韬定律 V2:从理论框架到生产级验证
2026 年 5 月 25 日,何庭波在 ISCAS 2026 上发表韬(τ)定律的概念框架。39 天后,论文 V2 出现在 ChinaXiv 上--被《中国科学杂志》录用,23 页,32 篇参考文献,两个生产级验证案例。如果说 V1 是"换一个维度看半导体演进"的理论宣言,V2 回答的是更硬的问题:这条路线在工程上跑通了吗?能跑多远?
一、V2 新增了什么
V1 的核心论点--以"时间缩微"替代"几何缩微"--并不复杂。难的是证明它不只是换了一种叙事。V2 的增量几乎全部在"证据"层面:
移动端验证:麒麟 2026 的 LogicFolding(逻辑折叠)实测数据从演讲中的几个数字,扩展为完整的芯片级对比表,包括功耗、面积、频率、SRAM、时钟树各项指标,以及一张从 2023 到 2029 年的 CPU 主频路线图。
AI 系统验证:这是 V1 完全没有的部分。V2 第一次公开了华为 AI 系统的"三层 τ 缩减架构"--Unified Bus(灵衢)、Hi-ONE 近封装光学引擎、3D Folding--三个组件放在同一个理论框架里,用 N2-vs-N 几何论证串联。
方法论升级:论文 Section 8 写道--"τ scaling is the first scaling principle since Dennard to give the entire stack a shared optimization target"。这句话在 V1 演讲中没有,是 V2 新增的。它的含义不是学术占位,而是对产业链的信号:过去四十年工艺工程师和系统架构师各自优化自己的指标(频率、带宽、延迟、面积),τ scaling 给了他们同一个度量衡。1974 年 Dennard 缩放理论建立了"电压和尺寸等比缩小可维持恒定电场"的原则,让器件物理学家和电路设计师有了共同语言。此后五十年,没有人再给出过覆盖器件到系统的统一标尺。τ scaling 试图填补这个空白。
二、麒麟 2026:LogicFolding 的完整成绩单
核心对比
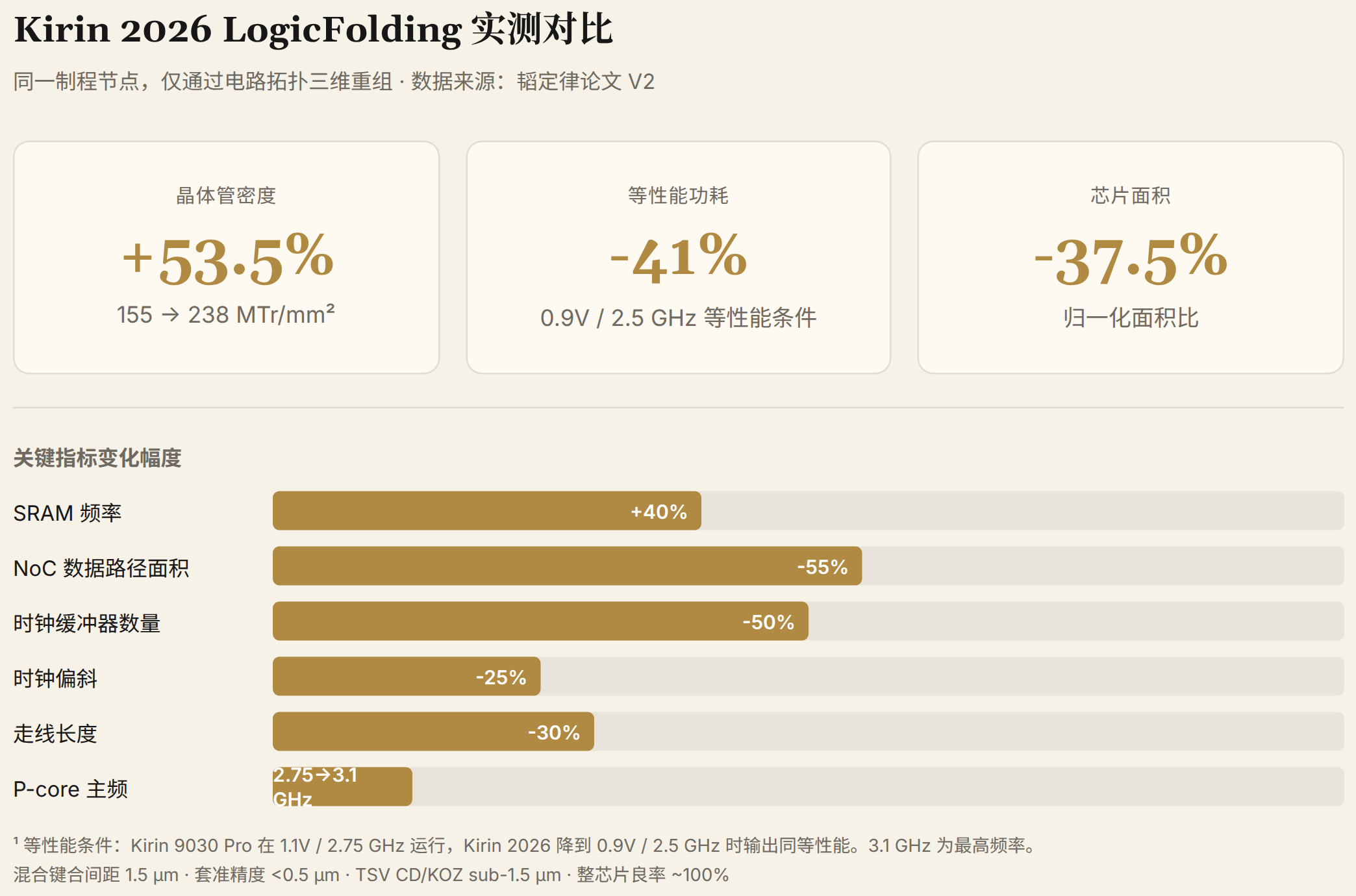
V1 给出的关键数字是晶体管密度和功耗改善。V2 把完整对比表铺开了:
| 指标 | Kirin 9030 Pro(平面) | Kirin 2026(LogicFolding) | 变化 |
|---|---|---|---|
| 晶体管密度 | 155 MTr/mm2 | 238 MTr/mm2 | +53.5%(论文标称 55%) |
| 等性能功耗1 | 1.0 | 0.59 | -41% |
| 芯片面积 | 1.0 | 0.625 | -37.5% |
| SoC P-core 主频 | 2.75 GHz | 3.1 GHz | +13% |
| SRAM 频率 | 基准 | +40% 以上 | - |
| 高速全局 NoC 数据路径面积 | 基准 | -55% | - |
| 时钟缓冲器数量 | 基准 | -50% | - |
| 时钟偏斜 | 基准 | -25% | - |
| 走线长度(代表核心) | 基准 | -30% | - |
1 等性能条件:Kirin 9030 Pro 在 1.1V / 2.75 GHz 下运行,Kirin 2026 降到 0.9V / 2.5 GHz 时输出同等性能,实测功耗降至 0.59 倍。3.1 GHz 是 Kirin 2026 的最高频率,不在此等性能条件下。
这些数字的共同指向是:在同一制程节点上,仅通过电路拓扑的三维重组,拿到了过去需要约三年几何微缩才能实现的密度跃升。
论文还披露了两项容易被忽略但工程意义重大的实测结果:高速全局 Network-on-Chip 数据路径利用上下两层有源层构建,面积缩减 55%,同时改善了电源 delivery 稳定性;以及一项硅后时钟偏斜调整方案,独立贡献了 >5% 的 SoC 性能。前者说明 LogicFolding 不只是"把逻辑折起来",而是为片上互联拓扑提供了新的设计自由度;后者说明在物理实现层面,传统的"签核后不可改"的边界正在被模糊化。
关键工艺参数
论文披露了 LogicFolding 的核心工艺指标:
- 混合键合间距:1.5 μm(2026 年量产版)
- 目标间距比(gear ratio):≈1
- 套准精度:<0.5 μm
- TSV CD/KOZ:sub-1.5 μm,间距 sub-6 μm
- TSV 故障率:<100 ppm,修复率 99.9%
- 整芯片良率:~100%(含智能冗余)
Gear ratio:从离散到连续的设计范式跃迁
论文中一个理论意义最深远、但容易被当作工艺参数略过的概念,是 gear ratio(间距比)。
Gear ratio 定义为混合键合间距与顶层金属布线间距之比。当混合键合间距远大于顶层金属间距时(gear ratio >> 1),设计师只能在功能块级别做粗粒度分配--把整个模块分配到上层或下层,因为层间互联太稀疏,不支持更细的粒度。这是一个离散优化问题,计算上可行但远离全局最优。
当混合键合间距缩小到接近顶层金属间距时(gear ratio → 1),两层有源层从电路设计师的视角变成了"一片连续的织物"--逻辑单元可以像在同一层金属上一样跨晶圆边界分布。设计空间从离散变为连续,打开全局协同优化的大门。
Kirin 2026 的 gear ratio 约 2(1.5 μm 键合 / ~720 nm 顶层金属),已经足以支撑关键路径级别的折叠。论文指出未来 TSV 从顶层金属下探到 M6,将释放 30% 以上的高层布线资源,gear ratio 进一步趋近 1。这不只是工艺参数的改善--它改变的是芯片设计的数学性质。
论文还指出,顺序 3D 集成(Sequential 3D,在同一晶圆上逐层加工晶体管)理论上能提供器件级或标准单元级的极致粒度,但目前面临严重的制造瓶颈--特别是下层器件在高温预算下的性能退化。LogicFolding 选择晶圆对晶圆混合键合作为 commercially viable 的中间路线,在粒度和可制造性之间取平衡。
1.5 μm 键合间距已进入量产(台积电 SoIC 当前量产约 6 μm,目标 2029 年 4.5 μm)。论文披露的这个数字印证了此前外界的推论:国产混合键合设备的实际进度,可能领先于公开认知。
Kirin CPU P-core 主频路线图
论文 Table 2 给出了一张从 2023 到 2029 年的完整路线图:
| 年份 | 芯片 | 架构 | P-core 频率 | 状态 |
|---|---|---|---|---|
| 2023 | Kirin 9000s | 平面 | 2.6 GHz | 量产 |
| 2024 | Kirin 9020 | 平面 | 2.65 GHz | 量产 |
| 2025 | Kirin 9030 Pro | 平面 | 2.75 GHz | 量产 |
| 2026 | Kirin 2026 | LogicFolding | 3.1 GHz | Silicon(流片成功) |
| 2027 | Kirin 2027 | LogicFolding | 3.39 GHz | Silicon |
| 2028 | Kirin 2028 | LogicFolding | 3.71 GHz | Pre-silicon |
| 2029 | Kirin 2029 | LogicFolding | 4 GHz | Pre-silicon |
2023→2025 三年平面架构只提了 0.15 GHz。切到 LogicFolding 后,2026 一年提了 0.35 GHz,后续保持每年 ~0.3 GHz 的提升斜率。论文投影到 2035 年晶体管密度达到 400+ MTr/mm2。
论文特别强调:2026 年量产版是"保守实现"--LogicFolding 仅选择性应用于关键路径,混合键合间距 1.5 μm,TSV 只下探到顶层金属下一层。未来向三层、四层有源层演进,配合更低温度的键合工艺和 TSV 下探到 M6,设计空间还有大幅释放余地。
三、AI 数据中心:三层 τ 缩减架构
V2 最重磅的新增内容是 Section 5。论文把韬定律从手机芯片扩展到 AI 数据中心--不是简单的场景延伸,而是把华为已有的灵衢总线、Hi-ONE 光互连、3D 堆叠三个独立技术放在 τ scaling 的统一框架里重新解释。
论文给出了两个支撑性事实:AI 系统中超过 80% 的能耗消耗在数据移动上,超过 70% 的系统成本分配给数据存储。这两组数据意味着——降低数据在传输中花费的时间,至少与降低计算时间同等重要。
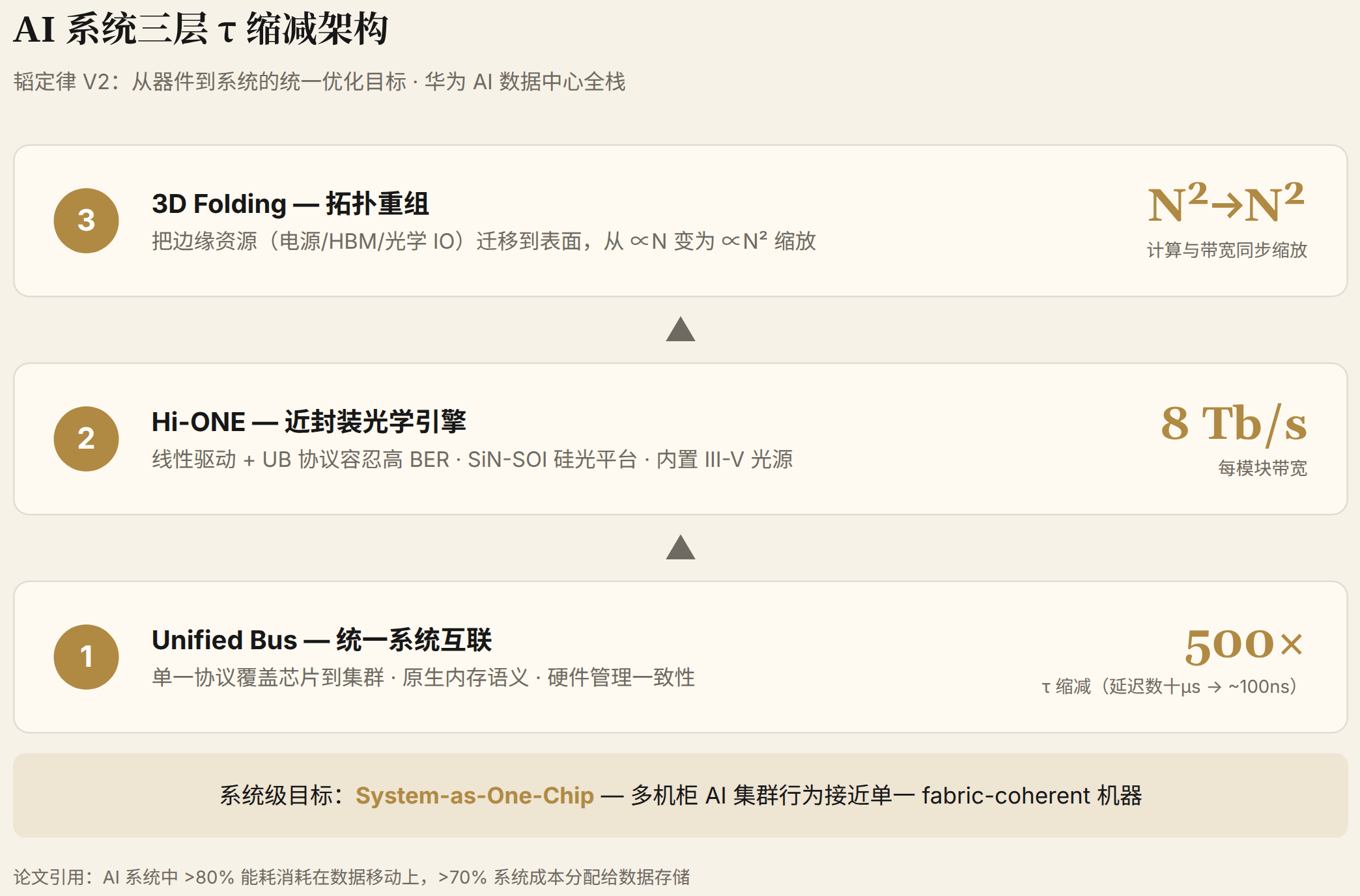
第一层:Unified Bus - τ-first 系统互联
传统多节点 AI 架构的数据通路是一叠协议转换:PCIe 连主机 → NVLink/私有互联连机柜内 → Ethernet/InfiniBand 连机柜间 → 软件栈做远程内存访问。每层转换增加延迟、降低可靠性、增加成本。
Unified Bus 的做法是用单一协议覆盖机柜内和跨机柜--点对点、原生内存语义、硬件管理一致性。数据移动被简化为内存语义层的无转换直接传输。
实测结果:端到端远程访问延迟从 TCP/IP 协议栈的数十微秒降到约 100 ns--τ 缩减约 500 倍。这个数字让多机柜 AI 集群在行为上接近"一台 fabric-coherent 的单一机器"(华为内部称之为 System-as-One-Chip)。
与 InfiniBand 的 SHARP 做一个对比:SHARP 在交换机硬件层做 reduction 运算,把集合通信延迟降低 50-80%。UB 的思路不同--它不优化某一层协议的效率,而是消除协议栈层数本身。从系统架构视角,这是从"让协议栈各层更高效"转向"不需要那么多层"。
第二层:Hi-ONE - 近封装光学引擎(首次公开)
当通信延迟被 UB 压到 100 ns 量级,下一个瓶颈转移到物理传输--SerDes 速率到 400 Gb/s 时铜缆尚可,到多 Tb/s 时铜在物理上不再可行:SerDes 触达收缩极限、线缆体积膨胀到不可接受、面板安装不可行、热和供电余量耗尽。
Hi-ONE(High-density Optical-interconnect-Node Engine) 是海思光电推出的近封装光学引擎技术平台。V2 论文中的描述让它看起来是新产物,但实际上 Hi-ONE 有更长的公开历史:
Hi-ONE 产品族与演进时间线
| 时间 | 事件 | 关键披露 |
|---|---|---|
| 2025.09 | IFOC 2025 讯石光通信大会 | 海思光电 CMO 熊前进首次发布 Hi-ONE 平台,宣布 7.2T SiPh NPO 光引擎 |
| 2026.01 | SPC 超节点大会 | 7.2T 光引擎已完成通道级性能验证和阶段性可靠性测试,支持 224G NPO 方案 |
| 2026.05.28 | "xPO 赋能"论坛 | 详细拆解:VCSEL 3.2T(32×112G)+ SiPh 7.2T(36×224G)双版本 |
| 2026.05.29 | 光通信论坛 | 熊前进确认星云光互联已在智算超节点组网中规模化应用 |
| 2026.07.03 | τ scaling 论文 V2 | 模块带宽从 7.2T 升级为 8T,放入 τ scaling 全栈框架 |
Hi-ONE 在同一平台下覆盖两款 NPO 光引擎:
| 版本 | 带宽 | 通道配置 | 技术 | 用途 |
|---|---|---|---|---|
| VCSEL NPO | 3.2T | 32×112G | VCSEL 阵列 + ORFIC 电芯片 | 短距(sub-100m) |
| SiPh NPO | 7.2T→8T | 36×224G | SiN-SOI + III-V 大功率 CW 激光器 | 中长距(超百米) |
关键技术特征(综合 C114 报道与论文 V2):
- 内置共享集成光源:海思光电自研 III-V 族耐高温 CW 激光器,支持全温高功率输出,无需外部激光源
- SiN-SOI 硅光平台:单片高密集成有源与无源器件,兼具高集成度与低功耗
- 线性驱动方案:不用重型 DSP,改用模拟均衡增强驱动器 + TIA,配合 UB 协议容忍更高误码率。800G SR8 LPO 版本将传输时延锐减 90% 以上
- StarSensor 星云智检:分钟级链路脏污/虚接检测,厘米级故障定位精度--现网数据表明大模型训练故障多来自光链路,这项功能直指痛点
- 全场景适配:可插拔/板载/共封装均可,多协议支持(SR/DR/FR)
从论文 V2 视角看 Hi-ONE 的定位
这个跨层折中有深意。传统光模块设计追求物理层最低误码率,用 DSP 做重度信号补偿。Hi-ONE 在协议层面主动放松 BER 要求,换取物理层的功耗和复杂度下降,这是 τ scaling 方法论在"协议层 × 物理层"跨层优化的具体体现。Hi-ONE 不是一个独立的光学器件,而是 UB 系统的一个有机组件。
但行业信息揭示了另一个面向:Hi-ONE 在 2025 年 9 月就已作为独立的 NPO 光引擎产品发布,且在 2026 年 5 月确认"已在智算超节点组网中规模化应用"。这意味着论文 V2 中 8T 的数字,可能不是论文里的理论投影,而是已进入实际部署的产品规格的最新迭代。论文把一个已有产品重新放入 τ scaling 框架,赋予了它新的理论定位--从"海思光电的 NPO 产品"升级为"τ scaling 架构中的光学层"。
与华工科技的 3.2T NPO 光引擎、立讯的 NPO 产品矩阵相比,Hi-ONE 的差异化在于:它是唯一明确声明与系统互联协议(UB)协同设计的光学引擎,而不是适配既有协议的独立模块。在 ODCC 2026 夏季全会上,华为同时拆解了 1024-lane NPO 的工程挑战--Hi-ONE 与那些讨论是同一条路线的两个侧面。
第三层:3D Folding - 解决 N2-vs-N 困境
V2 提出了一个简洁的几何论证,解释为什么 2.5D 封装必然遇到天花板。这个论证不依赖任何工艺参数,纯粹是拓扑约束--因此比"光刻太贵"或"物理极限"这类经验性论断更有说服力。
N2-vs-N 困境。在 2.5D AI 芯片中,假设芯片边长为 N:
- 计算能力 ∝ N2(面积)
- 带宽 / 互联 / 电源 ∝ N(周长--HBM 堆栈和 SerDes 排在芯片边缘)
面积增长比周长快。芯片越大,"喂不饱"计算单元的带宽缺口越宽。这不是 transistor-level 改善能闭合的--它是一个拓扑约束。
这个论证的力量在于它的普适性:无论晶体管多快、HBM 多密,只要带宽资源排在芯片边缘(2.5D fan-out),就逃不出 N2-vs-N 的剪刀差。
3D Folding 的解法:把边缘资源迁移到表面。电源通过背面供电(BSPDN)从底部进入,HBM 通过混合键合叠在逻辑层上方,光学 I/O 通过近封装 Hi-ONE 放在封装表面。一旦这些资源从"边缘"迁移到"表面",它们的缩放规律从 ∝ N 变为 ∝ N2--与计算能力同步增长。封装不再是"逻辑芯片周围一圈内存和 SerDes",而是"一个垂直集成的栈,内存、互联、电源、逻辑全部以 N2 缩放"。
Ascend 路线图
论文把 AI 加速器的演进放在 τ scaling 时间线上(芯片代号和年份来自 V2 论文;灵衢版本和算力规格来自华为 2025 年全联接大会公开信息):
- Ascend 910C(2025):Atlas 900 超节点,384 卡,灵衢 1.0
- Ascend 950(2026 Q4):Atlas 950 超节点,8192 卡,灵衢 2.0,FP8 8 EFLOPS
- Ascend 990(~2030):首次在 AI 加速器中引入 LogicFolding,3D Folding 成为主流
- 2030→2035:硬件集成度增长 >100 倍
关键信号:LogicFolding 在 2026 年先落地移动端验证,~2030 年才进入 AI 加速器。AI 芯片的散热条件比手机宽松,但芯片面积大得多,热密度管理复杂度也更高。这个时间差说明华为对 LogicFolding 的扩展节奏是谨慎的--先在功耗受限的场景验证,再向更大规模的计算芯片推广。
四、逻辑与存储的再融合
V2 Section 6 提出了一个容易被忽略但影响深远的判断:逻辑与存储正在从"刻意解耦"走向"再融合"。
8086 时代,行业刻意通过标准化内存总线把处理器和存储解耦--两个产业各自独立缩放,形成了庞大的存储市场。处理器按摩尔定律快速迭代,存储按自己的节奏(DDR 代际 → HBM)发展,两者通过标准化接口松耦合。
AI 时代正在逆转这个趋势。HBM、混合键合、3D 堆叠 SRAM 都是同一趋势的症状:数据移动的成本已经追上甚至超过了计算本身。论文引用的数据--大型 AI 集群中 >80% 能量消耗在数据移动上,>70% 系统成本分配给数据存储--量化了这个结构性转变。
论文判断:供应链话语权正在从逻辑厂商向存储和封装厂商转移。这个判断的落点不在某一家公司,而在产业结构的变迁--当"数据在哪里"比"算在哪里"更决定系统效率时,控制数据移动路径的环节(存储、互联、封装)的战略权重自然上升。
这对供应链投资逻辑有直接影响。如果逻辑-存储的物理融合是不可逆的结构趋势,那么 HBM、先进封装、混合键合设备的战略权重将持续上升--这不是周期性波动,而是半导体价值链的结构性重排。
五、诚实的开放挑战
论文 Section 7 列出五个开放挑战。这一节的价值不在于列出了问题--任何路线图都有"风险因素"--而在于措辞的直接性。论文没有回避 τ scaling 的结构性局限。
EDA 工具链断层
现有 EDA 为 2D 设计--面积、时序、功耗沿三条独立轴优化,系统 τ 作为副产品浮现。全尺度 LogicFolding 要求工具链把多层堆叠的有源层当作单一连续设计实体处理,在 cell 级粒度做跨层布局和时序闭环。跨层路径上的垂直互联寄生参数、TSV 排除区(KOZ)、晶圆间工艺变异的交互方式,是传统 2D 训练的工具不覆盖的。
论文承认"初步内部工具已有可用结果",方法论细节将在未来几个月发表。但更关键的信号是论文的呼吁:"a τ-native toolchain - open, multi-physics, and 3D-native - is the single most important enabling investment for the next decade."(τ-native 工具链--开放、多物理场、3D 原生--是下一个十年最重要的基础投资。)这不是产品宣传,而是向整个 EDA 行业发出的信号。
晶圆间工艺变异
LogicFolding 键合的晶圆可能来自不同批次甚至不同节点。晶圆间的 Vth(阈值电压)、驱动电流、互连 RC 变异显著大于晶圆内变异,冲击最大的是时钟分布和 hold-time margin。智能冗余、自适应补偿、τ-aware 签核流程是必要的应对手段--但这些都是工程层面的持续投入,不是一次性解决的理论问题。
垂直互联开销
每个混合键合点和 TSV 都有有限的电阻和电容代价。LogicFolding 必须逐层证明一个简单不等式:键合后 τ(缩短的走线延迟)> 键合开销 τ(垂直互联引入的 RC)。论文指出移动端关键路径和存储已过了这个阈值,但不同工作负载的阈值不同,边界会随键合间距缩小而移动。
能耗:时间定律的局限
这可能是最核心的约束。论文直言:"τ is a time law, not a joule law."(τ 是时间定律,不是焦耳定律。)一个超节点如果 10 倍快但 10 倍耗能,不违反任何缩放原理,但超出电网容量。
τ scaling 因此需要一个能源配套方案(energy companion):内存语义互联消除协议栈开销、近封装/共封装光学降低 pJ/bit、背面供电减少 IR drop 损耗、存内/近存计算缩短数据搬运距离、以及在数据中心尺度做 DVFS(把 τ 余量转化为功耗节降--与手机用 DVFS 延长电池寿命的原理相同,只是尺度放大到吉瓦级)。论文特别指出:τ headroom 本身在被分配到节能方向时,就提供了能源余量。这是一个正反馈--τ 优化创造的余量可以反哺能源约束。
基准测试
现有基准(Linpack、MLPerf、SPEC)为"单一标量"时代设计。τ scaling 产业需要 τ-profile 基准--向量化的指标,暴露每一层的 dominant τ 和剩余余量。论文的判断简短但精确:dominant τ 所在的层,就是下一个投资方向。
六、应用加速因子
论文首次给出了不同应用领域的 τ 缩减速率分类:
| 应用 | 年缩放因子 α | 逻辑 |
|---|---|---|
| 移动设备 | ~1.3 | 功耗和散热约束 |
| 自动驾驶 | ~1.5 | 安全关键实时性 |
| AI Token 生成 | 最高 ~10 | 吞吐量直接等于经济价值 |
τ 的代际规则是 τ_{n+1} = τ_n / α。α 越大,每代 τ 缩减越多。移动端的 α ≈ 1.3 意味着每年约 23% 的 τ 缩减;AI 的 α 最高到 10 意味着某些维度上一年可以缩减 90%。
这个分类解释了为什么华为优先把 AI 系统层面的 τ 缩减投入做重--灵衢、Hi-ONE、超节点--而不是在其他场景上分散。AI Token 吞吐的年缩放速率是移动端的近 8 倍,每一层 τ 缩减的边际回报都远高于其他应用。这组数字也回答了一个外部观察者常问的问题:"华为为什么不把 LogicFolding 先用在 AI 芯片上?"答案藏在 α 的差异里--AI 系统的 τ 缩减窗口大得多,不依赖 LogicFolding 单一技术,灵衢 UB 和 Hi-ONE 的系统级收益已经足够显著。LogicFolding 进入 AI 加速器要等到 ~2030 年,因为那时 UB 和 Hi-ONE 的边际 τ 收益开始递减,需要器件层面的新一轮折叠来接力。
七、六年沉淀,十年前瞻
论文 Section 8 给出了韬定律的阶段性总结。2020 年 5 月到 2026 年 5 月,华为半导体设计并量产了 381 颗芯片,覆盖移动、AI、汽车、工业和基础设施市场。论文用三个层级的实测结果支撑 τ scaling 的有效性:
- 器件和电路层:晶体管密度从 155 向 400+ MTr/mm2 推进
- 芯片层:LogicFolding 在固定工艺节点上验证了关键路径频率、能效、密度的持续提升
- 系统层:UB 和 Hi-ONE 验证了数百微秒级通信 τ 可压缩到数百纳秒,多机柜 AI 集群可表现为单一 coherent 机器
381 颗芯片这个数字本身就是一种论证方式。韬定律不是论文里的理论模型--它是六年里 381 颗量产芯片反复验证的方法论。从统计角度看,如果 τ scaling 只在少数产品上有效,可以归结为个案;381 颗芯片覆盖多个行业,说明方法论的可复制性已经过了工业级检验。
八、判断
对半导体演进框架的意义
摩尔定律建立的是一个"单变量缩放"框架--晶体管更小 → 一切更好。这个框架的简洁性是它统治行业六十年的原因。但它也有代价:器件、电路、芯片、系统四层各自独立优化,系统级 τ 作为没人负责的"残差"浮现。
Dennard 缩放曾在器件和电路之间建立了桥梁--"等比缩小可维持恒定电场"让器件物理学家和电路设计师有了共同语言。Dennard 在 2005 年左右失效后,这座桥断了。τ scaling 试图建一座更大的桥--不是连接相邻两层,而是覆盖器件到系统的全跨度。它能否成功,取决于未来五到十年里有多少产业参与者真的采用 τ 作为跨层协作的度量衡。
对竞争格局的实际影响
对华为自身:论文把 Ascend 路线图放到了 2035 年--990 引入 LogicFolding、100× 硬件集成度提升。灵衢 UB 的 ~100 ns 延迟和 Hi-ONE 的 8 Tb/s 模块带宽,为评估华为超节点的实际性能提供了硬数据。
对半导体设备产业:1.5 μm 混合键合间距已进入量产芯片。国产键合设备(北方华创 Qomola HPD30、拓荆 W2W 量产型号)的验证进度值得持续跟踪--论文的披露间接确认了这条产线的成熟度。
对存储产业:逻辑-存储再融合的判断如果成立,HBM 和先进封装的战略权重将持续上升。这不只是存储厂商的利好--它意味着存储和封装不再是"配合逻辑芯片的配角",而正在成为系统性能的决定因素。
对出口管制的长期含义:论文明确说"competitive performance no longer requires perpetual residence on the leading edge of lithography"。如果这个判断在 5-10 年内被产业实践证实--即不依赖最先进光刻也能持续提升系统性能--那么以限制先进制程获取为核心的出口管制策略,其有效性会被系统性削弱。
九、业界最前沿对比:追赶、创新与路线分歧
韬定律不是在真空中诞生的。全球半导体行业都在向 3D 和系统级优化转型,但各家的路径选择有本质差异。这一节把华为的进度放在全球坐标系里,逐项对比。
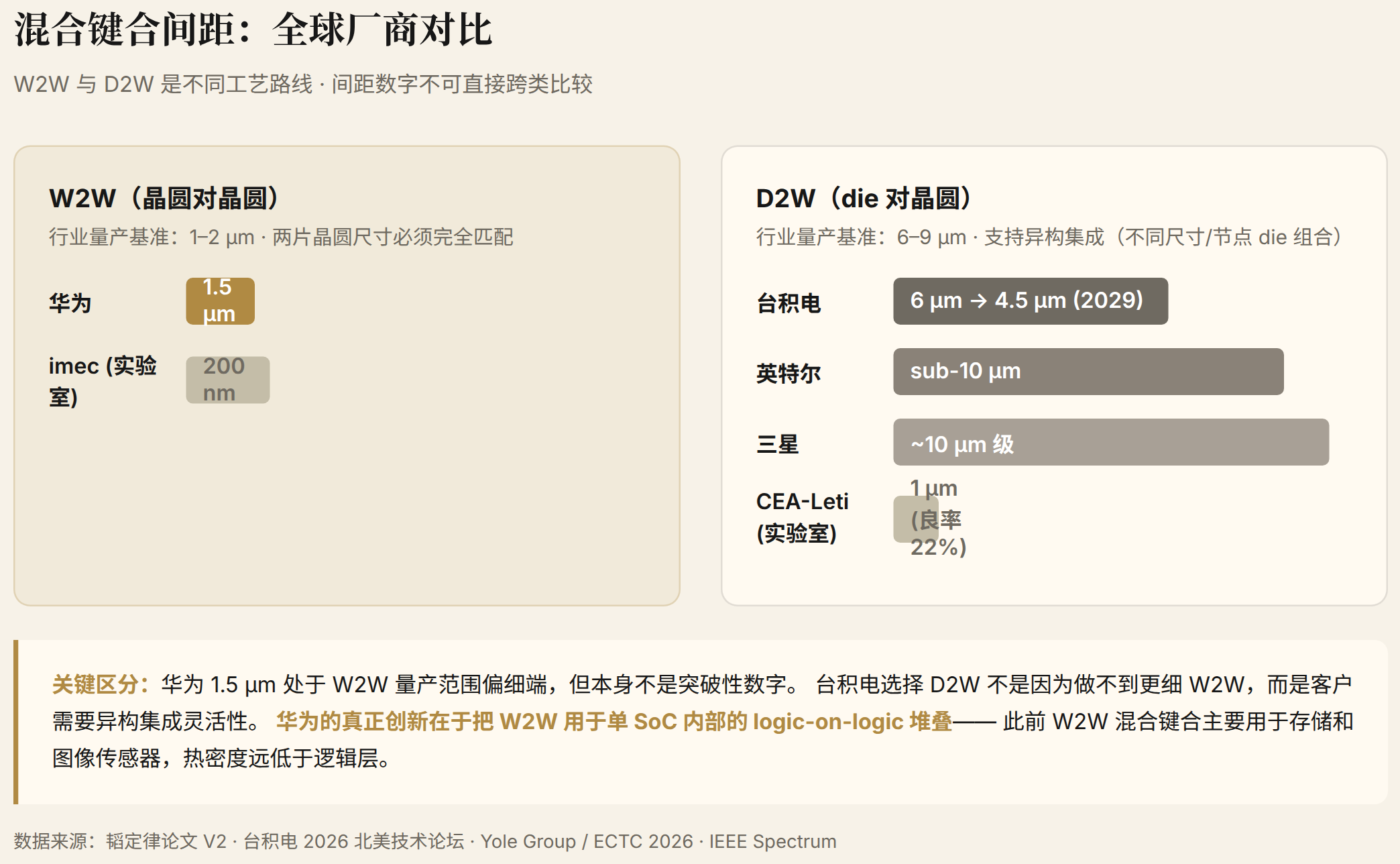
混合键合间距:华为已经领先,但方式不同
混合键合间距是 3D 集成最硬的指标。当前全球进度:
| 厂商 | 技术 | 键合方式 | 当前量产间距 | 路线图目标 |
|---|---|---|---|---|
| 华为 | LogicFolding | W2W | 1.5 μm | 向 sub-1 μm / gear ratio ≈1 演进 |
| 台积电 | SoIC-X | D2W | ~6 μm | 4.5 μm (2029) |
| 英特尔 | Foveros Direct | D2W | sub-10 μm | 未见明确 sub-5 μm 路线图 |
| 三星 | I-Cube4 / X-Cube | D2W | ~10 μm 级 | 跟随策略 |
这个表需要一个关键注释:W2W 和 D2W 是不同的工艺路线,间距数字不能直接跨类比较。 根据 Yole Group 分析师在 ECTC 2026 的分类,当前行业量产基准是:W2W 1-2 μm,D2W 6-9 μm。W2W 天然能达到更细间距--整片晶圆对准精度远高于逐 die 放置。华为 1.5 μm 处于 W2W 量产范围内的偏细端,但这本身不是突破性数字。
台积电选择 D2W 不是因为做不到更细 W2W,而是客户产品需要异构集成--不同尺寸、不同节点的 die 灵活组合,D2W 支持这种灵活性而 W2W 要求两片晶圆尺寸完全匹配。
华为的真正创新点不在间距数字,而在于把 W2W 用于单 SoC 内部的 logic-on-logic 堆叠。 W2W 混合键合此前主要用于存储堆叠(HBM)和图像传感器--这些场景的热密度远低于逻辑层。华为把 W2W 用在同一颗 SoC 的有源逻辑层之间,并同时解决热管理、时钟分布和 cell 级关键路径折叠的设计方法论问题。这才是论文 V2 中真正没有先例的工作。
实验室层面,imec 在 ECTC 2026 上展示了 200 nm W2W 间距(非量产),CEA-Leti 展示了 1 μm D2W 间距(良率仅 22%,非量产)。量产与实验室之间的差距依然显著。
背面供电:华为尚未进入,业界已量产
背面供电网络(BSPDN)把供电线路从晶圆正面移到背面,让正面空间完全用于信号布线。这是 2nm 及以下节点的必备技术。
| 厂商 | 技术 | 状态 |
|---|---|---|
| 英特尔 | PowerVia | 18A 已量产(2025) |
| 台积电 | Super Power Rail (A16) | 2026 年底量产,复杂度高于 Intel |
| 三星 | BSPDN (SF2Z) | 2027 年量产 |
| 华为 | - | 论文未提及 |
论文在描述 3D Folding 时提到 backside power,但作为未来架构方向,而非已有成果。在麒麟 2026 的 LogicFolding 实现中,论文没有提及背面供电。
这意味着在器件层的 τ 缩减工具箱中,华为还缺少一个重要武器。英特尔 18A + PowerVia 实测在同等工作电压下频率提升 25%,或功耗降低 36%。如果华为未来在 LogicFolding 叠加 BSPDN,理论上还有一层额外的频率/功耗改善空间--但何时能获得这个能力,取决于国产先进制程的背面供电工艺成熟度。
系统级互联:两种哲学的分野
在 AI 数据中心的系统级互联上,华为和 NVIDIA 代表了两种截然不同的哲学。
NVIDIA 的路线:持续扩展 NVLink 域(NVL72 → NVL144 → NVL576 → NVL1152),在 scale-up 场景逐步引入 CPO(Rubin Ultra NVL576 已用 CPO 做跨机柜光互联,Feynman NVL1152 将全面 CPO),协议栈分层清晰:NVLink(scale-up)+ InfiniBand/Ethernet(scale-out)。
华为的路线:Unified Bus 用单一协议覆盖从芯片到机柜到集群的全尺度,消除协议转换开销。UB 的 ~100 ns 远程访问延迟,在量级上接近 NVLink 机柜内延迟,但要覆盖远得多的物理距离。
分歧点:NVIDIA 的分层协议栈允许每一层独立优化(NVLink 追求极低延迟,Ethernet 追求高带宽和标准化经济性),代价是跨层转换开销。华为的 UB 用统一语义消除转换开销,代价是协议必须同时满足 scale-up 的极低延迟和 scale-out 的大规模扩展性。哪条路线最终更优,取决于 UB 在数千卡规模下能否维持 ~100 ns 量级的延迟--这目前是论文数据,尚需真实部署验证。
光学互联:CPO vs NPO 的路线竞赛
华为 Hi-ONE 和 NVIDIA Spectrum-X Photonics 代表了光学互联的两种工程路径:
| 维度 | NVIDIA Spectrum-X Photonics | 华为 Hi-ONE |
|---|---|---|
| 定位 | Scale-out CPO 以太网交换机 | Scale-up 近封装光学引擎 |
| 互连对象 | 交换机之间(spine-leaf) | 芯片之间(UB fabric 内) |
| 带宽 | 400 Tb/s 交换容量 | 8 Tb/s 每模块 |
| 信号处理 | 传统 DSP(可编程) | 线性驱动(模拟均衡) |
| 协议层 | 以太网 + RoCEv2 | UB 原生内存语义 |
| 量产状态 | 已宣布 in production(5/31) | 论文未给出量产时间 |
NVIDIA 的 CPO 用于 scale-out 网络--让以太网交换机突破电信号面板密度限制。华为的 Hi-ONE 用于 scale-up fabric--让 UB 协议的物理传输从铜线迁移到光。两者不是直接竞争,而是各自在系统不同层级解决光学互联问题。
更深层的差异是信号处理哲学。NVIDIA 选择传统可编程 DSP,成熟方案但功耗较高。华为选择线性驱动,功耗更低但信号保真度依赖 UB 协议的容错设计。这是 τ scaling 方法论的具体体现--为了总系统 τ 最优,在物理层放松 BER 要求换取功耗下降。但也意味着 Hi-ONE 不能独立使用,必须与 UB 协议栈协同设计。
Sequential 3D:真正的天花板在哪
LogicFolding 用 W2W 混合键合实现了两层有源逻辑层的堆叠,间距 1.5 μm。但论文自己承认,Sequential 3D(S3D)--在同一晶圆上顺序加工多层晶体管--理论上是更优解。
S3D 的优势:层间互联密度比 W2W 混合键合高 3-4 个数量级(光刻级精度 vs 键合精度);不需要两片晶圆;理论上不受键合间距限制。
S3D 的瓶颈:下层器件在高温预算下的性能退化--上层晶体管加工温度必须低于 ~600°C;imec/Leti 的 CoolCube 方案在实验室验证了 logic-on-logic 堆叠,但距离量产仍有显著距离;全球范围内 S3D 量产时间表在 2030 年之后。
论文的判断:LogicFolding 的 W2W 混合键合是 commercially viable 的中间路线。一旦 S3D 工艺成熟,设计方法论(关键路径折叠、gear ratio 优化)可以平滑迁移。
LogicFolding 的理论天花板不取决于键合间距,而取决于热管理。两层有源逻辑层的功耗密度远高于存储堆叠--imec 的模拟显示 4 层 HBM-on-GPU 在不做极端优化时温度可达 142°C。逻辑层堆叠到 3-4 层时热密度问题会更严重。论文对此的回应是 thermal-aware partitioning,但没有给出具体方案。

天花板总结:
- 短期(2026-2028):两层有源层,关键路径选择性折叠。密度 +55%,功耗 -41%
- 中期(2029-2031):三层以上有源层,TSV 下探 M6,gear ratio →1。密度 400+ MTr/mm2
- 长期(2032-2035+):如果 S3D 突破热预算瓶颈,层数不再受限于键合;如果未突破,停留在 3-4 层 W2W
技术路线分歧:三个待回答的问题
问题一:系统级优化能否永久替代先进制程?
韬定律的核心论点是 competitive performance no longer requires leading-edge lithography。但这个论点有一个前提:系统级 τ 缩减的边际收益不递减。如果 UB 延迟压到 100 ns 后进一步压缩变困难,或 Hi-ONE 带宽密度遇到物理极限,系统级优化需要器件层面的新一轮突破来接力。论文把 Ascend 990(~2030)引入 LogicFolding 的时间点安排在 UB/Hi-ONE 边际收益开始递减的时刻--这不是巧合。
问题二:EDA 生态谁能先跑通?
LogicFolding 需要 3D-native、多物理场、cell 级粒度的 EDA 工具链。论文承认华为只有初步内部工具。全球范围内,Synopsys / Cadence 在 2D EDA 统治地位稳固,3D IC 工具仍在早期;台积电的 3DFabric Alliance 在构建自己的 3D 设计生态;北大团队发布了真 3D EDA 原型。谁先拥有成熟的 τ-native 3D EDA 工具链,谁就能加速 LogicFolding 类技术的设计闭环。这是华为路线上的最大不确定性。
问题三:热管理是最终的物理天花板吗?
两层有源逻辑层的热密度已接近手机散热极限。AI 加速器散热条件更宽松(液冷、更大芯片面积),但 LogicFolding 进入 AI 芯片并堆叠到 3-4 层时,功耗密度可能超过 100 W/cm2。论文给出的方案是 thermal-aware partitioning 和 avoid folding high-power circuits--但这意味着 LogicFolding 不是全域应用,而是热约束下的选择性应用。这个约束是否会在 4-8 层堆叠时变成不可逾越的物理墙,目前没有答案。
需要持续跟踪的验证点
- Kirin 2026 量产版实测:论文标注为 Silicon(流片成功),2026 年秋季上市后的实际散热、良率、日常使用功耗是第一轮外部验证
- Ascend 950 超节点实际部署:2026 Q4 上市后的训练性能、推理吞吐、稳定性数据--尤其是 UB 远程访问延迟在真实工作负载下是否达到论文宣称的 ~100 ns
- Hi-ONE 量产时间:论文未给出 Hi-ONE 的具体量产时间表--这是一个需要跟踪的缺口
- EDA 工具链开放进展:论文呼吁开放协作,但具体合作模式和开放范围尚未明确
信源说明:本文基于何庭波论文《A Time Scaling Theory for Multi-Layer Electronic Systems》V2 版(ChinaXiv:202605.00224v2,2026-07-03,已被《中国科学杂志》录用)。Kirin 2026 实测数据、gear ratio 理论、Hi-ONE 规格参数、N2-vs-N 几何论证、Ascend 路线图为论文 V2 首次披露。Ascend 算力规格和灵衢版本来自华为 2025 年全联接大会公开信息。Hi-ONE 产品细节来自海思光电在 IFOC 2025(2025-09)、SPC 超节点大会(2026-01)及"xPO 赋能"论坛(2026-05)的公开演讲,经 C114 通信网报道。业界对比数据来自台积电 2026 北美技术论坛、Intel Foveros Direct 技术简报、IEEE Spectrum / ECTC 2026 报道、TrendForce 及 Tom's Hardware。不构成投资建议。文中数据截至 2026 年 7 月 3 日。