SoIC 互连间距从6微米压向4.5微米,英特尔的 PowerVia 背面供电已在 18A 制程上量产。
半导体行业同时在做3D堆叠。但它们做的不是同一件事。
一、封装技术的三代演进
3D集成不是新概念。1970年代末,研究机构就开始在实验室尝试芯片垂直堆叠。但直到2010年前后,台积电推出 CoWoS(Chip-on-Wafer-on-Substrate,在硅中介层上将多颗独立芯片横向排列后通过高带宽互连整合)、英特尔推出 EMIB(嵌入式多芯片互连桥,用嵌入式硅桥代替大面积硅中介层实现芯片间高速连接)、三星推出 I-Cube,先进封装才真正进入大规模商用。
按业界通行划分,3D集成已演进三代:
第一代:封装层面的3D堆叠(并行3D集成)。 代表是 HBM(High Bandwidth Memory,通过 TSV 将多层 DRAM 芯片垂直堆叠的高带宽内存)和 AMD 3D V-Cache。本质是在封装阶段用 TSV(Through-Silicon Via,硅通孔,在芯片上打垂直孔并填充金属导体实现层间电连接)和微凸块连接多个独立芯片。技术成熟,已大规模量产。
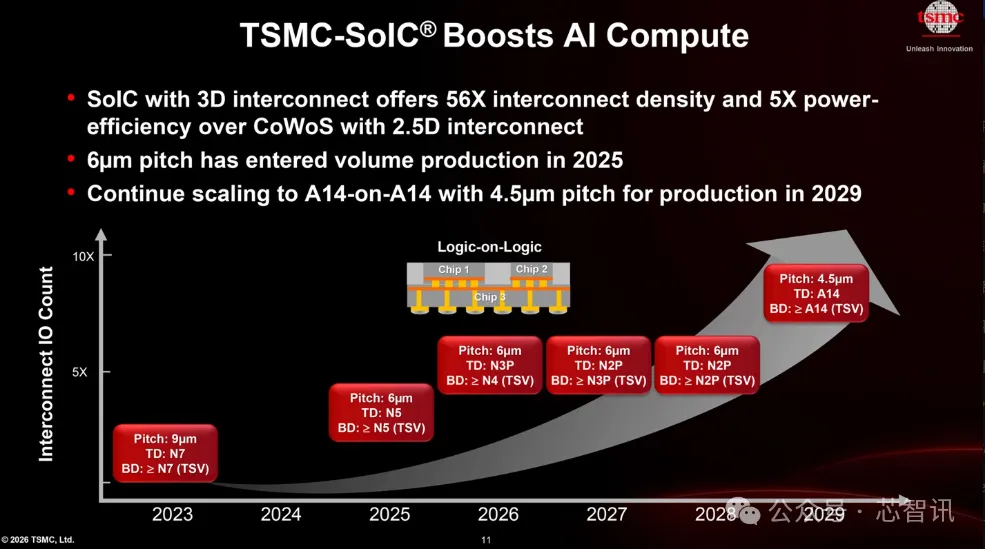
第二代:晶圆级3D堆叠(先进 Chiplet 集成)。 代表是台积电 CoWoS 和 SoIC(System-on-Integrated-Chips,通过混合键合实现晶圆间高密度互连的3D封装平台)。2026年,台积电将 SoIC 互连间距缩短到6微米,目标2029年缩小到4.5微米。更关键的是,第二代技术正从 face-to-back(面对背,信号需穿越底层芯片的 TSV)转向 face-to-face(面对面,两颗芯片的主动金属层直接对齐,通过混合铜键合连接)。博通实测数据显示,面对面堆叠的信号密度达每平方毫米14,000个信号,远超面对背的1,500个——近10倍提升。
第三代:单片式3D集成(M3D,Monolithic 3D Integration)。 这才是"真3D"——在同一晶圆上顺序加工多层有源晶体管,通过光刻级的纳米精度实现层间通信,而非把已成型的独立芯片贴在一起。2025年12月,美国 SkyWater 与 MIT/Stanford 合作制造出全球首个碳纳米管单片3D芯片原型,在90nm工艺上实现了同类2D芯片4倍的性能。
三代之间的本质区别:前两代是把"建好的楼房叠在一起",第三代是"在同一块地基上逐层盖楼"。
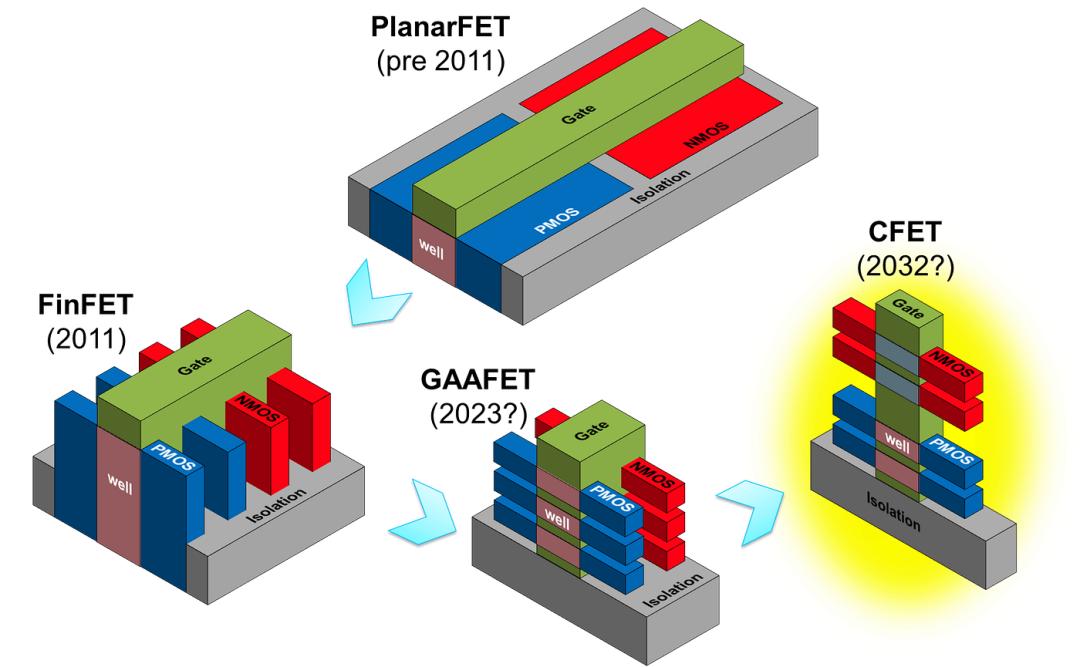
二、当前芯片制造到了什么水平
晶体管架构:FinFET → GAA → CFET
台积电 N2(2nm)和英特尔 18A 是当前最先进的量产制程,两者都从 FinFET(鳍式场效应晶体管,通过竖起的"鳍片"结构在三面控制电流)转向了 GAA(Gate-All-Around,全环绕栅极,栅极四面包裹纳米片沟道,静电控制更精确)。
台积电 N2 在相同功耗下速度提升10-15%,或在相同速度下功耗降低25-30%。三星在3nm就率先采用了 GAA(其 MBCFET 路线),但良率问题削弱了优势。
GAA 之后是 CFET(互补场效应晶体管),将 N 型和 P 型晶体管垂直堆叠,理论上可将晶体管密度再翻倍。imec 的路线图显示,CFET 将在 A14/A10 节点引入,配合 High-NA EUV(高数值孔径极紫外光刻,NA 从0.33提升到0.55,分辨率从13nm提升到8nm)。
背面供电(BSPDN):布线方式的重排
英特尔在 18A 制程上率先量产了 PowerVia 背面供电技术——将供电网络从晶圆正面移到背面,正面空间完全用于信号布线。实测数据显示,GAA + 背面供电可使同等工作电压下运行频率提升25%,或功耗降低36%。
台积电的 A16 制程也将引入"超级电轨"(Super Power Rail)背面供电。野村报告指出,背面供电需要两片晶圆叠加,晶圆消耗量接近翻倍,CMP(化学机械抛光)步骤增加20-30%。
制程路线:三大厂商的分歧
| 厂商 | 当前节点 | High-NA EUV 态度 | 背面供电 |
|---|---|---|---|
| 台积电 | N2(2025量产) | "太贵不买",A13前不需要 | A16引入 |
| 英特尔 | 18A(2025量产) | 最激进,已装机两台 | 18A已量产 |
| 三星 | SF2(2026量产) | 原计划2027,推迟到2029 | SF2Z已引入 |
台积电的逻辑很实际:一台 High-NA EUV 约4亿美元,是现有 EUV 的两倍,已有100+台 EUV 全部更换需要数百亿美元。用成熟 EUV 多重曝光过渡到 A13,等设备性价比合适再考虑。
三、华为韬定律:用架构换时间
核心理念
2026年5月25日,华为半导体业务部总裁何庭波在 ISCAS 2026 上正式发表"韬(τ)定律":以"时间缩微"替代"几何缩微",通过压缩信号在各层级的传播时延(τ = RC,时间常数等于电阻乘以电容),持续提升系统等效性能。
韬定律覆盖四个层级:
- 器件层:优化晶体管和互连的寄生参数,从物理底层降低 τ
- 电路层:逻辑折叠(LogicFolding)——将平铺的逻辑门电路垂直堆叠,缩短关键路径走线
- 芯片层:软硬协同设计,基于实际负载优化指令流和数据流
- 系统层:灵衢总线 + Hi-ONE 光互连引擎,统一系统互联协议
逻辑折叠 vs 传统3D堆叠:不是一回事
这是最容易混淆的部分。很多人认为"逻辑折叠就是3D封装换个名字"。实际上它们作用在不同的技术抽象层级:
| 维度 | 传统3D堆叠(CoWoS/SoIC/Foveros) | 华为逻辑折叠 |
|---|---|---|
| 作用对象 | 多颗独立 die 之间 | 单颗 die 内部逻辑层 |
| 解决的问题 | "不同芯片之间靠多近" | "信号本身要走多远" |
| 技术层级 | 制造/封装工艺 | 芯片设计/电路拓扑 |
| 互连间距 | 6微米(SoIC),几十微米(TSV) | ~1.5微米(层间 TSV) |
| 前提条件 | 需要先进制程配合 | 不依赖先进制程 |

用更直白的类比:3D堆叠是把两栋已建好的楼房用吊车叠在一起,在楼层之间装电梯。逻辑折叠是在设计图纸阶段就把同一栋楼的楼层重新规划,让原来需要坐电梯才能到的房间变成上下楼直接打通。
关键数据: 麒麟2026(首款逻辑折叠商用芯片)在未依赖更先进光刻机的情况下,晶体管密度从 155 MTr/mm² 提升到 238 MTr/mm²(+53.5%),P核能效提升41%,主频达3.1GHz。这个密度接近台积电初代3nm(~280 MTr/mm²),相当于在现有工艺上跳了两代制程。
密度提升的代价:占地面积 vs 硅材料效率
这里有个需要注意的细节。238 MTr/mm² 是"占地面积密度"(footprint density)——即每平方毫米芯片封装面积上有多少晶体管。从用户视角看,手机里那颗芯片确实更小更强了。
但逻辑折叠是用两层有源层垂直堆叠实现的。理论上双层应该带来约100%的密度翻倍,实际只拿到了53.5%——约一半的理论增益被吃掉了。原因包括:层间 TSV 占面积(1.5微米间距阵列本身要占硅面积)、键合界面的对准标记和界面材料、散热通道和热过孔挤占晶体管空间、TSV 从顶层金属下移到 M6 释放了布线资源但 M6 本身有其他用途。
跟台积电3nm做更直接的对比:台积电用单层硅加工艺微缩做到了 ~280 MTr/mm²,华为用接近两倍的硅材料(两层有源层)做到了238 MTr/mm²。从单位硅材料的晶体管产出效率看,逻辑折叠的效率其实低于先进制程微缩。
这并不意味着韬定律路线没价值——恰恰相反,它的价值在于为无法获取先进制程的企业提供了一条可行的性能跃迁路径。只是需要理解,这是一条"用材料换密度"的路线,本质上和摩尔定律的"用精度换密度"在资源消耗维度上有所不同。
堆叠层数:各条路线的天花板在哪
堆叠层数是理解各技术路径天花板的关键参数:
| 技术路线 | 当前堆叠层数 | 短期目标 | 核心限制 |
|---|---|---|---|
| HBM(存储堆叠) | 12层量产(HBM3E) | 16-20层(HBM4) | 热阻累积:底层芯片热量需穿越所有上层才能到达散热器。4层HBM2堆叠内部温差可达24°C |
| 台积电 SoIC(die-to-die) | 2层(面对面) | 更多异构组合 | 每增加一层 die 就多一次晶圆键合,良率损失叠加 |
| 英特尔 Foveros | 2-3层 | Foveros Direct 3层+ | 同 SoIC,但混合键合精度更高(12.5微米间距) |
| 华为逻辑折叠 | 2层有源层(麒麟2026) | 3-4层有源层(论文规划) | 热密度灾难:垂直堆叠有源逻辑层的热量远高于存储堆叠,功耗密度呈几何级暴增 |
| 碳纳米管 M3D | 4层(SkyWater原型) | 理论无上限 | 低温工艺(<200°C)解决了热预算问题,是唯一不受热限制的路线 |
| 3D NAND(参照) | 300+层 | 400+层 | 存储单元发热极低,逻辑层堆叠无法直接类比 |
关键区分:存储堆叠 vs 逻辑层堆叠。 HBM 能堆到12-16层,3D NAND 能堆到300层以上,是因为存储单元发热极低(每层 DRAM 约5-10W,NAND 每层几乎不发热)。逻辑层每平方毫米功耗密度是存储的10-100倍——华为叠两层有源逻辑层就拿到了53.5%的密度提升但也到了手机散热的极限,在数据中心这种散热条件更充裕的场景下才有更多堆叠空间。
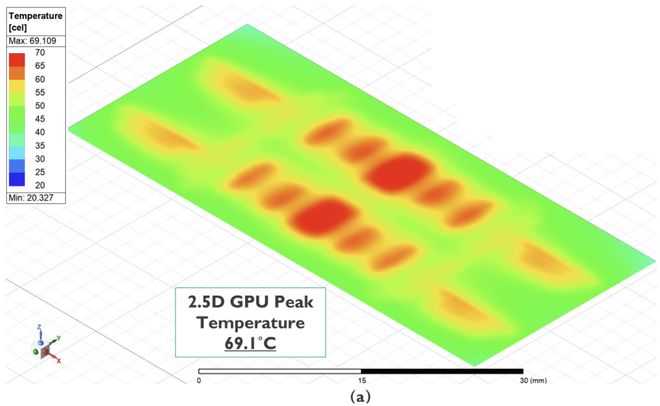
imec 在 IEDM 2025 上发表的研究直观展示了这个天花板:将4个12层 HBM 堆叠直接放在一颗400W GPU 顶部,GPU 温度从70°C 飙升到142°C——远超芯片的80°C工作极限。即使经过移除 HBM 基础芯片、合并堆叠、降频50%、双面液冷等一系列极端优化,也只能将温度压到约70°C。代价是牺牲一半的原始算力,换取内存带宽4倍提升后综合性能提升22%-46%。这说明 HBM-on-GPU 的3D堆叠在工程上"勉强可行",但代价巨大。
不是没有代价
韬定律的"乾坤大挪移"把 EUV 光刻机的难题转移到了3D生态上,但难度并没有降低:
- 热平衡灾难。 垂直堆叠使单位面积功耗密度呈几何级暴增。何庭波自己承认"热问题跨越了12个数量级"。
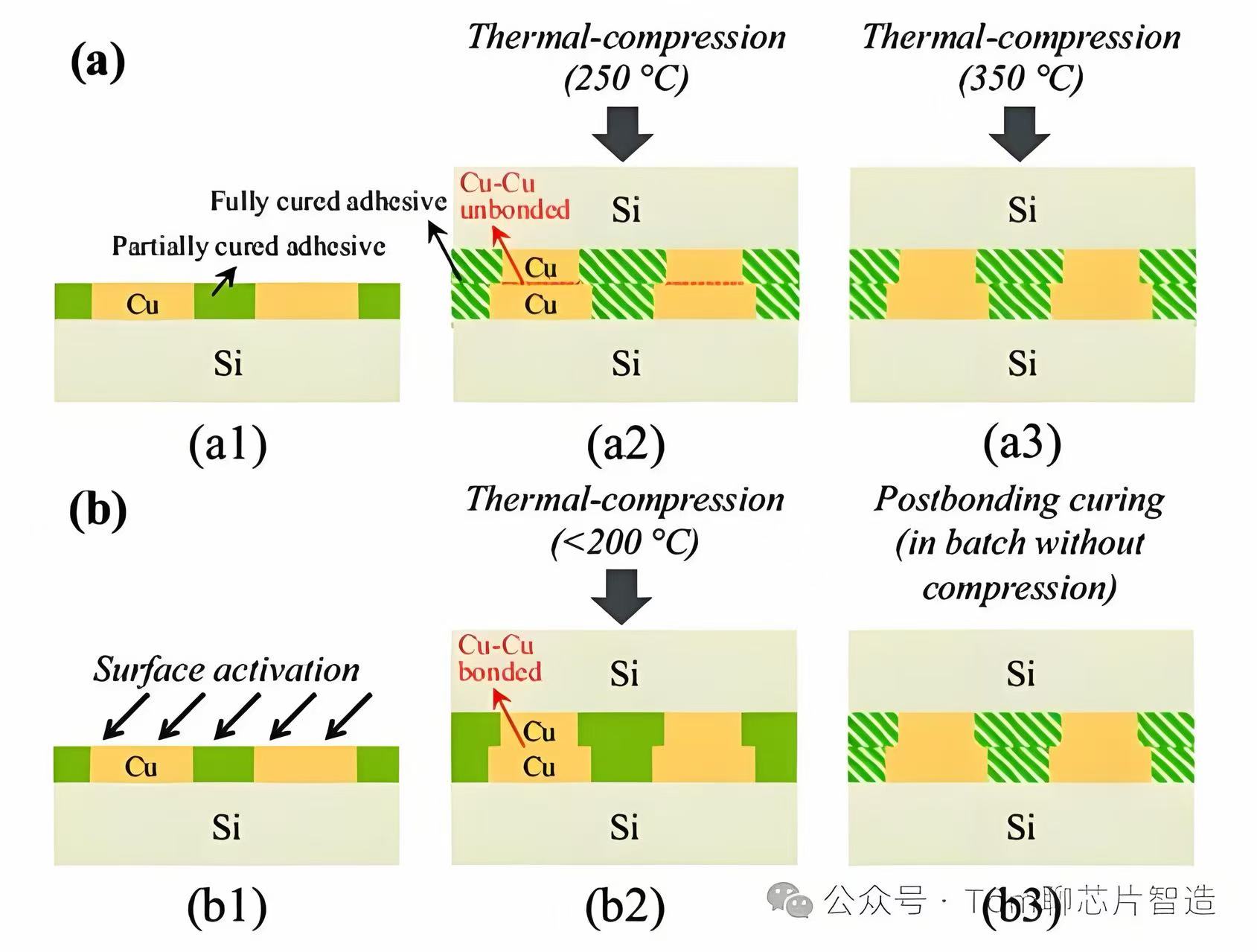
- 工艺和良率黑洞。 异质晶圆键合要求铜焊盘表面粗糙度 <0.5nm,键合对准精度 <50nm,洁净室 ISO 3级。1微米颗粒可导致10mm直径的键合空洞。
- EDA 工具链断层。 主流 EDA 还停留在2D平面时代,3D设计需要把时序、热、电源完整性、信号完整性和机械应力放在三维空间里通盘考虑。北大团队刚发布"真3D"EDA 原型,说明这个问题已被认识到,但离产业化还有距离。
逻辑折叠的工艺流程:比传统2D多了什么
逻辑折叠在生产工艺上比传统2D芯片显著更复杂,但复杂度集中在中后段(MEOL/BEOL/封装),前端晶体管制造(FEOL)基本不变——这正是韬定律可行的关键。
传统2D芯片流程:FEOL(晶体管制造)→ MEOL(局部互连)→ BEOL(金属布线)→ 切割 → 封装 → 测试。逻辑折叠在这个流程基础上增加了多个高难度环节:
晶圆超薄化(新增)。 两层有源层需要各自减薄到20-50μm,厚度控制精度 ±0.2μm(传统±2μm)。减薄后晶圆极脆弱,必须先临时键合到载体晶圆上才能做后续加工。
TSV 制作(大幅增加)。 传统芯片可能完全不需要 TSV;逻辑折叠在 M6 金属层做 TSV,深宽比从5:1提升到20:1,通孔直径1-5μm,侧壁粗糙度 <1nm。昇腾950单颗芯片需要10万+ TSV 通孔。
低温混合键合(新增,最关键)。 两层有源层通过铜-铜直接键合连接,对准精度 ≤0.3μm(传统封装1μm),键合温度 <200°C(保护底层已完成的晶体管),铜焊盘表面粗糙度 <0.5nm。这是整个流程精度要求最高的环节。
临时键合/解键合(新增)。 每层堆叠消耗一次临时键合/解键合循环——减薄前粘到载体上,加工完再剥离(温度 <150°C,翘曲度 <50μm)。
CMP 步骤翻倍。 混合键合对表面平坦度要求极高,CMP 工艺步骤比传统增加20-30%。
测试工序从2次变6次以上。 每层堆叠前要测、堆叠后要测、键合后要测……封测环节工作量成倍增加。
晶圆消耗接近翻倍。 两层有源层意味着每颗芯片消耗约2片晶圆的材料。
| 环节 | 传统2D | 逻辑折叠 | 变化幅度 |
|---|---|---|---|
| FEOL(晶体管) | 正常 | 不变 | 0 |
| MEOL(局部互连) | 正常 | 增加 TSV | +3-5步 |
| BEOL(金属布线) | 正常 | TSV下移到M6 | 改变布线策略 |
| 晶圆薄化 | 不需要 | 20-50μm,±0.2μm | 新增 |
| 混合键合 | 不需要 | ≤0.3μm精度,<200°C | 新增,最大瓶颈 |
| 临时键合/解键合 | 不需要 | 每层一次 | 新增 |
| CMP | 正常 | 增加20-30% | 显著增加 |
| 测试 | 2次 | 6次以上 | 3倍+ |
| 晶圆消耗 | 1片/芯片 | ~2片/芯片 | 接近翻倍 |
核心结论:FEOL 不变意味着不需要先进光刻机。中芯国际现有产线(14nm/28nm)不需要做大的改造。所有新增复杂度都在中后段和封装——恰好是国产替代进展最快的环节。这解释了为什么韬定律对华为是可行的:它把难题从"被卡死的EUV"转移到了"正在快速追赶的先进封装"。
设备瓶颈:哪些需要全新设计,哪些可以改造
逻辑折叠所需设备按瓶颈程度排序:
混合键合设备 — 全新设计,唯一真正的卡脖子环节。 不能从现有设备改造,必须全新制造。全球市场荷兰 BESI 占约67%市占率,前五家占86%。单台售价超1亿元,海外交货周期52周以上。国产进展:北方华创在 SEMICON China 2026 展出 Qomola HPD30,已完成 D2W 混合键合客户端工艺验证(国内首家);拓荆科技有 W2W 量产型号。华为实现的键合间距约1.5μm,已优于台积电 SoIC 当前量产的~6μm。
晶圆减薄设备 — 大幅升级,非完全从零。 传统减薄到~200μm即可,逻辑折叠需要20-50μm。传统设备的主轴精度和冷却系统到不了这个级别,不能简单改造,但减薄设备不像混合键合那样从零开始。华海清科2026年4月刚推出首台超薄减薄设备出机;芯源微、屹唐半导体的12英寸双面减薄机已在长电科技验证通过,良率99.2%。
CMP — 现有设备升级工艺参数和耗材即可。 CMP不是新设备——晶圆厂本来就有大量装机。逻辑折叠对表面粗糙度要求从1-2nm提升到 <0.5nm,主要通过新的抛光液配方和抛光垫实现。华海清科的 CMP 设备在国内已大规模装机,这个环节国产化率较高。
TSV刻蚀 — 现有设备升级工艺参数。 用的是晶圆厂已有的ICP刻蚀机,需要把深宽比从5:1提升到20:1。中微公司、北方华创已有高深宽比刻蚀设备。北方华创 NMC612H 已将深宽比提升到数百比一。
临时键合/解键合 — 较新但原理简单。 这个工艺环节从 CIS 和3D NAND 领域搬过来的,华海清科、芯碁微装已有产品。
| 设备类别 | 全新 vs 可改造 | 国产化进度 | 瓶颈程度 |
|---|---|---|---|
| 混合键合 | 全新 | 北方华创/拓荆已验证 | Critical |
| 晶圆减薄 | 大幅升级 | 华海清科已出机 | High |
| CMP | 升级工艺+耗材 | 华海清科已成熟 | Medium |
| TSV刻蚀 | 升级参数 | 中微/北方华创已有 | Medium |
| 临时键合/解键合 | 较新但简单 | 华海清科/芯碁已有 | Low |
值得后续跟踪的信号: 华为的混合键合间距做到了1.5μm,优于台积电 SoIC 的6μm——要么是设备精度更高,要么是工艺路线不同(W2W vs D2W,或不同的键合方案)。如果国产混合键合设备确实已经支撑1.5μm间距量产,那比外界认知的领先很多。
华为的双轨策略
值得注意的是,华为并非完全排斥碳基路线。韬定律在材料层面涵盖了碳基芯片、碳化硅衬底、磷化铟光芯片等新材料的跨代选择。华为已联手北京元芯碳基集成电路研究院研发碳纳米管晶体管,并联合中芯国际开发碳基3nm GAA芯片。硅基为主、碳基储备。

四、两条路线的对比
美国:碳纳米管 M3D,从材料底层颠覆
DARPA 的 3DSoC 项目(单项资助6100万美元)目标明确:用90nm成熟工艺实现比7nm高50倍的性能功耗比。MIT Shulaker 团队将碳纳米管晶体管(CNFET)与 RRAM 垂直堆叠,形成逻辑-存储交错的3D架构。
碳纳米管的优势:
- 互连密度比 TSV 高10,000倍(MIV 直径~100nm vs TSV 微米级)
- 能量延迟积比硅 CMOS 优越10倍以上
- 低温工艺(<200°C),解决硅基M3D的热预算难题
- 热导率1000-6600 W/m·K,远超铜的~400 W/m·K
但量产仍需5-10年。核心瓶颈:碳纳米管的精准对准与高密度排列、大面积晶圆均匀性、从原型到代工厂的转化。
中国:韬定律 + 硅基3D,用架构创新争取时间
华为的路线更务实:在现有硅基工业基础上,通过设计层面的创新(逻辑折叠 + 光互联 + 系统级协同)实现性能跨越。381款芯片的量产验证是核心论据——这不是实验室概念,而是已跑通工业化量产的工程路线。
两条路线的战略分野:美国是从材料底层发起的战略进攻,试图重新定义芯片制造的根基。华为是在先进制程封锁下的现实突围,以成熟产能和架构创新争取时间与空间。
五、关键判断
确定性最高的趋势
先进封装从"后道配角"升级为"性能决定因素"。 这不是华为一家的判断,而是全行业的共识。台积电 CoWoS 产能三年扩三倍仍供不应求,SoIC 从6微米向4.5微米攻坚,英特尔的 EMIB 开始被 SK 海力士等客户采用——封装环节的战略地位正在快速上升。
背面供电将从2027年起加速量产。 英特尔 18A 已量产 PowerVia,台积电 A16 和三星 SF2Z 将跟进。野村预计2030年背面供电将成为先进芯片标配。
中等确定性的判断
华为韬定律在AI数据中心的价值将远大于消费电子。 AI芯片面积大、芯片间通信密集、散热空间充裕、成本承受力强——这些都是逻辑折叠和3D堆叠的最佳应用场景。华为预计到2035年AI硬件集成度增长100倍以上。
"真3D"EDA 是下一个瓶颈。 北大团队的"真3D"EDA 原型说明产业已认识到这个问题,但从原型到量产级工具还需要3-5年。谁先解决3D设计工具链,谁就在3D芯片竞争中占据主动。

需要持续跟踪的变量
- 麒麟2026的实测表现。 2026年秋季首款逻辑折叠芯片上市,晶体管密度、功耗、散热、良率——这些是检验韬定律成色的关键指标。
- 碳纳米管M3D的产业化节奏。 SkyWater原型是里程碑,但从原型到量产通常需要5-10年。
- High-NA EUV的成本拐点。 如果High-NA EUV被证明成本效益不足,间距微缩不再是关键议题,整个行业将更关注3D结构和封装创新——这对韬定律路线是利好。
- 混合键合的良率爬坡。 台积电 SoIC 从面对背转向面对面的量产良率,直接决定3D封装的普及速度。
数据一览
| 指标 | 数据 | 来源 |
|---|---|---|
| 台积电 SoIC 互连间距(2026) | 6微米 | 台积电2026北美技术论坛 |
| 台积电 SoIC 互连间距(2029目标) | 4.5微米 | 同上 |
| 面对面 vs 面对背信号密度 | 14,000 vs 1,500 /mm² | 博通实测 |
| 麒麟2026晶体管密度 | 238 MTr/mm²(+53.5%) | 华为 ISCAS 2026 |
| 麒麟2026 P核能效提升 | +41% | 同上 |
| 麒麟2026主频 | 3.1GHz(+12.7%) | 同上 |
| 英特尔 18A GAA+背面供电性能提升 | +25%频率或-36%功耗 | VLSI 2025实测 |
| 台积电 N2 vs 3nm功耗改善 | -25~30%(同频) | 台积电官方 |
| SkyWater碳纳米管M3D性能 | 2D芯片的4倍(90nm工艺) | IEDM 2025 |
| SkyWater碳纳米管M3D堆叠层数 | 4层(硅CMOS→RRAM→CNFET逻辑→CNFET传感) | IEDM 2025 |
| HBM堆叠层数(当前量产) | 12层(HBM3E) | SK海力士 |
| HBM堆叠层数(下一目标) | 16-20层(HBM4) | JEDEC路线图 |
| 3D NAND堆叠层数(当前量产) | 300+层 | 三星/SK海力士 |
| 华为逻辑折叠当前层数 | 2层有源层(麒麟2026) | 华为 ISCAS 2026 |
| 华为逻辑折叠演进目标 | 3-4层有源层(10年规划) | 何庭波论文 |
| imec HBM-on-GPU 3D堆叠温度 | 142°C(基准)→~70°C(极端优化后) | IEDM 2025 |
| 华为韬定律目标(2031) | 等效1.4nm,400+ MTr/mm²,主频5GHz | 华为 ISCAS 2026 |
| 3D IC市场规模(2032预测) | ~8,455亿元(CAGR 12%) | 恒州诚思 |
| High-NA EUV单价 | ~4亿美元/台 | ASML |
声明: 本文基于华为 ISCAS 2026 公开演讲、台积电2026北美技术论坛、IEDM 2025 论文、野村证券及高盛研究报告、SemiAnalysis 等多源信息交叉验证后撰写。不构成投资建议。文中数据截至 2026 年 5 月 27 日。