开篇:500GB vs 80GB
2026 年上半年,主流大模型的上下文窗口集体冲到 100 万 token。GLM-5.2、Claude Fable 5、DeepSeek V4,全部原生支持 1M 上下文。一个满载 1M 上下文的推理请求,KV Cache(模型推理中存储"已处理上下文"的中间数据)需要多大空间?以 Llama-3-70B 为例,大约 320 GB。一张 NVIDIA H100 的 HBM(High Bandwidth Memory)只有 80 GB。8 卡节点 HBM 总量 640 GB,扣掉模型权重,留给 KV Cache 的空间不到 300 GB——一个请求就接不住。
100 个用户同时发起长上下文请求呢?100 × 320 GB = 32 TB。这个数字放在任何数据中心都是一组机架的显存量。
32 TB 的 KV Cache 缺口,怎么填?
加卡填不了这个缺口。HBM 每 GB 价格 15-40 美元,17 TB 意味着数亿美元的显存开支。真正的答案是一条五层优化链:模型架构压缩每份 KV Cache 的体积,精度编码再砍一半,推理引擎把显存利用率从 30% 拉到 90%,集群架构让 KV Cache 在节点间流动,存储设备层用 SSD 承接溢出的冷数据。每一层缩小缺口,每一层缩小后暴露下一层的结构性问题。
DeepSeek V4 把这条链的终极潜力展示了出来:通过四级混合压缩注意力,V4-Pro 单请求 1M 上下文的 KV Cache 只有 9.62 GB——是同等规模 GQA 方案的 3%。再叠加 FP8 精度、Prefix Caching 和 Prefill-Decode 分离,均摊到每个请求的有效 KV 占用可以低于 1 GB。
这篇文章逐层拆解这条优化链,并在最后给出千卡集群的经济模型和决策框架。
第一章:KV Cache 的本质——为什么它比算力更关键
两阶段推理
大模型推理分两个阶段。
Prefill 阶段处理用户输入的全部 token。模型为每一层 attention 生成 K(Key)和 V(Value)矩阵,写入缓存。一个 100K token 的输入,prefill 一次性产生 100K 份 KV 数据。这个阶段是计算密集型,GPU 算力跑满,每个 token 只写一次 KV Cache。
Decode 阶段逐个生成输出 token。每生成一个新 token,模型都要读取之前所有 token 的 KV Cache 做注意力计算——"回头看"全部历史。这个阶段是访存密集型,计算量只有一层 attention,但需要反复读取全量 KV Cache。瓶颈在内存带宽和容量。
KV Cache 的作用是避免重复计算。不用 KV Cache,生成第 N 个 token 需要重新计算前 N-1 个 token 的 attention,计算量是 O(N²)。用了 KV Cache,每步只需计算新 token 的 K/V 存入缓存,然后做一次 attention,O(N)。实测中,HuggingFace T4 GPU 上用 KV Cache 比不用快 5.2 倍(11.7s vs 61s)。
KV Cache 多大
精确公式:
每 token KV Cache = 2 × n_layers × n_kv_heads × d_head × precision_bytes
2:Key 和 Value 各一份n_layers:模型层数n_kv_heads:KV head 数(GQA 后远少于 query head)d_head:每个 head 的维度precision_bytes:每个数值的字节数(FP16=2, FP8=1, INT4=0.5)
用三个 2026 年的主流模型代入公式,感受一下差距。
Llama-3-70B(GQA 架构,原生 128K 上下文)。 80 层、8 个 KV head、head 维度 128、FP16。每 token KV Cache = 2 × 80 × 8 × 128 × 2 = 327,680 字节 ≈ 320 KB/token。128K 上下文填满后,单个请求 KV Cache = 131,072 × 320 KB ≈ 40 GB。如果强行扩展到 1M token(Llama-3 架构理论上可以,但原生不支持),KV Cache 达到 320 GB。
DeepSeek V4-Pro(混合压缩架构,原生 1M 上下文)。 61 层,但 KV 经历四级压缩(第二章会展开):KV 共享 + c4a 序列压缩(4×)+ c128a 序列压缩(128×)+ DSA 稀疏选择。vLLM 团队实测 BF16 下单请求 1M 上下文 KV Cache 仅 9.62 GB。FP8 attention + FP4 indexer 模式下进一步降到 4.8 GB。
GLM-5.2(GQA 架构,原生 1M 上下文,参数估算)。 约 80-96 层、估计 8-16 个 KV head。按 GQA 8 heads × 128 dim 估算,每 token KV Cache ≈ 328 KB。1M 上下文 = 1,048,576 × 328 KB ≈ 343 GB。
三个模型,三种答案。同样的 1M token 上下文:Llama-3 需要 320 GB,GLM-5.2 需要 343 GB,V4-Pro 只需要 9.62 GB。差距达 35 倍——这还是在模型架构层面的差距,还没开始做推理优化。
模型权重是固定的,KV Cache 随上下文线性增长,随并发数线性增长。这才是矛盾的本质。推理成本的天花板往往不是 GPU 算力(FLOPS),而是"为了装下并发请求的 KV Cache 需要买多少卡"。
在讨论怎么装下这些数据之前,先看清楚当前的存储层次:
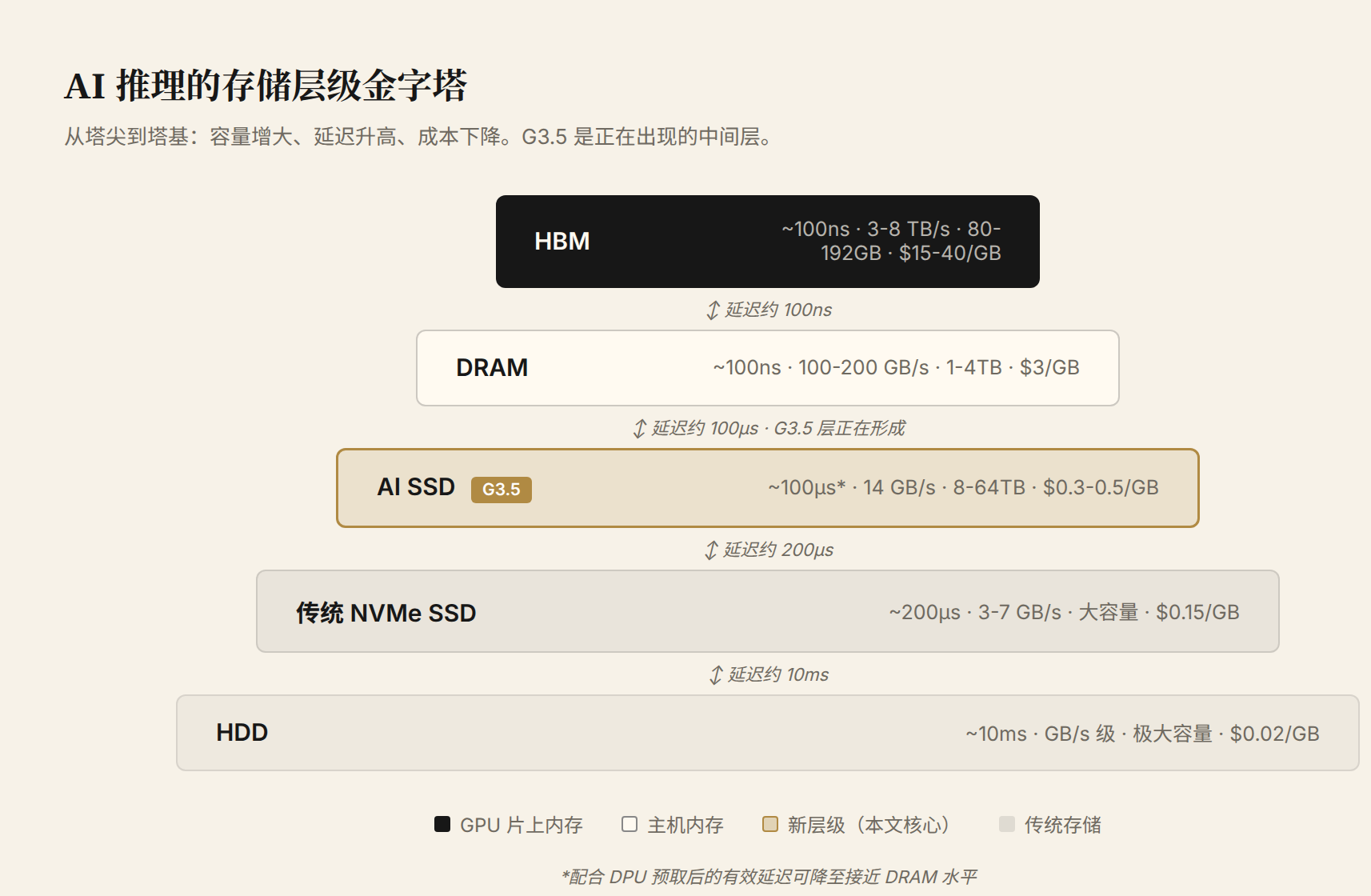
图 1:AI 推理的存储层级金字塔。从塔尖到塔基,容量增大、延迟升高、成本下降。G3.5 是正在出现的中间层,比 DRAM 便宜一到两个数量级,比传统 NVMe 快三到五倍。
塔尖是 GPU HBM,~100ns 延迟、3-8 TB/s 带宽、80-288 GB 容量,最贵。往下是 DRAM,延迟相当但带宽低一个量级,容量可以做到 1-4 TB。再往下是 NVMe SSD 和 HDD。G3.5 层目前还是虚线——它正是第六章要论证其必然性的那个新层级。
第二章:模型架构层——注意力机制的压缩史
Attention 机制的演进史,几乎就是一部 KV Cache 压缩史。每一次架构演进都在改变上一章公式中的 n_kv_heads 或 d_head,甚至改变 KV Cache 的组织方式本身。
| 架构 | 代表模型 | KV Cache 压缩机制 | 每层 per-token 大小 | 相对 GQA |
|---|---|---|---|---|
| MHA | Llama-2, GPT-3 | 无压缩,每个 head 独立 K/V | 2 × n_heads × d_head × 2B | ~2-4× |
| GQA | Llama-3, GLM, Qwen | 多个 query head 共享一组 K/V | 2 × n_kv_groups × d_head × 2B | 1×(基准) |
| MLA | DeepSeek V3 | K/V 联合压缩为低维潜变量 | (d_latent + d_rope) × 2B | ~28% |
| 混合压缩 | DeepSeek V4 | 序列维度压缩 + 稀疏检索 + 滑窗 | ~10 KB (全模型) | ~3% |
MHA → GQA:砍 KV head 数
MHA(Multi-Head Attention)是原始方案。以一个 70B 级模型为例,64 个 attention head 各有独立的 K 和 V 矩阵。每一层每 token 的 KV Cache 是 2 × 64 × 128 × 2 = 32 KB。
GQA(Grouped-Query Attention)的做法:query head 保持 64 个不变,KV head 砍到 8 组。64 个 query head 每 8 个一组共享同一对 K/V。Llama-3-70B 用的就是这个方案。每层每 token 的 KV Cache 降到 2 × 8 × 128 × 2 = 4 KB,是 MHA 的 12.5%。
代价是 attention 的"分辨率"下降。8 组 KV head 要服务 64 个 query head,不同 query head 在同一组 K/V 上做注意力计算,表达力理论上不如每个 head 独立 K/V 的 MHA。但多项实验显示,推理质量损失极小,主流 benchmark 上精度损失不到 1%。这个代价换来 8 倍的 KV Cache 压缩。
GQA 是一次性的架构决策,训练时确定,已有模型不能事后"升级"到 GQA。而且 GQA 压缩到 8 组后,再往下砍(4 组、2 组)精度下降加速。GQA 的红利在 8-16 组附近基本吃完了。
在 1M 上下文场景下,GQA 的局限暴露得很快。Llama-3-70B 的 GQA 架构,1M 上下文单请求 KV Cache 达 320 GB,是模型权重的 4.6 倍。GLM-5.2 的情况更严峻:KV/请求约 343 GB,是权重的 2.0 倍。这两个数字意味着,GQA 架构在 1M 场景下,光装一个请求的 KV Cache 就需要 3-5 个 8 卡 H100 节点。
GQA → MLA:换表示空间
DeepSeek V3 的 MLA(Multi-head Latent Attention)走了根本不同的路。GQA 是减少 KV head 的数量,MLA 是改变 KV 的表示空间。
MLA 的原理:不再为每个 KV head 存储完整的 K 和 V 向量,而是把 K/V 信息联合压缩成一个低维潜变量向量 c_kv(512 维),加上一个解耦的 RoPE key(64 维)。推理时只需要缓存 (512 + 64) × 2 = 1,152 字节/层/token,而不是分别存 K 和 V 两份。需要做注意力计算时,通过上投影矩阵 W_up(512 → 128 heads × 128 dim)恢复出完整的 K 和 V。
每层每 token 的 KV Cache 从 GQA 的 4,096 字节降到 MLA 的 1,152 字节,是 GQA 的 28%。61 层累计,DeepSeek V3 每 token 的 KV Cache 约 70,272 字节 ≈ 68.6 KB,1M 上下文约 72 GB。
代价是上投影的额外矩阵乘法。每层有两个上投影矩阵(分别恢复 K 和 V),维度 512 × (128 × 128) = 8.4M 参数,权重约 32 MB/层。但权重固定,batch 内被所有 token 共享摊销,边际计算开销不到 attention 本身的 5%。5% 的计算换 3.6 倍 GQA 内存压缩。
MLA 的更深层意义在于解耦了"缓存什么"和"计算什么"。GQA 在 head 维度做减法:减少 KV head 数量,attention 的计算路径也相应变窄。MLA 保持 attention 的计算路径完整(128 个 head × 128 维,跟 MHA 一样宽),只压缩缓存内容。这为后续的 V4 混合压缩奠定了思路基础:压缩的重心从 head 维度扩展到序列维度。
MLA → V4 混合压缩:压缩时间序列
DeepSeek V4 引入的混合压缩注意力,把压缩从空间维度(head)扩展到时间维度(序列)。V4 抛弃了 V3 的 MLA,换成一套四级混合栈——不是 MLA 的改良,是全新架构。
KV 共享(2× 节省)。 所有 attention head 共享同一组 Key 和 Value 向量。为了正确性,V4 在 attention 输出处施加 inverse RoPE 操作来恢复各 head 的位置编码差异。共享后,KV Cache 的 head 维度从"per-head"变成"all-shared",直接砍半。
c4a 序列压缩(4× 节省)。 序列维度上,每 8 个相邻 token 的 KV 被加权求和压缩成 1 个条目,stride 为 4(相邻压缩窗口有 50% 重叠)。效果是序列长度维度缩减到 1/4。c4a 处理的是细粒度检索——不是每个 token 都需要独立的 K/V 表示,相邻的几个 token 可以共享一个压缩表示。
c128a 序列压缩(128× 节省)。 更激进,每 128 个相邻 token 压缩成 1 个条目。128 个 token 约等于一段话的长度,一个条目维持全局语义连贯足够了。c128a 处理的是粗粒度全局上下文。
**DSA(DeepSeek Sparse Attention)Top-K 稀疏选择。** 即使 c4a 把序列压到 1/4,1M token 仍有 250K 压缩条目。全做 attention 还是太贵。DeepSeek Sparse Attention 从压缩后的条目中选 Top-1024 个参与 attention 计算。注意力计算量从 O(n²) 降到 O(n×1024),在 1M 场景下等于把计算量砍了两个数量级。
SWA(Sliding Window Attention)滑动窗口(固定 128 token)。 最近 128 个 token 保持全精度 attention,不压缩。语言的自然局部性意味着最近几个句子的关联最紧,这部分不能有精度损失。
V4 的 61 层中,30 层使用 CSA(Compressed Sparse Attention,MLA 组件 + Lightning Indexer(一种轻量级索引器,用于快速定位相关 KV block)),31 层使用 HCA(Hybrid Compressed Attention,c4a/c128a/SWA 混合),两层交错排列。不同机制分工不同:SWA 处理最近 128 token 的全精度 attention,c4a 处理中程稀疏检索,c128a 处理远程全局压缩,DSA 在每层内部决定哪些条目值得 attend。
vLLM 团队在 V4 发布当天验证了实际效果:BF16 精度下,V4-Pro 单请求 1M 上下文的 KV Cache 只有 9.62 GiB。对比同等规模的 V3.2 GQA 方案估算值 83.9 GiB,压缩了 8.7 倍。如果 attention cache 用 FP8、indexer cache 用 FP4,KV Cache 进一步降到约 4.8 GiB。
各架构 1M 上下文全景对比
| 模型 | 注意力机制 | KV/token (FP16) | 单请求 1M KV | 模型权重 | KV/权重比 | 1M 可行性 |
|---|---|---|---|---|---|---|
| Llama-3 70B | GQA (8 heads) | 320 KB | 320 GB | 70 GB | 4.6× | ❌ |
| GLM-5.2 (估) | GQA | ~328 KB | ~343 GB | ~170 GB | 2.0× | ❌ |
| DeepSeek-V3 671B | MLA | 68.6 KB | 72 GB | 671 GB | 0.11× | ⚠️ 勉强 |
| DeepSeek V4-Pro | 混合压缩 | ~10 KB | 9.62 GB | ~800 GB | 0.01× | ✅ 原生 |
这张表的核心信息:KV/权重比从 GQA 的 2-2.4× 降到 V4 混合压缩的 0.01×,差了 200 倍。在 1M 上下文场景下,GQA 架构的 KV Cache 是显存的第一消耗者(比模型权重还大),V4 的 KV Cache 几乎可以忽略(是权重的 1%)。这不是参数调优的差距,是模型设计路线的选择结果。
模型架构层把每份 KV Cache 从 320 GB 压到 9.62 GB,解决了"每份多大"的问题。但用户数量不会因为压缩而减少——"总共有多少份"的问题留给后面的层次。

图 5:Attention 架构 KV Cache 压缩演进。从 MHA 的 512 KB/token 到 V4 混合压缩的 ~10 KB/token,KV/请求在 1M 上下文场景下从 512 GB 降到 9.62 GB。
第三章:精度与编码层——2-4× 即时收益
在不改变模型架构的前提下,通过降低 KV Cache 存储精度来节省显存。这层优化的收益是即时的——改一个配置参数就行——但上限也明确:2-4 倍。
精度阶梯
| 精度模式 | 相对大小 | 精度影响 | 工程成本 | 适用场景 |
|---|---|---|---|---|
| BF16/FP16 | 1× | 基准 | — | 离线、高质量要求 |
| FP8 | 0.5× | 极小(<1% 质量损失) | 极低(vLLM --kv-cache-dtype fp8) |
通用推荐 |
| INT4 | 0.25× | 中等(需校准数据) | 中(校准 + 验证) | 批量任务、短上下文 |
| FP4 Indexer (V4) | 额外 ~2× (indexer部分) | 仅影响 indexer 精度 | 低(V4 专用参数) | V4 专用 |
FP8 是当前工程上的甜点。几乎所有现代推理引擎(vLLM、SGLang、TensorRT-LLM)都默认支持 FP8 KV Cache。精度损失在各种任务上测试过,不到 1%,在长上下文生成任务中用户感知不到差异。开启成本是一个命令行参数:--kv-cache-dtype fp8。
DeepSeek V4 有一个额外的精度选项:FP4 indexer cache。V4 的 CSA 层包含 Lightning Indexer 组件,用于 DSA 的 Top-K 选择。indexer 的 KV Cache 用 FP4 存储,不影响主 attention 精度,但额外节省 indexer 部分的显存。vLLM 参数:--attention_config.use_fp4_indexer_cache=True。叠加 FP8 attention cache + FP4 indexer cache,V4 的 KV Cache 从 BF16 的 9.62 GiB 降到约 4.8 GiB。
INT4 量化更激进,把 KV Cache 压到 FP16 的 1/4。问题在于量化误差在超长上下文下会累积。最后 1% 的 token 可能因为累积量化噪声产生明显偏差。INT4 需要校准数据,不同模型、不同任务的校准参数不能混用。目前 INT4 KV Cache 只适合对质量不敏感的批量任务,或者短上下文场景。
风险
KV 量化的精度损失在超长上下文下被放大。原因不难理解:decode 阶段每步都读取全量 KV Cache 做 attention,量化误差在注意力计算中逐层传播。128K 上下文以下,FP8 的误差基本不可见。但到 512K-1M 范围,FP8 的累积偏差开始出现在长程依赖的召回上——模型偶尔会"忘记"很早之前提到的细节。这个损耗在编程助手场景几乎无感(代码上下文通常在 128K 以内),但在法律文书分析、跨文档推理等超长上下文场景需要验证。
实际部署建议:FP8 作为默认基线,所有场景开启。INT4 仅在显存极度紧张且任务容忍精度下降时使用。FP4 indexer 跟随 V4 的官方推荐开启。
精度层的收益确定且零成本:2-4×,一个配置参数即得。对于 V4 这种 KV Cache 已经极小的模型,FP8 把 9.62 GiB 压到 4.8 GiB,单 GPU 可多服务一倍的 1M 并发请求。
第四章:推理引擎层——把显存用到极致
模型架构决定了每份 KV Cache 多大,推理引擎决定了这些数据怎么被组织和使用。引擎层做的是"把已有的显存用得更聪明",物理显存总量不变,但有效容量可以翻 3-5 倍。
PagedAttention:把显存碎片变成块
vLLM 团队在 2023 年发现了一个尴尬的事实:传统推理框架的显存利用率只有 30-40%。一张 80 GB HBM 的 H100,真正在干活的 KV Cache 数据只有 24-32 GB,剩下 48 GB 在碎片和空等中被浪费了。
根因在内存分配方式。传统框架为每个请求预分配一大块连续的 KV Cache 空间,按最大可能的上下文长度预留。一个请求最终只用了 4K token,但预留了 32K 的空间,28K 的空间空着不能给别人用。请求结束后释放的空间可能不连续——停车场里到处是零散空位,但停不进一辆大卡车。
vLLM 的 PagedAttention 借鉴了操作系统的虚拟内存分页机制。把 KV Cache 切成固定大小的 block,用一张 block table 管理逻辑到物理的映射。请求需要多大空间就分配多少 block,不需要连续物理地址。碎片化浪费从 60-80% 降到 4% 以下。
block 大小是关键调参。太大(256 token/block),小请求浪费尾部空间;太小(1 token/block),block table 自身的内存开销和查找开销上升。vLLM 实测 16 token/block 是传统模型的甜点。但 DeepSeek V4 的情况特殊:c4a/c128a/SWA 三种压缩比导致不同层的 block 物理大小不同。vLLM 的解法是统一 256-token 逻辑块,三种压缩比映射到三种物理 page size bucket,用一个分配器管理三个池。这是 V4 特有的工程挑战,但对使用者透明。
连续批处理
传统 static batching 有个效率瓶颈:一个 batch 内的请求长度不同,短的先完成,但 GPU 资源被长的占用,不能及时插入新请求。Continuous batching 在 iteration 级别调度:每生成一个 token 就检查一次,完成的请求立即移出 batch,等待中的请求立即插入。GPU 利用率从 30% 拉到 70% 以上。所有现代推理引擎已内置。
Prefix Caching:多轮场景的倍增器
多个请求共享同一段前缀(system prompt、文档上下文)时,每个请求都在重复计算同一份 KV Cache。Prefix caching 把这些共享前缀的 KV Cache 缓存起来,新请求命中就直接复用。
不同场景的命中率差异极大:
| 场景 | 典型命中率 | 节省效果 |
|---|---|---|
| API 服务(共享 system prompt) | 30-50% | 中等 |
| 编程助手(多轮对话) | 85-95% | 极大 |
| 文档 RAG(多轮追问) | 80-90% | 极大 |
| 一次性长文档分析 | 0% | 无效 |
编程助手的命中率为什么这么高?看一个实际流程:第 1 轮发送 [system: 8K] [file_context: 40K] [user: 0.5K],prefill 48.5K token。第 2 轮发送 [system: 8K] [file_context: 40K] [turn1: 3K] [user: 0.5K],其中 48.5K 是前一轮的复用,只有 3.5K 是新 token。Prefix Cache 命中,跳过 48.5K 的重复 prefill 计算。
SGLang 的 RadixAttention 把前缀复用做成了基数树(Radix Tree)。每个节点代表一段 token 序列,从根到叶子的路径就是一个请求的完整上下文。两个请求共享前缀就共享树上的一条路径,分叉点就是它们开始不同的位置。查找、插入是 O(L) 复杂度(L 是序列长度),几乎零开销。在 Agent 多轮对话场景(每轮共享之前所有历史),第二轮到第 N 轮的 prefill 计算量减少 80-95%。
引擎层这些优化叠加起来,有效显存利用率从 30% 拉到 90% 以上。同样一组 GPU,能服务的用户数翻了 3-5 倍。但物理显存总量没变——重排货架减少过道浪费能多放 30% 的货,仓库本身没有变大。要扩大仓库,得让 KV Cache 跨出单节点。
第五章:集群架构层——让 KV Cache 在节点间流动
KV Cache 到这里仍被锁在单个 GPU 的 HBM 里。2026 年行业最活跃的方向,就是把它解放成集群级共享资源。
NVIDIA CMX:把 KV Cache 搬出 GPU
2026 年 1 月的 CES 上,NVIDIA 发布了 CMX(Context Memory eXtension)架构。背景是一个工程现实:在 POD 级别的推理集群里,大量 GPU 各自存着重复的 KV Cache 副本。一个 Agent 应用涉及 20 轮对话,每一轮的 KV Cache 都需要在参与推理的 GPU 上保持可访问。多个用户问同一个 Agent?同一个 system prompt 的 KV Cache 被复制了 N 份。
CMX 的核心思路是用 BlueField-4 DPU(数据处理单元)在 GPU HBM 和外部存储之间架一条智能通道,把这些重复的 KV Cache 集中管理。
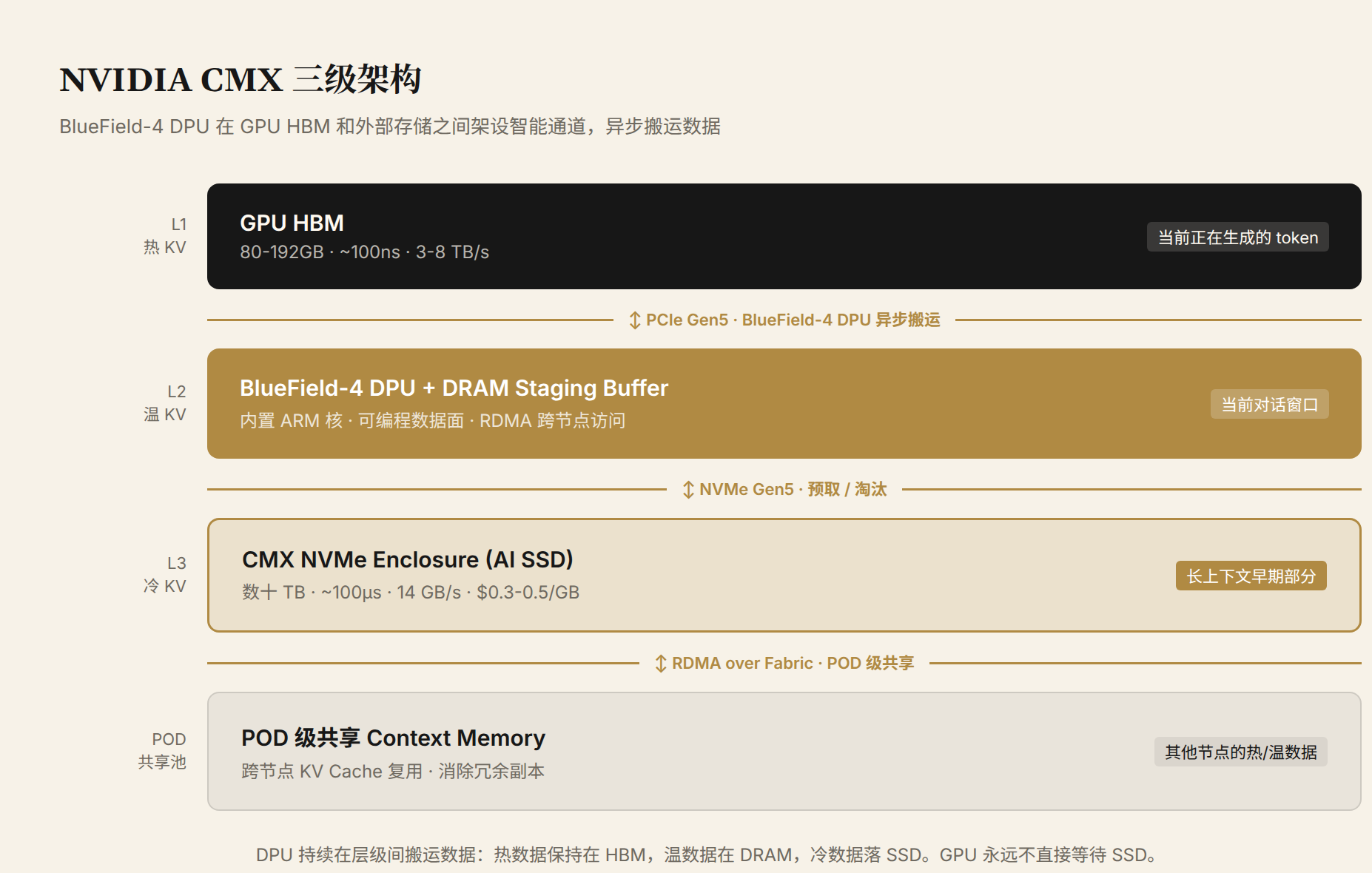
图 2:NVIDIA CMX 架构。BlueField-4 DPU 在每一层之间异步搬运数据。热 KV Cache 留在 HBM,温 KV Cache 放在 DPU 连接的 DRAM staging buffer,冷 KV Cache 落到 CMX NVMe Enclosure 中的 AI SSD。GPU 永远不需要直接等待 SSD 读取。
BlueField-4 DPU 内置 ARM 核和可编程数据面,不需要 CPU 介入就能完成跨节点数据搬运。通过 RDMA,POD 级别的所有 GPU 可以访问同一个 context memory tier。对 Agent 推理场景意义尤其大:一个 Agent 在多轮对话中积累了长程记忆,传统架构下每个参与的 GPU 都要存一份,10 个节点就是 10 份冗余。CMX 架构下,这份记忆存在共享池里,哪个 GPU 当前需要就去读。冗余消失了。
NVIDIA Dynamo:Prefill-Decode 解耦
NVIDIA Dynamo 是其开源的分布式推理框架,2026 年初发布 1.0。关键设计叫 Prefill-Decode disaggregation(预填-解码解耦)。
两个阶段为什么值得拆开?因为它们的硬件负载特征完全相反:
- Prefill 是计算密集型。处理 100K token 的输入需要做 100K 次 attention 计算,GPU 算力跑满,每个 token 只写一次 KV Cache。瓶颈在 FLOPS。
- Decode 是访存密集型。每生成一个 token 要读取之前所有 token 的 KV Cache 做注意力计算,但计算量只有一层 attention。瓶颈在内存带宽。
混在同一个节点上跑,两种负载互相争抢资源。prefill 占满算力时 decode 被挤到等待,decode 占满带宽时 prefill 的矩阵乘法喂不饱 GPU。拆开后,prefill 集群配置高算力 GPU(如 B300),decode 集群配置大容量 HBM + 高带宽。两者之间通过共享存储池传递 KV Cache:prefill 节点生成的 KV Cache 写入共享池,decode 节点从池中读取。
对于 V4-Pro,Prefill-Decode 分离的收益尤其大。V4 的混合压缩注意力让单请求 KV Cache 只有 4.8 GB(FP8+FP4),跨节点迁移一个请求的完整 KV Cache 在 RDMA 网络上只需不到 50ms——远低于 prefill 本身的计算时间。这让大规模分离部署成为工程上可行的方案。
开源 KV Cache 中间件:四个项目
KV Cache 解耦不只是 NVIDIA 的硬件方案。2024-2026 年,开源社区涌现了多个专门的 KV Cache 中间件项目,各自代表了一种技术路线。
Mooncake(Moonshot AI / Kimi)。 目前最完整的 KV Cache 中心化解耦架构,论文发表于 FAST 2025。三个组件:KVCache Store(部署在推理节点闲置 CPU/DRAM/SSD 上的分布式缓存服务)、Transfer Engine(基于 RDMA 的跨节点 KV 搬运,已被 vLLM、SGLang、TensorRT-LLM 集成)、Conductor(全局调度器,根据 KV Cache 分布选择 prefill 和 decode 实例)。论文公布的实测数据:过载场景下吞吐量提升最高 525%,在 Kimi 生产环境中处理请求数增加 75%。核心创新是把 KV Cache 当作一等公民来调度——不是推理引擎的附属品,而是有独立生命周期、可跨节点流动的分布式资源。
LMCache(UC Berkeley)。 走"兼容层"路线,不改推理引擎代码,以 vLLM 插件方式接入。多级 offload 体系:HBM → CPU DRAM → 本地 SSD → 远端存储,基于 LRU(Least Recently Used,最近最少使用)淘汰。后端可插拔:本地 SSD、Redis、GPU Direct Storage、InfiniStore、Mooncake Store。2026 年 3 月被 NVIDIA Dynamo 正式集成为 KV caching 层解决方案。公开 benchmark 显示在不影响生成质量的前提下,最大可服务上下文长度提升 4-8 倍。
FlexKV(Tencent + NVIDIA)。 2026 年 1 月发布,支持基于 Mooncake Transfer Engine 的分布式 KV Cache 复用。与 LMCache 侧重单节点多级缓存不同,FlexKV 侧重集群级的跨实例复用——多个 vLLM 实例可以共享同一个 FlexKV 后端,避免每个实例独立缓存相同的 KV。
NVIDIA Dynamo KVBM。 Dynamo 1.0 中的 KV Block Manager,提供三层架构:LLM runtime → logical block management → NIXL transport,支持 CPU 和磁盘两级缓存。与 Dynamo 的 KV-aware routing 原生集成——调度器知道哪些 KV Cache 块在哪个节点上,路由请求时优先选择已有缓存的节点。
四个项目代表的技术路线对比:
| 项目 | 来源 | 核心创新 | 后端存储 | 集成生态 |
|---|---|---|---|---|
| Mooncake | Moonshot AI | KVCache-as-a-service + Conductor 全局调度 | DRAM + SSD(分布式) | vLLM, SGLang, TensorRT-LLM |
| LMCache | UC Berkeley | 多级 offload + 可插拔后端 | DRAM → SSD → Redis → Mooncake | vLLM, Dynamo |
| FlexKV | Tencent + NVIDIA | 跨实例 KV 复用 | 分布式 KV Store | vLLM, Mooncake Transfer Engine |
| Dynamo KVBM | NVIDIA | KV-aware routing + NIXL 传输层 | CPU + 磁盘 | Dynamo 原生 |
这些项目正在融合而不是竞争。LMCache 可以用 Mooncake Store 作为后端;FlexKV 用 Mooncake Transfer Engine 做传输;Dynamo 同时集成了 LMCache 和 KVBM。最终用户不需要在四个项目中选一个,而是在 vLLM 或 SGLang 之上组合使用这些组件。
商业方案方面,华为的 UCM(Unified Context Memory)/ CMS(Context Memory Service)方案走得更激进。华为公布的数据显示,在 PB 级共享 KV 池配置下,TTFT(首 token 延迟)降低 90%。华为的优势在于自研硬件全栈:从 Ascend GPU 到 SSD 控制器都是自己的。
技术方案深度拆解:一个独立 KV Cache 系统由什么组成
前面梳理了四个开源项目和两条商业路线。要做技术选型,需要更结构化的框架。一个独立的 KV Cache 系统不是单一组件,而是四个根技术的组合:传输、存储、调度、集成。每一层都有独立的技术难点和明确的技术路线分歧。
根技术 1:传输层(Transfer Layer)
传输层解决的问题是:KV Cache 在 GPU HBM、CPU DRAM、SSD、远端节点之间搬移时,如何做到低延迟、高带宽、不阻塞 GPU 计算。
当前主流传输方案有三种。RDMA(Remote Direct Memory Access)走 InfiniBand 或 RoCE,延迟 1-5μs,带宽可达 400 Gbps,是跨节点 KV Cache 迁移的首选。NVLink/NVSwitch 走 NVIDIA 的 GPU 互联,延迟 sub-μs,但只在节点内有效。PCIe 5.0 + GPU Direct Storage 让 GPU 绕过 CPU 直接读写 NVMe,延迟 5-10μs,用于 GPU 到 SSD 的直接路径。
架构抽象上,传输层有两种设计哲学。一种是通用数据搬运:NVIDIA 的 NIXL(NVIDIA Inference Transfer Library)不关心数据是什么,只提供统一的 API 让框架在不同存储层级间搬数据:GPU HBM → CPU DRAM → 本地 NVMe → 远端 RDMA。NIXL 被 NVIDIA Dynamo 采用为底层传输,也可以被 vLLM 独立使用。另一种是 KV Cache 语义绑定:Mooncake Transfer Engine 的 API 按推理引擎理解的 block 单位做迁移,不是按字节拷贝。迁移单位是一个 KV block(通常对应若干 token),传输层知道每个 block 属于哪个请求、哪一层、哪个 shard。这种语义绑定让上层调度可以直接说"把请求 A 的 KV Cache 传到节点 B",不用关心底层怎么切块。两条路径正在融合——Mooncake 的上层调度可以调用 NIXL 作为底层传输。
技术难点有三个。长尾延迟:RDMA 的中位数延迟 2μs,但 P99 可以到 50-100μs(网络拥塞、交换机缓冲区溢出)。Prefill-Decode 分离架构中,一次 KV Cache 迁移如果在 P99 处卡住,decode 节点的 GPU 就要 stall。解法是批量传输 + 流式迁移:逐层传输逐层启动,用流水线隐藏延迟。Mooncake 的 Conductor 原生支持层间流水线。内存注册开销:RDMA 要求传输的内存预先注册(pin 到物理页),大块 KV Cache 的注册本身消耗 CPU 和时间。NIXL 用 on-demand registration + memory pool 预热缓解。多路径负载均衡:单个 RDMA 连接的带宽有限(100-400 Gbps),大集群需要多路径并发。UCCL P2P 等新兴方案用 collective API 自动分配路径。
好的传输层实现的评判标准:(1) P99 延迟不超过中位数的 10×;(2) 单节点有效带宽达到网络理论带宽的 80%+;(3) GPU 利用率不受传输影响(传输与计算重叠);(4) 支持拓扑感知——知道哪些节点在同一 NVLink 域、哪些要走交换机。
根技术 2:存储层(Storage Layer)
存储层解决的问题是:KV Cache 在不同介质(HBM/DRAM/SSD/分布式存储)上的存放、索引、淘汰和一致性维护。它决定了集群的总有效容量和跨层级命中率。
核心是三级存储:GPU HBM 作为 L1(最快、最小、最贵)、CPU DRAM 作为 L2(与 HBM 延迟相当但带宽低一个量级)、SSD/分布式存储作为 L3(大容量、低成本、高延迟)。架构抽象的关键是:每一级对上层暴露统一的 block 接口,内部实现各自的淘汰策略和预取逻辑。
LMCache 的实现最有代表性。它以 vLLM 插件方式接入,不改推理引擎代码,提供 HBM → CPU DRAM → 本地 SSD → 远端存储的多级 offload。每一级之间基于 LRU 淘汰,访问频繁的 KV Cache block 自动提升到更快的层。后端可插拔:本地 SSD、Redis、GPU Direct Storage、InfiniStore、Mooncake Store。2026 年 4 月,LMCache 发布了新架构,引入 In-Process Offload 模式和 Unified KV 模式:前者让 KV Cache offload 在推理进程内完成,避免跨进程通信;后者将多个 GPU 的 KV Cache 统一管理,在 MoE 模型上实测 TTFT 降低 13.6×。
SGLang 的 HiCache 走了另一条路。它把 RadixAttention 从 GPU 内存扩展到三级层级:GPU HBM 是 L1,host memory 是 L2,分布式存储(如 Mooncake Store)是 L3。灵感来自 CPU 的三级缓存:L1/L2 私有于每个 GPU,L3 在节点间共享。HiCache 用 HiRadixTree 跟踪每个节点的 KV Cache 存在哪一级——GPU、CPU、远端存储、或多个层级同时存在。当 GPU 内存满时,HiCache 自动把 block 降到 CPU,再降到 Mooncake,整个过程对推理引擎透明。
技术难点有四个。跨层级命中率:Block 从 GPU 降到 CPU 后,如果另一个请求恰好需要它,需要重新加载。命中率低于 90% 时,有效延迟退回到物理介质水平,推理性能显著下降。提升命中率的关键是预取算法——后面在第六章会展开。淘汰一致性:多级缓存中,同一个 block 可能同时在 GPU 和 CPU 中存在副本。一个副本被修改(如 decode 追加了新 token),另一个副本就是过时的。需要写穿透(write-through)或写回(write-back)策略。LMCache 用 write-back(延迟同步,性能优先),SGLang HiCache 用 write-through(即时同步,一致性优先)。内存开销:缓存元数据(block table、hash、TTL)本身占用内存,在万级并发场景下可以到 GB 级。分布式存储配合(下一个重点)。
根技术 3:调度层(Scheduler)
调度层解决的问题是:在多节点、多请求、多 SLO 约束下,决定每个请求在哪个节点处理、KV Cache 从哪里取往哪里放、prefill 和 decode 怎么配对。这是整个系统信息密度最高的组件——所有传输层和存储层的能力,最终都通过调度层转化为实际性能。
架构抽象上有两种路线。集中式全局调度:Mooncake 的 Conductor 是最完整的实现。每个请求经过三步:第一步,Conductor 检查哪些 prefill 实例已经有可复用的 KV Cache,把可复用的部分传过去;第二步,prefill 实例分层完成计算,同时把输出的 KV Cache 流式传输到选定的 decode 实例;第三步,decode 实例加载 KV Cache,加入 continuous batching。Conductor 的决策目标是最大化 KV Cache 复用同时满足 TTFT 和 TBT(Time Between Tokens,token 间延迟)两个 SLO(Service Level Objective,服务等级目标)。去中心化路由:NVIDIA Dynamo 的 KV-aware routing 不集中调度,而是让每个路由器知道本节点缓存了哪些 KV block。请求到达时优先选择已有缓存的节点,全局都没缓存就选负载最低的节点。去中心化路由比 Conductor 更轻量,但在跨节点复用上不如全局视野。
技术难点有三个。SLO 约束下的多目标优化:最大化吞吐 vs 最小化延迟是经典矛盾。Mooncake 论文给出实用近似解法——对 prefill 调度最大化 cache 复用率(约束 TTFT SLO),对 decode 调度最大化吞吐(约束 TBT SLO),两者独立优化后用 KV Cache 迁移连接。负载倾斜:热门 system prompt 的 KV Cache 被频繁复用,导致部分节点过载而其他节点闲置。Dynamo 用 KV-aware routing + 动态迁移缓解。调度延迟本身:Conductor 的调度决策需要查询全局 KV Cache 索引,万级并发下调度本身的延迟不能忽略。Mooncake 用两级调度(粗粒度节点选择 + 细粒度实例选择)控制调度开销在 1ms 以内。
好的调度层评判标准:(1) KV Cache 全局复用率 >70%(意味着 70% 的请求至少部分命中已有缓存);(2) 调度决策延迟 <1ms(不成为 TTFT 的显著组成部分);(3) 跨节点负载均衡度 CV(变异系数)<0.3。
根技术 4:集成层(Integration Layer)
集成层解决的问题是:KV Cache 系统如何与推理引擎对接,做到对推理引擎透明(不改推理逻辑)同时开销最小(不引入显著延迟)。
当前有两条集成路径。第一条是 vLLM 的 KVConnector 接口:定义了一套标准的 connector protocol,任何 KV Cache 后端只要实现 save_kv()/load_kv() 接口就能接入。LMCache、Mooncake Store、FlexKV 都通过这个接口与 vLLM 集成。第二条是 SGLang 的 HiCache 原生集成:KV Cache 管理内建于推理引擎,不需要外部插件,但只支持 SGLang 自家的 HiRadixTree。
架构设计的核心矛盾是灵活性 vs 性能。vLLM connector 接口跨进程通信,每次 save/load 需要序列化和 IPC 调用,单次开销 50-200μs。对于万级并发场景,这个开销累积显著。LMCache 2026 年 4 月的新架构引入 In-Process Offload 模式来解决这个问题——offload 逻辑在推理进程内完成,零 IPC 开销。SGLang 的原生集成天然没有这个问题(零拷贝),但绑定 SGLang。实际选型中,如果用 vLLM 生态,选 LMCache 或 Mooncake connector;如果用 SGLang 生态,用 HiCache;如果两者混用,用 Mooncake Transfer Engine 作为共享传输层。
技术难点有两个。生命周期同步:推理引擎在每一步 decode 中会产生新的 KV Cache(新 token 的 K/V),集成层需要在不阻塞推理的情况下将这些增量同步到外部存储。异步写入是标准做法,但需要处理写入失败时的回滚。版本兼容:推理引擎升级可能改变 KV Cache 的内部布局(如 V4 的混合压缩引入了多种 block size),集成层需要跟随适配。vLLM 的 connector 接口通过版本协商机制缓解。
好的集成层评判标准:(1) 集成后 TTFT 增加不超过 5%;(2) 支持热插拔(不停服务切换后端);(3) 推理引擎升级时只需修改 connector 适配层,不改核心推理逻辑。
技术选型小结
一个完整的 KV Cache 方案需要回答四个问题:数据怎么搬(传输层)、存在哪里(存储层)、谁来调度(调度层)、怎么接进推理引擎(集成层)。当前主流方案的组合方式:
| 方案 | 传输层 | 存储层 | 调度层 | 集成层 |
|---|---|---|---|---|
| Mooncake | Transfer Engine (RDMA) | DRAM+SSD 分布式 | Conductor 全局调度 | vLLM/SGLang/TRT-LLM connector |
| LMCache | 可插拔(GDS/RDMA/本地) | 多级 offload | LRU + 可选预测 | vLLM 插件 |
| SGLang HiCache | 内置 + Mooncake 后端 | HiRadixTree 三级 | RadixAttention 命中率 | SGLang 原生 |
| NVIDIA Dynamo | NIXL | KVBM (CPU+磁盘) | KV-aware routing | Dynamo 原生 |
没有唯一最优的方案,只有场景匹配。单节点低并发:vLLM 内置 PagedAttention + Prefix Cache 足够。多节点 Agent 多轮对话:SGLang HiCache + Mooncake 后端。千卡集群 PD 分离:Dynamo + NIXL + Mooncake Store。中国环境无 HBM:华为 UCM + 专用 SSD。选型的核心判断是:KV Cache 系统的复杂度应该跟集群规模成正比——过度工程和不充分工程同样有害。
分布式存储与 KV Cache 组件如何配合
根技术 2 中提到 KV Cache 的 L3 层需要落到分布式存储上。但分布式存储系统(如 Ceph、WEKA、VAST、华为分布式文件系统)不是为 KV Cache 场景生的——它们是为传统数据服务(文件、块、对象)设计的。让两者配合好,需要解决三个接口问题。
访问接口匹配。 KV Cache 组件(LMCache、Mooncake Store)需要的是 block 级别的读写:按固定大小的 block 存取,不涉及文件系统语义。传统分布式存储提供的是 POSIX 文件接口或 S3 对象接口,每次读写都要经过文件系统层,开销在毫秒级。解决方案有两个。Mooncake Store 的做法是直接使用本地文件系统(ext4/xfs)+ 直接块设备访问,不走分布式文件系统——它的"分布式"是通过 Transfer Engine 在节点间直接搬数据实现的,而不是通过共享文件系统。LMCache 的做法是可插拔后端:本地 SSD 直接块设备、Redis(内存键值)、GPU Direct Storage(绕过 CPU)等,避免强制依赖特定分布式存储。如果必须用分布式存储(如 WEKA NeuralMesh),需要确认该存储支持 GPU Direct Storage 或 RDMA 直接访问,否则文件系统开销会吃掉性能。
带宽与容量规划。 分布式存储为 KV Cache 服务时,关键指标不是 IOPS(KV Cache 不是随机小块负载),而是持续顺序读取带宽。第六章的推算显示,单个存储节点需要 28-42 GB/s 的持续带宽来支撑预取流水线。这意味着存储集群的聚合带宽需要匹配推理集群的预取需求。经验公式:存储聚合带宽 >= 推理 GPU 总数 × 单 GPU 预取速率(约 1-3 GB/s)。
数据生命周期。 KV Cache 是临时数据,不是持久化数据。推理请求结束后,对应的 KV Cache 应该被回收。传统分布式存储假设数据是长期持有的,垃圾回收机制(GC)的触发频率和粒度不适合高频临时数据。Mooncake Store 通过 LRU + TTL 自动过期处理。LMCache 通过 LRU 淘汰。如果用传统分布式存储,需要显式配置短 TTL(5-30 分钟)和频繁的 GC,否则临时 KV Cache 会快速占满存储容量。
DeepSeek 3FS:原生设计 KV Cache 支持的分布式文件系统。 3FS(Fire-Flyer File System)是 DeepSeek 在 2025 年开源周发布的自研分布式文件系统,GitHub 10K+ stars。它的定位很独特——一个从第一天就把 KV Cache 作为一等公民来设计的存储系统。
3FS 的架构有三个特征跟 KV Cache 场景高度匹配。第一,** disaggregated 架构 + locality-oblivious 访问**:聚合数千块 SSD 和数百个存储节点的带宽,应用不需要关心数据存在哪个节点上。180 节点集群(每节点 2×200Gbps IB + 16×14TB NVMe)的压测读吞吐达到 6.6 TiB/s。第二,CRAQ 强一致性:Chain Replication with Apportioned Queries,不需要最终一致性的模糊窗口,KV Cache block 要么读到最新版本要么读到一致快照。第三,原生 KVCache 接口:3FS 内置了 KVCache 模块,不是外部插件,KV Cache 的读写直接走 USRBIO API 绕过 FUSE 和页缓存,单节点 400Gbps NIC 的 KVCache 读吞吐峰值达 40 GiB/s。
3FS 解决前述三个接口问题的方式值得参考。访问接口层面,3FS 既提供 POSIX 文件接口(给训练 checkpoint 用),又提供 USRBIO API(给 KVCache 直连用),避免了 POSIX 开销。带宽层面,180 节点集群 6.6 TiB/s 的聚合读吞吐,足够支撑万级并发的 KV Cache 预取。数据生命周期层面,3FS-KV 支持基于 TTL 的自动过期,KV Cache block 不会无限累积。
3FS 的局限性在于它是为 DeepSeek 自己的硬件配置(InfiniBand + 大量 NVMe)和模型(MLA/混合压缩架构,KV Cache 天然小)深度优化的。在 GQA 架构 + 以太网环境下,3FS 的优势会打折扣——GQA 的 KV Cache 太大,即使 40 GiB/s 的节点读带宽也很快被并发请求吃满。3FS 的价值更多是验证了一个设计思路:分布式文件系统可以把 KV Cache 当作一种一等数据类型来原生支持,而不是在通用存储上做适配。
推理集群性能调优:关键指标与 KV Cache 效果评估
引入 KV Cache 方案后,怎么知道效果好不好?需要一套可量化的指标体系和对比测试方法。
核心性能指标。
| 指标 | 定义 | 目标值 | 受 KV Cache 影响 |
|---|---|---|---|
| TTFT(Time To First Token) | 用户发出请求到第一个 token 返回 | <2s(8K上下文)/ <10s(1M上下文) | 极大——Prefix Cache 命中可减少 prefill 计算量 |
| TPOT(Time Per Output Token) | decode 阶段每 token 生成时间 | 30-50ms | 中等——KV Cache 读取速度决定 decode 是否 stall |
| 吞吐量 | 单位 GPU 单位时间处理的 token 数 | 越高越好 | 极大——并发数受限于 KV Cache 容量 |
| 并发数 | 同时服务的请求数 | 受限于 KV Cache 总预算 | 直接决定 |
| KV Cache 命中率 | Prefix Cache 或跨请求复用的命中率 | 编程助手 >85%,API 服务 >50% | 直接衡量 Prefix Cache 效果 |
| GPU 利用率 | GPU 实际计算时间占比 | >70% | 间接——引擎优化提升利用率 |
| 显存利用率 | 有效 KV Cache 数据占分配量比例 | >90% | 直接衡量 PagedAttention 效果 |
KV Cache 方案导入前后的对比测试方法。
对比测试的核心原则是:控制变量,只改 KV Cache 配置,其他条件(模型、硬件、负载)不变。
第一步,建立基线。用标准推理引擎(如 vLLM 默认配置,只开 PagedAttention,不开 Prefix Cache / offload)跑一批固定负载,记录上述 7 个指标。负载应该覆盖三种场景:短上下文(8K)、中上下文(64K)、长上下文(256K),用真实请求 trace 或合成数据。
第二步,逐层开启优化,每次只开一个。先开 FP8 KV Cache,测一轮;再开 Prefix Cache,测一轮;再接入 LMCache(CPU offload),测一轮。每轮记录指标变化。
第三步,全量开启,跑混合负载。验证叠加效果是否符合预期。
关键对比指标:
| 优化手段 | 预期 TTFT 变化 | 预期吞吐变化 | 预期并发变化 |
|---|---|---|---|
| FP8 KV Cache | 不变 | +80-100% | +100% |
| Prefix Cache(85%命中) | -60-80% | +20-50% | 不变 |
| CPU Offload(LMCache) | +5-10% | +10-30% | +50-200% |
| PD 分离 | -20-40% | +100-200% | +100-300% |
如果实际提升明显低于预期(如 Prefix Cache 命中率显示 85% 但 TTFT 只降了 20%),说明瓶颈不在 KV Cache 而在别处——可能是 GPU 算力(decode 阶段计算受限)、网络带宽(跨节点传输受限)、或者引擎调度开销。
瓶颈定位方法。
当性能指标不达标时,按以下顺序排查:
- GPU 算力瓶颈:检查 GPU 利用率。如果 >95% 且吞吐不再随并发增加而上升,说明算力已饱和。KV Cache 优化无法解决,需要加 GPU 或换更高性能卡。
- 显存容量瓶颈:检查 OOM 频率。如果并发数增加就 OOM,说明 KV Cache 占满了显存。对策:开 FP8、接 CPU offload、或加 PD 分离。
- 带宽瓶颈:检查 decode 阶段的 GPU 利用率。如果 decode 时 GPU 利用率很低(<30%)且 TPOT 偏高,说明 decode 在等待 KV Cache 读取——访存受限。对策:确保热 KV Cache 在 HBM,检查 DPU 预取命中率。
- 网络瓶颈:检查跨节点 KV Cache 迁移延迟。如果 PD 分离后 TTFT 反而增加了,说明网络迁移延迟超过了 prefill 计算节省的时间。对策:增加 RDMA 带宽、用流式迁移。
- 调度瓶颈:检查请求排队时间。如果请求到达后长时间不被调度,说明调度器成为瓶颈。对策:简化调度逻辑或增加调度器实例。
这套指标体系和排查流程应该是每个推理集群运维文档的标准组件。没有度量就没有优化——KV Cache 方案的效果必须通过数据验证,不能凭感觉判断。
CXL:另一条路径
CXL(Compute Express Link)是一个绕过传统 PCIe 的低延迟互联标准。它的优势是内存语义:CPU/GPU 访问远端 CXL 内存就像访问本地 DRAM 一样,不需要走块设备的协议栈。没有文件系统、没有 IO 队列、没有块设备抽象层,读写请求直达目标地址。延迟在 200-500ns 量级,比 NVMe 快两个数量级。
Marvell 的 Structera S 30260 是专门面向缓存扩展的 CXL 设备。但 CXL 3.0 的实际部署还很少,支持 CXL 的服务器主板、RCD 芯片、内存控制器都处于早期阶段。CXL 内存扩展模块目前主要基于 DRAM,成本仍然是 $3/GB 级别。短期内 NVMe + DPU 的组合因为有成熟的 PCIe 生态和大量现成 SSD 产品,跑在前面。CXL 更像是"再往后一代"的方案,需要等到 2027-2028 年生态成熟。
第六章:存储设备层——当 SSD 变成内存
前五章走完一条完整的优化链:架构压缩把 KV Cache 缩到 GQA 的 3%,精度编码再砍一半,引擎把显存利用率从 30% 拉到 90%,集群架构让 KV Cache 在节点间流动。缺口大幅缩小,但没有消失。100 个 1M 上下文并发请求,即使经过 V4 级别的压缩和池化,仍需数百 GB 的 KV Cache 空间。HBM 和 DRAM 装不下的部分,必须落到下一层介质上。
KV Cache 不是传统存储负载
KV Cache 的读写特征跟传统存储(数据库、文件系统)完全不同,存储介质的选择由访问模式决定。
写入:Prefill 阶段一次性写入整个上下文的 KV Cache,大块、顺序、一次性写完。一个 100K token 的 prefill 产生约 32 GB 数据(70B GQA),之后只在 decode 阶段每步追加一个 token 的增量(~320 KB/步)。不存在传统数据库那样的小块随机写。
读取:Decode 阶段每步读取已缓存的全量 KV Cache 做 attention。但 attention 的访问分布极度不均匀。多项 long-context attention 分布研究发现了一致的模式:attention 权重呈强烈的局部集中趋势,通常 70-90% 集中在最近数 K token 内。超过 16K token 的远程上下文仍然被访问,但权重占比低(10-20%),且访问位置高度稀疏。
| 维度 | KV Cache 需求 | 传统数据库负载 |
|---|---|---|
| 写入 | 大块顺序、低频 | 小块随机、高频 |
| 读取 | 批量、局部集中、可预取 | 随机、不可预测 |
| 容量 | 单节点 0.5-2TB | 单节点 4-16TB |
| 延迟敏感度 | 有效延迟需 < 10ms | 可容忍 10-100ms |
为什么 SSD 的有效延迟可以逼近 DRAM
SSD 的物理访问延迟在 100μs 量级,DRAM 大约 100ns,差 1000 倍。直接拿 SSD 当内存用,推理会被拖垮。但实际部署中,SSD 的有效延迟可以逼近 DRAM——秘密在于 attention 的访问模式。
答案在于 attention 的访问模式 + DPU 预取流水线。
热数据(70-90% 的访问)= 最近数 K token 的 KV Cache。70B GQA 模型,16K token 的 KV Cache 约 5 GB,完全可以放在 HBM 或 DRAM 中,100ns 延迟。
冷数据(10-20% 的访问)= 热窗口之前的全部上下文。1M token 减去 16K ≈ 1M token 的 KV Cache,这部分数据大部分时间不被访问,存放在 SSD 上不影响推理速度。
关键问题变成:当 attention 确实需要访问冷数据时(那 10-20% 的长程依赖),SSD 的 100μs 延迟会不会造成 GPU stall?
这就是 DPU 预取发挥作用的地方。BlueField-4 DPU 在 GPU 还在处理当前 token 时,已经把下一批可能被 attention 访问的冷 KV 块从 SSD 预取到 DRAM staging buffer 里。预取策略有三层:
- 滑动窗口预取:维护一个不断移动的热数据窗口(当前 decode 位置前方 4-16K token),窗口内的 KV Cache 始终保持在 DRAM 中。
- Attention pattern 预测:对于已知的 attention pattern(如 Agent 多轮对话中反复引用的早期上下文),DPU 提前把对应 block 搬到 DRAM。
- Cross-request 复用:多个用户共享同一段上下文时,只预取一份到共享池。
预取效果用数学验算。假设 DPU 维护一个 4K token 的预取窗口,70B GQA 模型,每 token KV Cache 320 KB。窗口总量 = 4096 × 320 KB ≈ 1.3 GB。PCIe 5.0 NVMe 顺序读取带宽 14 GB/s,搬运耗时 ~93ms。而 decode 消耗这 4K token 需要多长时间?每步 10-30ms 生成一个 token,4K token 需要 40-120 秒。SSD 有 400-1200 倍的时间余量来完成预取。
DPU 不需要在 GPU 需要数据时才去 SSD 读,而是在 GPU 还在忙于当前 token 时就提前把下一批数据搬好了。等 GPU 真正需要这些数据时,它们已经在 DRAM 里了。GPU 看到的有效延迟接近 DRAM 水平(~100ns),而不是 SSD 的物理延迟(~100μs)。
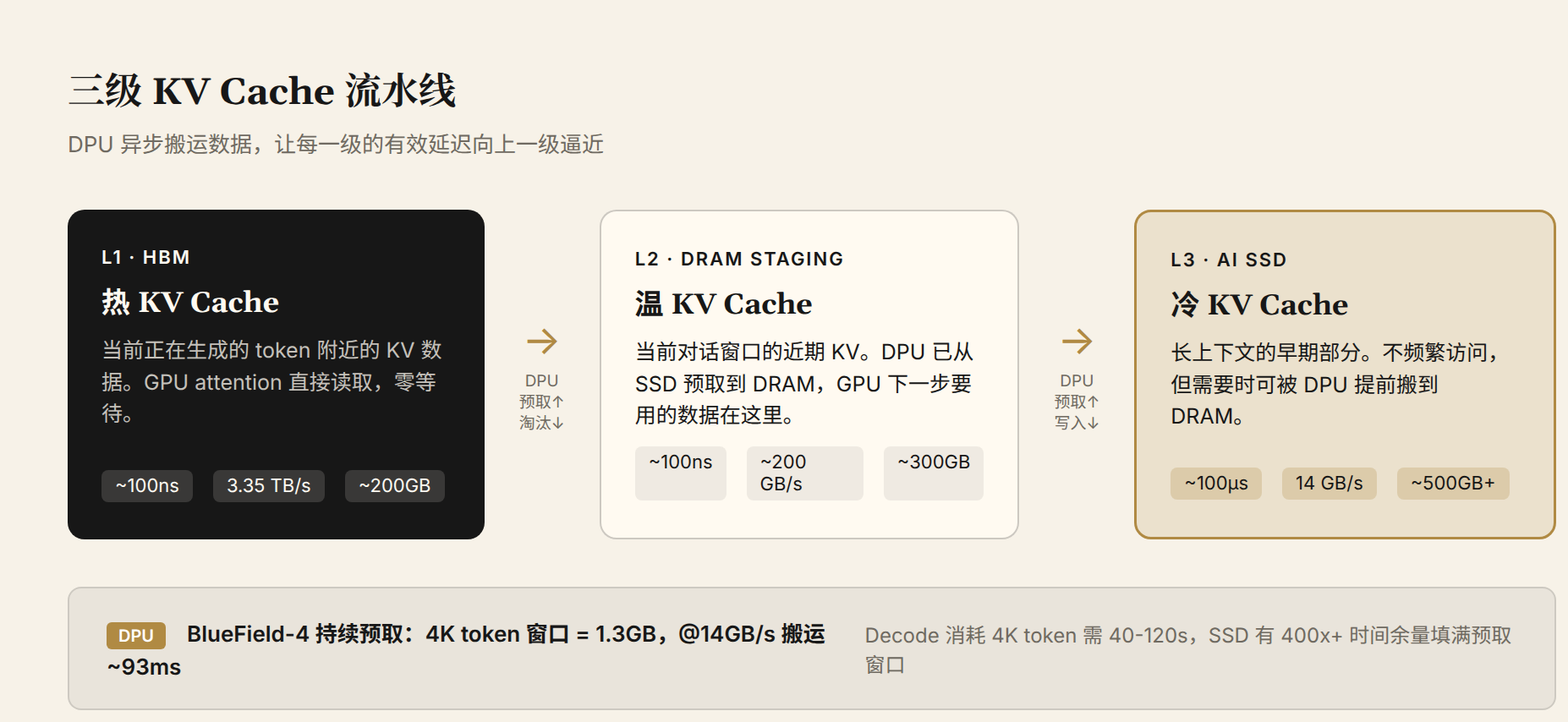
图 3:三级 KV Cache 流水线。最热的 KV Cache(当前 attention 窗口)在 HBM;温数据(预取窗口)在 DPU 连接的 DRAM staging buffer;冷数据(长上下文的早期部分)在 AI SSD。DPU 异步搬运数据,让每一级的有效延迟向上一级逼近。
NVIDIA 在 ICMSP 2026 上公布的 CMX 架构数据显示,在 128K 上下文场景下,DPU 预取命中率达到 90%+。未被命中而退回 SSD 物理延迟的访问不到 10%。这 10% 的 miss penalty 被 attention 计算的异步流水线部分吸收,GPU stall 时间控制在可接受范围内。从 90% 到 95% 需要三个软件层面的突破:基于 attention pattern 的访问预测(超越 LRU)、token 级预取粒度、跨请求 KV Cache 复用调度。三点都是软件问题,不需要新硬件。预计 12-18 个月收敛。
新品类:AI SSD
当 SSD 的角色从"存数据的仓库"变成"参与计算的内存扩展层",一个新的产品品类正在形成。
铠侠 CM9 是支持 CMX 架构协议的企业级 SSD,PCIe 5.0 接口,顺序读取带宽 14 GB/s。铠侠还推出了 GP Series(直接连接 GPU 的闪存产品),这才是真正定义新品类的硬件——绕过传统 SSD 控制器、直接与 GPU 交互的低延迟闪存层。铠侠有 NAND 产能优势(全球第二大),没有 HBM 业务,不会自我蚕食。如果 G3.5 成为一个真实的品类,铠侠是赌最大的。
英韧科技洞庭 N3X 把参数拉得更激进:14 GB/s 读取、3500K IOPS、高耐久度。使用铠侠 XL-FLASH 存储级内存而非普通 NAND,延迟控制在传统 TLC SSD 的三分之一,DWPD(Drive Writes Per Day,每日写入次数)较传统企业级 SSD 提升 30 倍以上。传统企业级 SSD 的 DWPD 通常在 1-3,提升 30 倍意味着这些盘面向 KV Cache 场景中持续大块顺序写入设计,不是传统数据库的随机写入场景。
大普微 X5 主打 FDP(Flexible Data Placement)加透明压缩。FDP 让 SSD 控制器更高效地管理闪存块分配,把写放大控制在 1.5× 以下。透明压缩在控制器层面实时压缩写入数据,KV Cache 中重复的 attention pattern 有不错的压缩率,实际可用容量大于标称容量。
Solidigm D5 走 QLC 大容量路线,单盘容量可以做到 60TB+,$/GB 成本极低,适合作为 KV Cache 分层中的最冷一层。
行业格局:谁激进,谁保守
三星和 Solidigm(SK 海力士 + Intel NAND 合资体)都在 ICMSP 验证列表里,但都没有高调发布"AI SSD"品类。原因不难猜:两家都有大量 HBM 业务。2025-2026 年 HBM 产能供不应求,ASP 持续走高。主动推广"用 SSD 替代部分 HBM"的叙事,等于在蚕食自己最赚钱的产品线。
美光走了另一条路,重心放在 CXL 上。CXL 的内存语义访问天然比 NVMe 更适合"当内存用",但生态成熟还需要时间。
中国厂商是最激进的。英韧、大普微、加上华为的 UCM 方案,在 CFMS|MemoryS 2026 峰会上密集发布产品和方案。原因很简单:中国厂商买不到先进 HBM。出口管制把 HBM 的获取通道卡得很窄。中国厂商的推理方案(如华为 Ascend + UCM)本来就没有 HBM,SSD 是唯一大规模可得的存储介质。G3.5 对它们不是"替代 HBM",是"本来就没有 HBM,SSD 是唯一选择"。
成本对比:G3.5 存在的商业理由

图 4:各存储层级的成本与性能对比。注意 HBM 与 AI SSD 之间 $/GB 差距达到 30-130 倍。
| 层级 | $/GB | 相对 HBM | 单节点容量 | 延迟 | 带宽 |
|---|---|---|---|---|---|
| HBM | $15-40 | 1× | 80-288 GB | ~100ns | 3-8 TB/s |
| DRAM | $3 | 便宜 5-13× | 1-4 TB | ~100ns | 100-200 GB/s |
| AI SSD (G3.5) | $0.3-0.5 | 便宜 30-130× | 8-64 TB | ~100μs* | 14 GB/s |
| 传统 NVMe SSD | $0.15 | 便宜 100-260× | 大 | ~200μs | 3-7 GB/s |
*配合 DPU 预取后的有效延迟可降至接近 DRAM 水平。
HBM 每 GB 价格 15-40 美元,AI SSD 每 GB 只要 0.3-0.5 美元,差了 30 到 130 倍。一个需要存 1 TB KV Cache 的场景,用 HBM 需要等价于约 13 块 H100 的显存(每块 $30,000+),用 AI SSD 只需要 $300-500 的磁盘。这个成本差距就是 G3.5 层存在的商业理由——它不是为了取代 HBM,而是承接那些放不进 HBM、但延迟敏感性又高到不能丢进传统存储的 KV Cache 数据。
第七章:集群经济与决策框架
千卡 B300 × V4-Pro 集群实例
把五层优化放到一个真实集群里算账。
NVIDIA B300(Blackwell Ultra)规格:288 GB HBM3e、8 TB/s 带宽、13.1 PF dense FP4、NVLink 5 双向 1.8 TB/s、1400W 液冷。一个 1000 卡集群 = 125 个 8-GPU 节点,总 HBM 288 TB,总 FP4 算力 13.1 EF。
DeepSeek V4-Pro 权重以 FP4 原生加载。专家并行(8路)下,每 GPU 承载约 91 GB 专家权重 + 150 GB dense 层权重(全复制)+ 5 GB embedding ≈ 155 GB。运行时开销约 25 GB。每 GPU 可用 KV Cache 预算:
288 GB (HBM) - 155 GB (权重) - 25 GB (运行时) = 108 GB
保守按 110 GB 计
单 GPU 并发容量
| 上下文 | KV/请求 (BF16) | KV/请求 (FP8+FP4) | 并发 (BF16) | 并发 (FP8+FP4) |
|---|---|---|---|---|
| 32K | 0.30 GB | 0.15 GB | 333 | 666 |
| 128K | 1.20 GB | 0.60 GB | 83 | 166 |
| 256K | 2.41 GB | 1.20 GB | 41 | 83 |
| 512K | 4.81 GB | 2.40 GB | 20 | 41 |
| 1M | 9.62 GB | 4.80 GB | 10 | 20 |
千卡集群(125 副本)在 1M 上下文 + FP8+FP4 模式下,总并发 = 20 × 1000 = 20,000 个 1M 并发请求。
对比 GQA 架构:同样 1000 张 B300,跑一个 GLM-5.2 级别(GQA,KV/请求 343 GB),单个 1M 请求就需要 343/110 ≈ 4 张 GPU。1000 张 GPU 只能跑 250 个 1M 并发——差了 80 倍。
五层叠加效果
从裸跑到全优化,V4-Pro 1M 上下文的 KV Cache 变化:
| 优化层 | 手段 | KV/请求 | 累积压缩比 |
|---|---|---|---|
| 裸 GQA 等效 | 无 | ~320 GB | 1× |
| + 架构压缩 | V4 混合注意力 (BF16) | 9.62 GB | 33× |
| + 精度压缩 | FP8 + FP4 indexer | 4.80 GB | 35× |
| + Prefix Cache | 85% 命中率(多轮场景均摊) | 0.72 GB | 236× |
| + Prefill-Decode 分离 | 吞吐 +2-3× | — | ~500× 有效 |
裸 GQA @ 1M:320 GB/请求,1000 卡跑 ~340 并发(110,000 GB / 320 GB)。 V4 全优化 @ 1M:~0.7 GB/请求(均摊),1000 卡跑 ~157,000 有效并发。
这 460 倍的差距,就是模型架构选择 + 推理工程 + 集群架构的叠加价值。
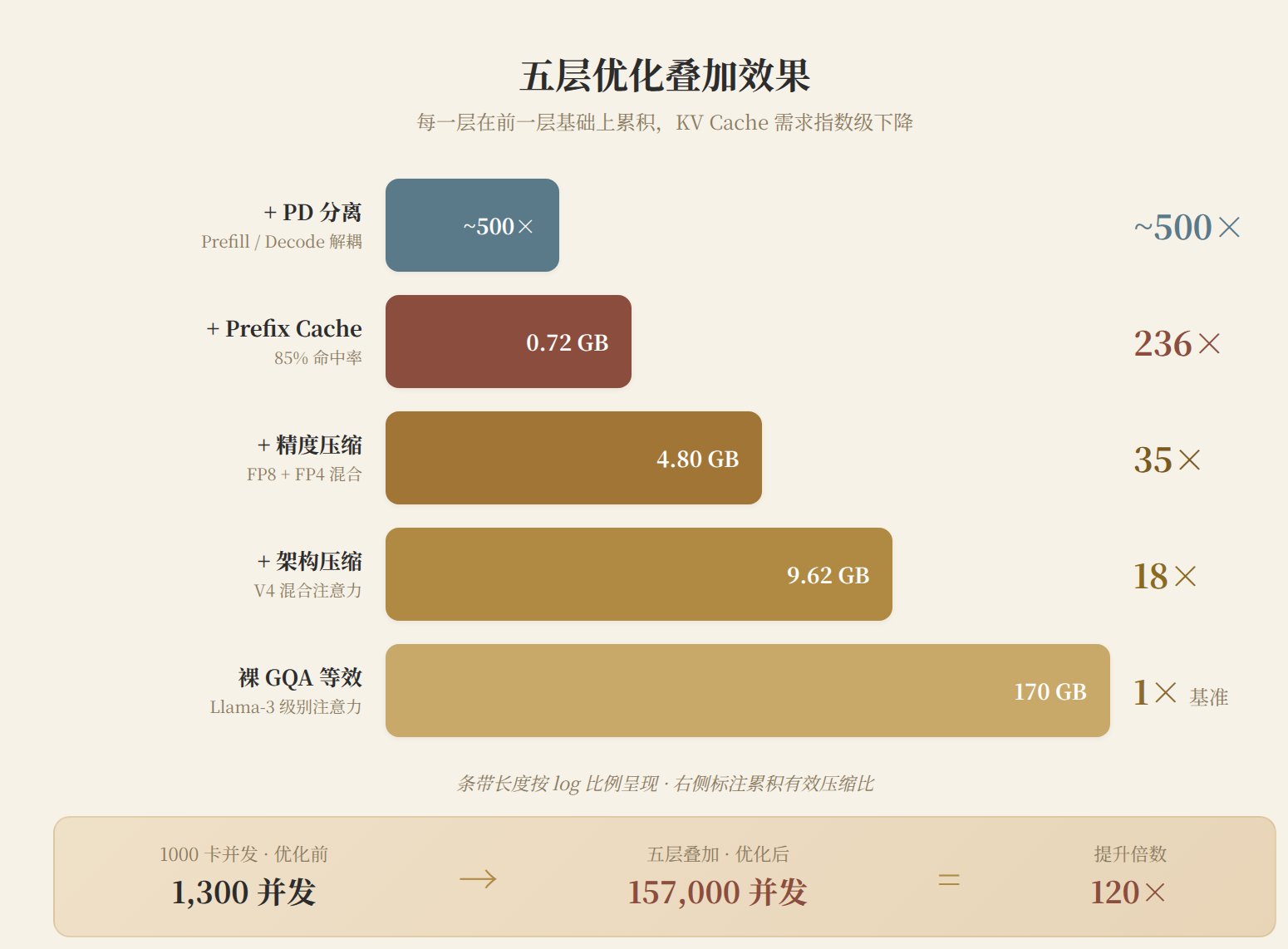
图 6:五层优化叠加效果。从裸 GQA 的 170 GB/请求到全优化的 ~0.7 GB/请求(均摊),累积压缩 500 倍。千卡集群的有效并发从 340 拉到 157,000。
决策框架:什么时候做什么
KV Cache 加速是必选还是可选?
这个问题有一个清晰的量化答案。判断标准是:KV Cache 优化后的 GPU 节省 >= 优化成本的 1.5 倍。超过这个拐点,不做就是在烧钱。
拐点公式:
拐点条件: N_concurrent × KV_per_token × S_avg ≥ 0.5 × W_model
当所有并发请求的 KV Cache 总量达到模型权重的 50% 时,KV Cache 优化从"可选"变成"必选"。
以 70B GQA 模型为例,权重 70 GB(FP8),KV/token 320 KB(FP16)。0.5 × 70 GB / 320 KB ≈ 109K token。也就是说,所有并发请求的 token 总和超过 109K 时,过拐点。如果平均上下文 8K,约 14 个并发就过了。如果平均上下文 32K,约 4 个并发就过了。
不同模型和上下文的具体拐点:
| 模型 | 架构 | 权重(FP8) | KV/token | 拐点(并发, 32K上下文) | 拐点(并发, 128K上下文) |
|---|---|---|---|---|---|
| Llama-3 70B | GQA | 70 GB | 320 KB | 4 | 1 |
| DeepSeek V3 671B | MLA | 671 GB | 68.6 KB | ~1,600 | ~400 |
| DeepSeek V4-Pro 1.6T | 混合压缩 | ~800 GB | ~10 KB | 远高于实际并发 | 远高于实际并发 |
| GLM-5.2 (估) | GQA | ~170 GB | ~328 KB | 3 | 1 |
这张表透露几个信息。GQA 架构在任何实际服务场景下都在拐点之上——只要有人用,优化就值得。MLA 架构大幅推迟了拐点,中并发才开始受益。V4 混合压缩几乎不可能碰到拐点(KV 太小),除非并发极高。
按集群规模选择优化层级:
| 集群规模 | 必做 | 推荐 | 可选 |
|---|---|---|---|
| 1-4 卡 | PagedAttention | FP8 KV | — |
| 8-32 卡 | + Prefix Cache | + Continuous Batching | INT4 探索 |
| 64-256 卡 | + 以上全部 | + Prefill-Decode 分离 | 跨节点 KV 池化 |
| 1000+ 卡 | + 以上全部 | + KV 池化 + 弹性调度 | MTP / 定制 kernel |
按上下文长度判断 KV Cache 重要性:
| 上下文 | KV/权重比 (GQA) | KV Cache 角色 | 优化投入 |
|---|---|---|---|
| < 8K | < 5% | 可忽略 | 默认开 PagedAttention |
| 8-32K | 5-30% | 有感 | FP8 + Prefix Cache |
| 32-128K | 30-100% | 重要 | 全套引擎优化 |
| 128K-512K | 100-500% | 核心成本 | + 分离架构 + 存储 |
| 1M | 500%+ | 生存条件 | 必须用架构压缩模型 |
自建 vs API 拐点:
千卡 B300 × V4-Pro 集群月运营成本约 $1.17M。DeepSeek V4-Pro API 输出价格 $0.87/M tokens。盈亏平衡点:$1.17M / $0.87 ≈ 1.34B output tokens/月,即日均约 45M output tokens。按平均 10K output/请求,约 4,500 请求/天。
日均请求超过 5,000 条(含超长上下文),自建千卡集群经济可行。低于 1,500 条,用 API 更划算。中间地带看利用率——集群闲置 1 小时烧 ~$1,600,没有稳定需求就别建。
真正的瓶颈已经不在显存
对于 V4-Pro + B300 组合,千卡集群的瓶颈从显存转移到了别处:
| 维度 | 状态 | 说明 |
|---|---|---|
| KV Cache 显存 | ✅ 充裕 | 1M 请求只占 ~5 GB,110 GB 预算绰绰有余 |
| MoE(Mixture of Experts,混合专家架构)all-to-all 通信 | ⚠️ 真瓶颈 | 49B 激活参数的 expert routing 需要 NVLink 级带宽 |
| Prefill 计算 | ⚠️ 瓶颈 | 1M token prefill 是 compute-bound,需要 dense FP4 算力 |
| Decode 延迟 | ✅ 良好 | V4 的稀疏注意力使 decode 接近 O(1) |
推理优化的投资方向应该从"省 KV Cache"转向"加速 expert routing 和长上下文 prefill"。
回到开篇的矛盾:320 GB 的 KV Cache 需求,80 GB 的 HBM,差出来的去哪了?
五层优化给出了答案。架构压缩 320 GB → 9.62 GB(33×)。精度编码 9.62 → 4.8 GB(35×)。推理引擎把显存利用率从 30% 拉到 90%+。集群架构让 KV Cache 在节点间流动,消除冗余。存储设备层用成本只有 HBM 1/100 的 AI SSD 承接溢出的冷数据,DPU 预取让有效延迟逼近 DRAM。多轮场景叠加 Prefix Caching 后,均摊到每个请求的有效 KV 占用低于 1 GB。
优化重心从推理系统层转移到模型架构层。GQA 时代,推理工程师在 vLLM 里调参数;V4 混合压缩时代,压缩发生在模型设计阶段,推理工程师的工作变成理解注意力架构并设计匹配的部署拓扑。新的瓶颈是 MoE 通信、prefill 算力、DPU 预取命中率——下一轮推理优化的主战场。
风险仍在。G3.5 的有效性依赖 DPU 预取 pipeline 的成熟度。调度算法不够好,SSD 有效延迟退回物理水平,推理性能显著下降。CMX、CXL、开源方案三条标准化路线竞争未定。
但这些不确定性改变不了一件事:大模型上下文窗口从 8K 走到 1M,推理从单轮问答走到 Agent 长程记忆,KV Cache 体量增长是结构性的。HBM 产能增长不是。这个剪刀差,是整条优化链存在的根本理由。
本文基于公开信息撰写,综合参考了 NVIDIA 官方发布(CES 2026、GTC 2026、ICMSP 2026)、CFMS|MemoryS 2026 行业峰会、铠侠/英韧/大普微产品发布、vLLM 技术博客、DeepSeek 技术讨论及 arXiv 论文。不构成投资建议。文中数据截至 2026 年 6 月 15 日。