算力不是战斗力:SpaceX Colossus 出租事件揭示的 AI 基础设施真相
22万张GPU建好不到一年就被出租。SpaceX的Colossus出租事件揭示算力拥有与有效使用之间的巨大鸿沟。
22万张NVIDIA GPU,300兆瓦电力,建在田纳西州孟菲斯一座旧家电工厂里。这是Colossus 1,Elon Musk旗下的AI超级计算机,也是全球最大的AI训练集群之一。2026年6月12日,SpaceX以$2.1万亿市值完成IPO,成为人类历史上最大规模的IPO。支撑这个估值的核心故事之一,就是AI算力。
但就在IPO前一天,Bloomberg披露了一个尴尬的事实:SpaceX决定把Colossus 1的全部算力租出去,因为xAI自己的团队在用这套集群训练Grok模型时"遇到了技术困难"。
拥有算力和有效使用算力之间,隔着一整条工程能力、产品能力和商业能力的链路。Colossus 1的出租事件,把这根链路上每个环节的断裂都暴露了出来。
一、事件:一座超级计算机的易主
时间线很清晰。
2025年中,xAI(已并入SpaceX)在孟菲斯极速建成了Colossus 1。22万张GPU,涵盖H100、H200和GB200三代架构,300兆瓦算力,号称从动工到上线只用了几个月。这是Musk式的速度:用涡轮发电机直接烧天然气供电,跳过联邦环评程序,在社区抗议声中强行启动。
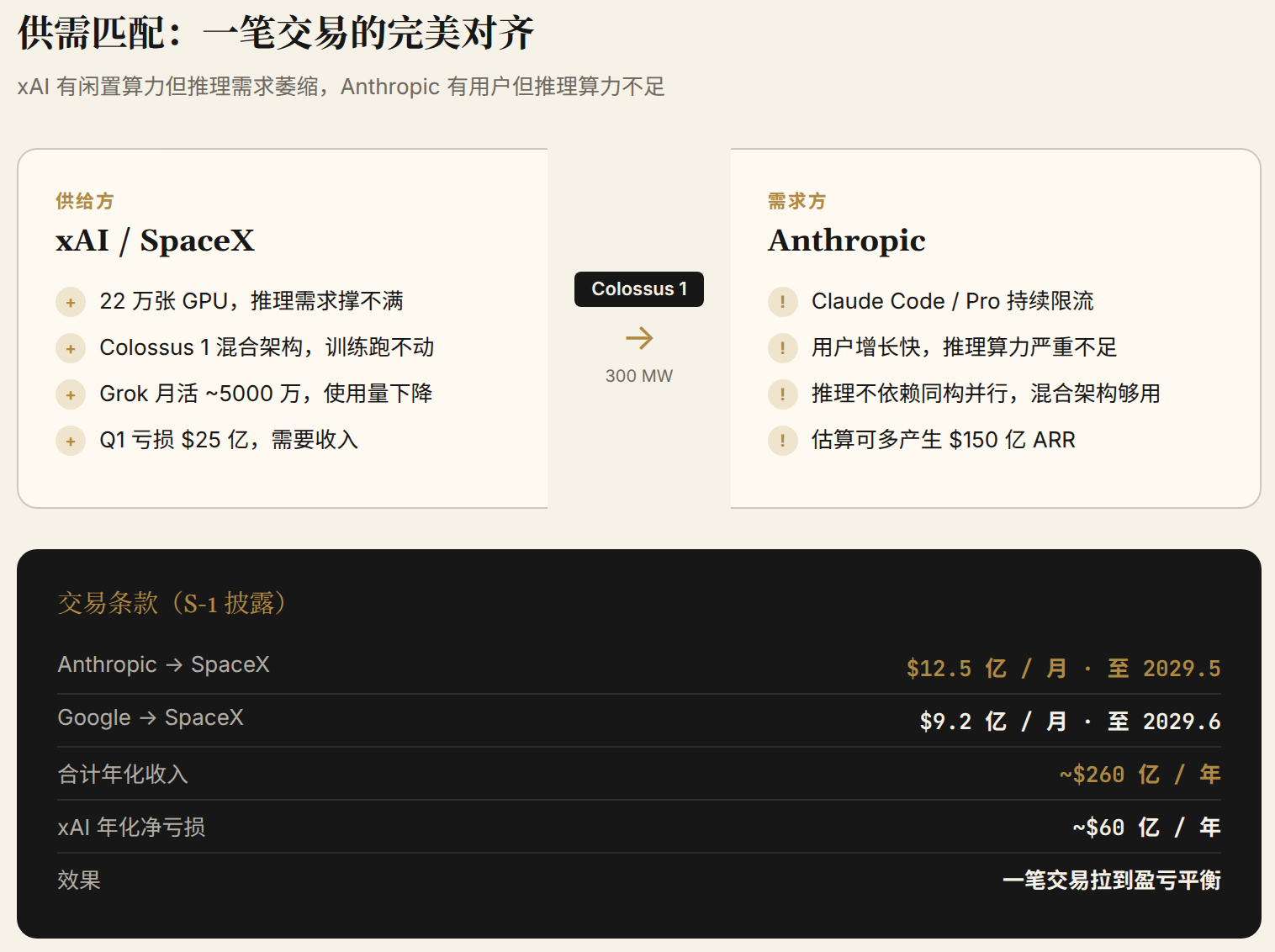
2026年5月6日,Anthropic宣布租下Colossus 1的全部算力。两周后,SpaceX的S-1文件披露了价格:每月$12.5亿,合约期到2029年5月,总金额可能超过$400亿。不久后Google跟进,以每月$9.2亿租下约11万张GPU。
Musk自己在X上说这只是180天短期租约,"如果算力紧张可能收回"。但S-1文件里没有任何短期条款的暗示。90天通知终止权是双向的,但Anthropic和Google不会在刚搬进去的时候就触发退出条款。
关键数据:SpaceX的AI板块在2026年Q1亏损$25亿,收入仅$8.18亿。而Anthropic一个合约的年化收入就有$150亿。
二、技术原因:建得太快,拼装在一起跑不动
Colossus 1被出租不是因为SpaceX大方,而是因为xAI自己的团队用不动它。
Bloomberg的报道用了两个关键词:延迟问题(latency issues)和硬件差异(hardware variations)。Tom's Hardware的分析更直接:Colossus 1的混合架构(H100、H200、GB200三种不同代际的GPU装在同一个集群里)是训练效率低下的结构性原因。
这需要一点背景知识。大规模AI训练(尤其是前沿模型的pre-training阶段)对集群的同构性要求极高。不同代际GPU之间的互联带宽、内存容量、计算精度都有差异。当你把22万张混合架构的GPU组成一个集群做并行训练时,最慢的节点决定整体速度。H100跟不上GB200的节奏,整条流水线被拖慢。这不是软件能解决的问题,是物理层面的架构碎片化。
xAI原本计划将孟菲斯地区的三个数据中心园区(Colossus 1及相邻设施)整合成一个统一的训练集群。但硬件代际差异让跨园区集成无法实现。最终,xAI选择把前沿训练迁移到Colossus 2(统一使用Blackwell架构的新集群),Colossus 1则变成了"第一代资产,寻找更好的用途"。
Tom's Hardware的评价很精准:Colossus 1从"训练资产"降级为"推理资产"。训练需要大规模同构并行,推理不需要。推理是单节点或小规模并行就能完成的任务。一个混合架构集群训练跑不动,推理照样能跑。
Colossus 1从建成到被证明不适合前沿训练,用了不到一年。 22万张GPU的超级集群,折旧周期按5年算,第一年就变成了"二手推理农场"。这不是Musk的个人失误,而是整个AI行业在算力军备竞赛中面临的共同困境:硬件迭代速度(Hopper → Blackwell → Rubin)远快于数据中心建设周期,你今天拼命建的集群,明年就过时了。

三、需求侧:Anthropic为什么急着要
Colossus 1对xAI是"用不动的算力",对Anthropic却是救命稻草。
Anthropic的困境跟xAI正好相反:模型做得好,用户增长快,但推理算力严重不足。Claude Code、Claude Pro、Claude Max持续限流,用户排队等token,产品体验受损。在AI应用层,模型的可用性跟质量一样重要。你的模型再好,用户用不上等于零。
Colossus 1的22万张GPU对Anthropic意味着什么?SemiAnalysis的分析指出:这些额外算力直接转化为Claude Code和Opus的限流缓解。更多用户能用上,更多API请求能处理,更多订阅收入能进来。
这笔交易的精妙之处在于供需的完美匹配:xAI有算力但推理需求萎缩,Anthropic有用户但推理算力不够。Colossus 1的混合架构对前沿训练是缺点(并行效率低),对推理无影响(推理不依赖大规模同构并行)。一个的废物是另一个的宝贝。
Mirae Asset的分析师估算,Colossus 1理论上每年能产生$50-60亿收入,恰好覆盖xAI约$60亿的年化净亏损。而Anthropic拿到这些算力后,估算能多产生$150亿的年化经常性收入(ARR)。一笔交易,双方都拿到了自己最需要的东西。
四、Grok的真实处境:模型不差,但用户撑不满算力
关于xAI为什么要出租算力,外界有两种流行的误读,都需要纠正。
误读一:"Grok太差了所以不需要算力。"
不完全对。Grok 4.3在2026年4月30日发布,支持1M token上下文和原生视频输入。Grok 4 Fast支持2M上下文,输入价格$0.20/1M token,是市场上最便宜的长上下文前沿模型。Grok Heavy($300/月)用并行agent模式,把SWE-bench从~69%拉到~72%。5月还上线了Grok Build 0.1,一个针对coding场景优化的专项模型。
这个迭代节奏不慢。模型质量在第一梯队有竞争力,价格策略甚至比OpenAI更激进。
误读二:"xAI放弃了模型训练。"
不对。xAI的前沿训练在Colossus 2继续。Colossus 2使用统一的Blackwell架构,是专门为frontier training设计和搭建的。出租Colossus 1不等于停止训练,而是把不适合训练的资产转作他用。
真实情况更微妙:Grok的模型迭代速度不慢,但用户规模撑不住22万张GPU的推理需求。 根据第三方估计,Grok的月活用户约5000万。这个数字不小,但跟ChatGPT的8亿+周活相比差了一个数量级。更关键的是,TechCrunch报道指出Grok的使用量在最近几个月"显著下降"。
算力建得比用户增长快。22万张GPU的推理能力,Grok当前的请求量用不完。与其让GPU空转折旧,不如租给最需要的人。
这恰恰说明了一个被行业低估的问题:AI算力的价值实现不在于拥有,而在于有没有足够的用户和产品来消化它。 模型质量好不等于用户多,用户多不等于推理收入能覆盖算力折旧。xAI在模型层面做得不错,但在产品化和商业化层面还在追赶。
Grok缺少的还有企业合规认证——SOC 2、HIPAA这些受监管行业的基本门槛,xAI还没有拿到。这意味着金融、医疗、法律等高价值企业客户基本进不去。Azure和AWS上的GPT系列有全套合规背书,Grok没有。这是制约其推理需求增长的结构性瓶颈。
五、算术:从负债到收入线
把数字摆出来看更清楚。
xAI的财务状况(S-1披露):
- 2026年Q1 AI板块运营亏损:~$25亿
- Q1 AI板块收入:$8.18亿
- 年化净亏损:~$60亿
- Grok使用量:下降中
Colossus 1出租收入:
- Anthropic合约:$12.5亿/月 → 年化$150亿
- Google合约:$9.2亿/月 → 年化$110亿
- 合计年化:~$260亿
一笔出租交易把一个亏损$60亿的板块拉到了盈亏平衡线之上。SpaceX在S-1里把这叫做"dual monetization strategy"(双重变现策略),既做AI模型(Grok),又做算力基础设施(出租GPU)。但subtext很清楚:xAI overbuilt了算力,需要在IPO之前找到变现路径。
IPO估值的支撑:
- 市场定价:$2.1万亿
- Morningstar独立估值:$7800亿
- 差距:~63%
这$260亿/年的出租收入是撑起$2.1万亿估值的关键支柱之一。如果去掉这笔收入,xAI的AI板块就是一个年亏$60亿、用户在下降、模型竞争力尚可但商业化迟缓的story。加上这笔收入,它就变成了一个"AI基础设施平台公司",有$260亿的年化基础设施收入 + 航天业务 + 卫星互联网。
SpaceX本质上在做GPU版的云计算转售。跟AWS卖EC2的逻辑一样:自己用不完的算力,租给别人。区别在于AWS的算力是通用云,SpaceX出租的是AI专用GPU集群,更垂直、更稀缺、更贵。
六、行业信号:资本跑在工程前面
Colossus 1出租事件不是孤例。同一天发生的另外两件事,指向同一个判断。
信号一,Meta开始限制内部token使用量。The Information报道,Meta在内部备忘录中告诉员工减少AI推理消耗,鼓励使用内部MetaCode工具而非外部API。Meta 2026年的内部AI支出预测达到"数十亿"规模。Wired同日报道,Meta三月份成立的Applied AI团队内部怨声载道,项目琐碎,工作"soul-crushing"(灵魂碾压)。芯片整合计划也因Rivos集成困难而暂停。
信号二,KPMG撤回AI好处报告。
Meta是年营收超千亿美元的公司,AI研究预算全球前列。连它都在感受推理成本的压力,说明行业远没到"推理成本不是问题"的阶段。
Financial Times报道,KPMG撤回了一份关于AI商业价值的报告,因为发现报告中的AI采用案例研究似乎是基于AI幻觉编造的。一家全球顶级咨询公司用AI写了一份夸大AI效果的报告,被查出来后撤回。这是一个完美的meta讽刺:AI自己证明了AI采用率数据不可信。
三个信号,一个判断
把这三件事放在一起看:
- SpaceX有22万张GPU但自己的团队用不动。有算力 ≠ 有工程能力
- Meta有千亿AI预算但内部团队士气低落、成本失控。有预算 ≠ 有执行效率
- KPMG有AI报告但内容是AI编的。有数据 ≠ 有真实信号
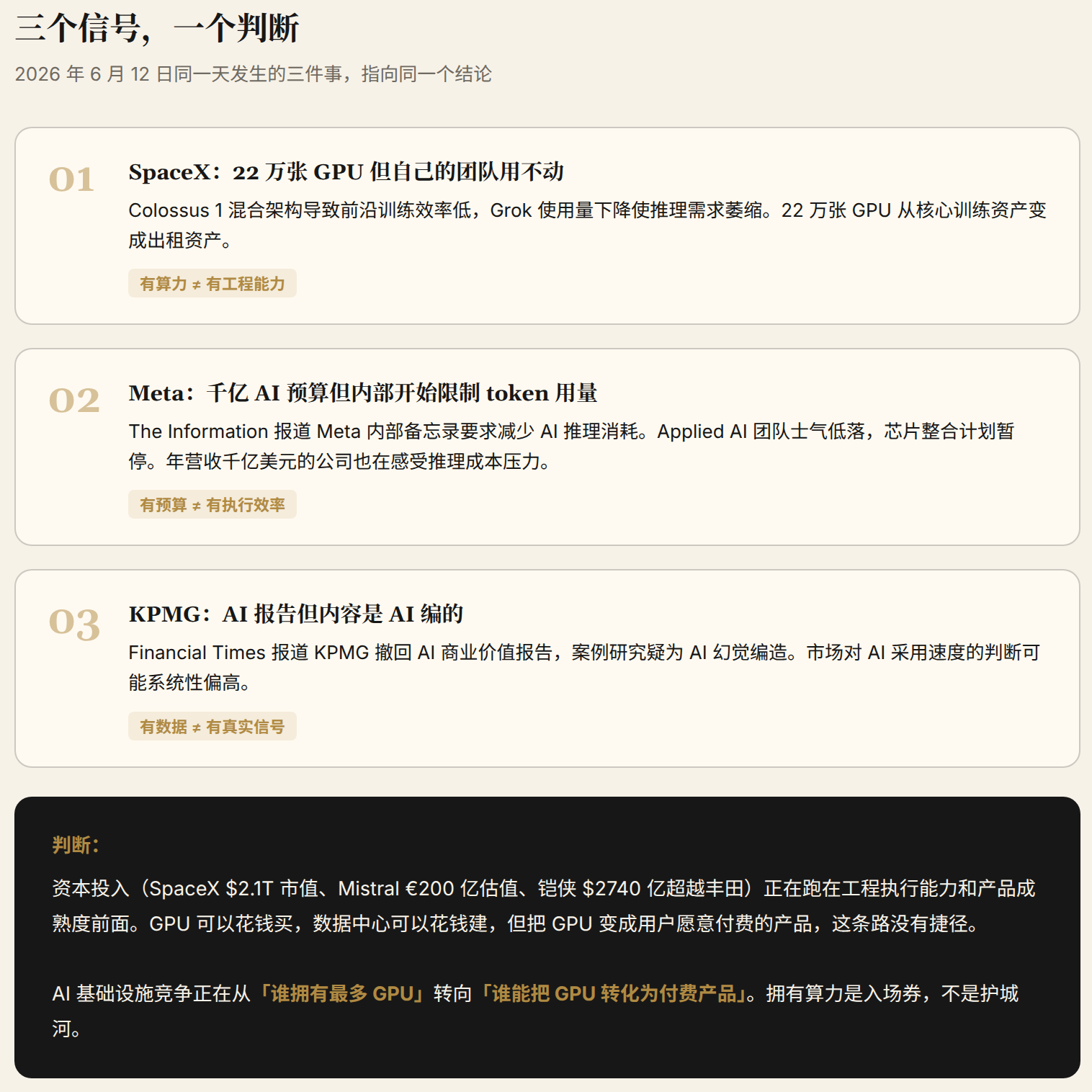
资本的密集投入(SpaceX $2.1T市值、Mistral €200亿估值、铠侠$2740亿市值超越丰田)正在跑在工程执行能力和产品成熟度的前面。GPU可以花钱买,数据中心可以花钱建,但把GPU变成用户愿意付费的产品,这条路没有捷径。
结论:算力是入场券,不是护城河
AI基础设施的竞争正在从第一阶段进入第二阶段。
第一阶段(2023-2025):比谁GPU多、集群大、建设速度快。Colossus 1是这个阶段的典型产物,快、大、猛。
第二阶段(2026-):比谁能把算力转化为用户愿意付费的产品。xAI有算力但用户在下降,Anthropic有用户但缺算力。Colossus 1的出租交易本质上是产业价值链的重新分工:基础设施层(SpaceX)向应用层(Anthropic)卖算力。
Musk在IPO前把Colossus 1租出去,是精明的商业操作:把闲置资产变成招股书里最大的收入增长线。但它也暴露了一个所有AI算力玩家都要面对的问题:硬件迭代速度比数据中心建设周期快。 Hopper → Blackwell → Rubin,每代2年。一个超大规模集群从动工到上线就要1年,上线后第一年可能就因为新一代GPU发布而变成"混合架构低效资产"。
Colossus 1不是失败的实验。它证明了可以在几个月内建成22万张GPU的集群,这本身是工程奇迹。但它也证明了:建得快不等于建得对,拥有算力不等于能从算力中创造价值。
灯塔可以建在陆地尽头,但如果没有船需要它指引,灯再亮也是成本。