信源说明:ODCC 夏季全系内部会议(ODCC 明确"拒绝非成员单位人员进入"),完整的议程、PPT、讨论纪要不对外公开。本文基于以下可获取的公开信源撰写:(1)华为官方发布(搜狐 2026-06-27)——全体会议+新技术与测试工作组+网络工作组;(2)正泰官方发布(中华网 2026-06-29)——数据中心设施工作组;(3)超聚变官方发布(腾讯新闻 2026-06-25)——液冷焦点组;(4)格兰富官方发布(冷暖商情 2026-07-01)——设施工作组;(5)UALink 联盟主席 Kurtis 现场实录(公众号「积跬步-集大成」2026-07-02)——UALink Track 开幕演讲;(6)XSKY 发布(网易 2026-06-29)——存储焦点组 KV Cache 评测。
2026 年 6 月 24-26 日,景德镇。开放数据中心委员会(ODCC)夏季全会在这里举办。六大工作组、百余位产业链专家、三天密集研讨,核心议题只有一个——AI 正在重写数据中心的基础设施规则。
一、一个简单的算术题
2018 年,一个标准数据中心机柜的功率密度是 5-8 kW。2024 年,NVIDIA GB200 NVL72 机柜的功率密度达到 120 kW。2026 年,行业已经在讨论单柜 200 kW 甚至更高的场景。
八年时间,功率密度翻了 15-25 倍。
这意味着什么?传统数据中心建设的每一个假设——供电方式、散热方案、网络架构、机柜形态、运维模式——全部需要重写。不是微调,是重写。
ODCC 2026 夏季全会传递出的最强烈信号就是这个:AI 数据中心基础设施正在经历一次代际跃迁,而不是渐进式优化。 这次跃迁涉及六个技术方向,它们彼此耦合、相互牵引,正在同时发生。

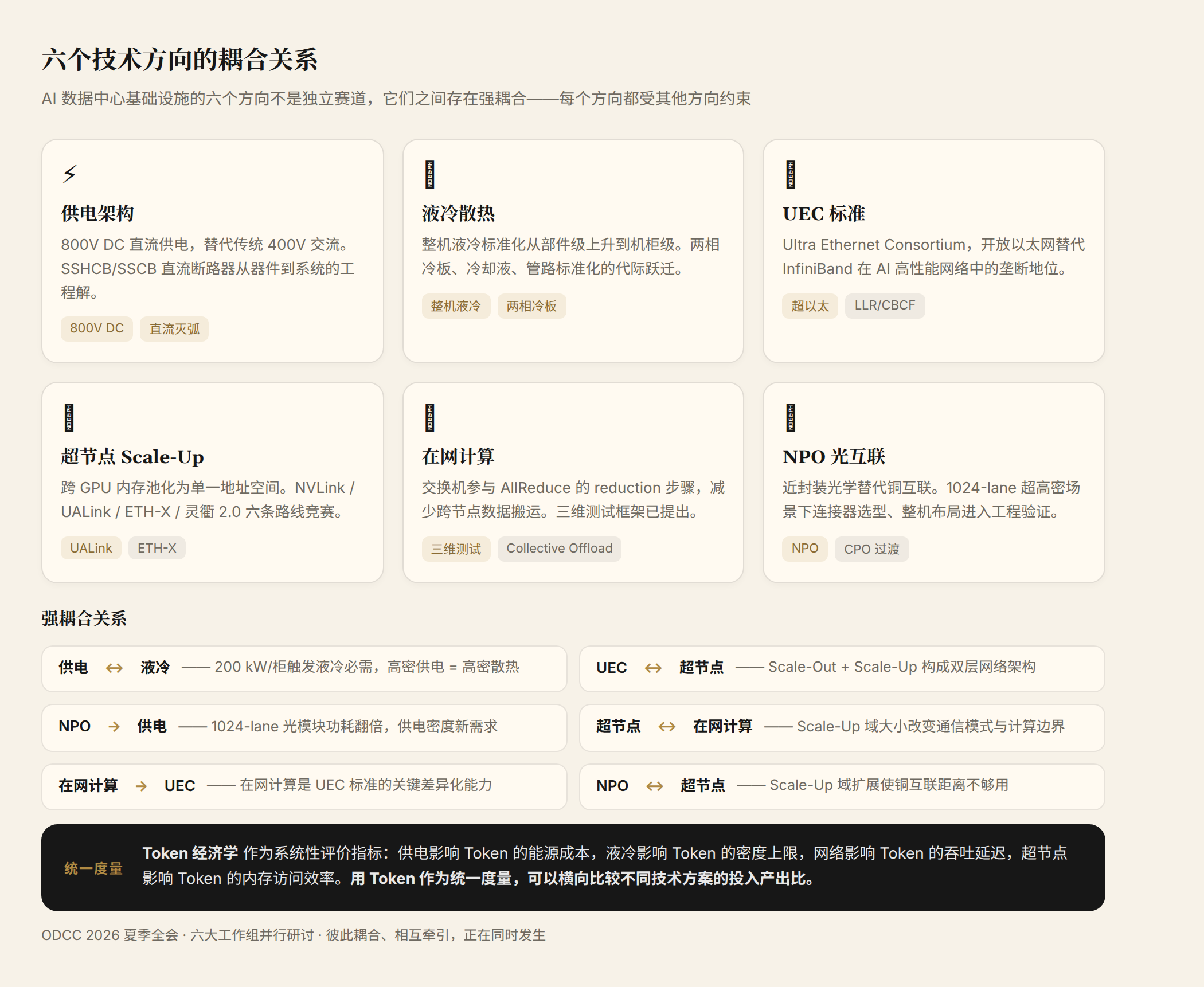
二、六个方向,一个问题
物理基础设施:从交流到直流,从风冷到液冷
第一个方向是供电和散热——数据中心的"水电煤"。
供电方面,传统 400V 交流配电的天花板已经到了。当单柜功率超过 100 kW,交流系统的线缆截面积、断路器分断能力、谐波干扰都变成工程噩梦。ODCC 设施工作组明确把 800V 直流供电作为未来主流方向,这不是技术偏好,是物理约束倒逼的结果。
正泰在会上展示了三级直流断路器矩阵:从传统直流专用断路器(DCCB),到混合式固态断路器 SSHCB(100μs–10ms 响应),再到全固态断路器 SSCB(1μs–50μs 响应)。直流灭弧——这个困扰行业多年的难题——终于有了从器件到系统的工程解。
散热方面,当单芯片功耗突破 1000 W,风冷的热传导效率已经不够用。超聚变以液冷产业推进组组长单位身份提出"整机液冷标准"概念——液冷标准化从冷板、管路、冷却液的部件级,上升到机柜级和设施级。这是一个标准体系的跃迁。
OCP 和 ODCC 的 ±400V HVDC sidecar 标准已经定稿。Meta、Microsoft、Google、字节、腾讯的下一代液冷机柜规格里都写入了 HVDC 母线。供电和散热正在同时换代。
网络架构:从"够快"到"够用"
剩下五个方向都与网络有关,但它们的核心矛盾不是"带宽不够大",而是"网络评价标准变了"。
第二个方向,UEC(Ultra Ethernet Consortium)标准的落地。华为 CloudEngine XH9000 在本次全会上通过 ODCC"算力强基行动"测评,获得泰尔实验室颁发的国内首个对标 UEC 标准的以太交换机测评证书。但这不是 UEC 联盟官方的合规认证(UEC 的正式认证程序仍在建设中),而是 ODCC 基于《交换机设备 LLR&CBCF 功能对接测试规范》执行的验证。InfiniBand 在 AI 高性能网络领域的垄断地位,正在面临来自开放以太网生态的第一个系统性挑战。中国厂商的适配速度,决定了国内智算网络的建网成本和供应链安全。
第三个方向,超节点(Scale-Up)。AI 大模型的参数规模已经超出单 GPU 的内存容量,必须把多张 GPU 的内存池化成单一地址空间。本次夏季全会上,UALink 联盟拥有独立专场(UALink Track),董事会主席 Kurtis 亲临景德镇做开幕致辞。他透露:2026 年 4 月 UALink 发布了四个新规范(Common 2.0 / 200G DL/PL 2.0 / Chiplet 1.0 / Manageability 1.0),从单一链路规范扩展为完整的部署框架。更重要的是,UALink 与 ODCC 正在中国本地合作提供互操作性测试服务——这标志着开放 Scale-Up 标准从"纸面规范"进入"工程验证"阶段。与此同时,华为灵衢 2.0 已大规模商用部署(Atlas 900 累计 300+ 套),腾讯 ETH-X 推进全光互联演进,六条 Scale-Up 协议路线的产业化竞赛进入加速期。
第四个方向,在网计算。传统网络设备只负责搬数据,计算发生在端点(CPU/GPU)。在网计算让交换机参与到 collective 操作(如 AllReduce 的 reduction 步骤)中来,减少数据搬运量。华为在本次全会上提出了覆盖功能、性能、可靠性的三维测试框架——这个领域此前缺乏标准化测试体系。当 Agent 多智能体场景爆发,集合通信的模式会变得更加复杂,在网计算的价值会被重新评估。
第五个方向,Token 经济学重塑网络设计。这是一个新视角:如果 Token 成为算力的基础计量单位(国家数据局已给出定义:可计量、可定价、可交易),那么网络架构的评价标准要从"带宽/延迟"转向"Token 吞吐效率/Token 传输成本"。华为在新技术与测试工作组上首次以 Token 经济学视角分析数据中心网络的底层演进逻辑。这不是营销概念——中国日均 Token 调用量已经突破 140 万亿,两年增长 1000 倍。当 Token 流量成为数据中心的主要流量类型,网络必须围绕 Token 效率重新设计。
第六个方向,NPO(近封装光学)的工程落地。AI 集群的 Scale-Up 域正在从百卡级扩展到千卡级,铜互联的物理距离限制(7 米以内)变成硬约束。NPO 把光引擎放在交换芯片封装附近,在性能、成本和工程风险之间取得平衡,被视为从铜互联到 CPO(共封装光学)的关键过渡。华为在本次全会上详细拆解了 1024-lane 超高密场景下 NPO 交换机的工程挑战——连接器选型、物理尺寸设计、整机布局——说明 NPO 已进入真实的工程验证阶段。
三、耦合关系:为什么这六个方向必须一起看
这六个方向不是独立的技术赛道,它们之间存在强耦合:
供电 ↔ 散热:800V DC 直接触发液冷需求——高密供电带来高密热量,传统风冷的 COP(性能系数)在 200 kW/柜面前完全失效。反过来,液冷系统本身的泵和冷却液循环也需要更精确的电力管理。
网络 ↔ 供电:NPO 和 CPO 的光模块功耗远高于铜缆,1024-lane NPO 交换机的供电需求可能翻倍。超节点架构下的全光互联方案,对供电密度提出了新要求。
超节点 ↔ 在网计算:Scale-Up 域的扩大改变了通信模式——域内通信走内存语义协议(NVLink/ETH-X/UALink),域间通信走以太网。在网计算的价值边界随 Scale-Up 域的大小而变化。
Token 经济学 ↔ 所有方向:Token 效率是一个系统性指标。供电影响 Token 的能源成本,散热影响 Token 的密度上限,网络影响 Token 的吞吐延迟,超节点影响 Token 的内存访问效率。用 Token 作为统一度量,可以横向比较不同技术方案的投入产出比。
UEC ↔ 超节点:UEC 定义的是 Scale-Out(跨机柜、跨集群)网络的开放标准,超节点定义的是 Scale-Up(机柜内)网络的技术路线。两者构成 AI 集群的双层网络架构,标准需要协同设计。
四、中国位置
这次全会让我注意到一个结构性变化:中国不再只是标准的跟随者,在若干方向上正在成为标准制定者。
ODCC 的决策层——腾讯、阿里、百度、中国移动、中国电信、中国信通院、美团、京东——代表着全球最大的 AI 算力消费群体。当这些用户联合制定标准,供应链必须跟上。几个具体信号:
- ODCC 与 UALink 联盟签署 MOU,超节点互联协议有了跨组织协同
- 华为拿到首个对标 UEC 标准的以太交换机测评证书,中国交换机厂商的超以太适配进入实质阶段
- 正泰、超聚变分别在供电和液冷标准制定中担任组长单位
- 中国信通院郭亮(ODCC 新测组组长)主导的《AI 计算节点发展研究报告》已体系化覆盖超节点全链路
但也要看到差距:UEC 核心规范由 AMD、Intel、Meta、Microsoft 等主导,中国厂商在标准制定的话语权上仍弱于在产品制造上的能力。UALink 同样由西方企业主导规范——但在 ODCC 夏季全会上,UALink 联盟董事会主席 Kurtis 明确把中国定位为"关键重心"(one of the big centers of revenue),并确认 UALink 与 ODCC 正在中国本地合作提供互操作测试服务。这是一个实质性的生态合作信号。

五、本系列文章要回答的问题
接下来的六篇深度分析,每篇聚焦一个方向,各自独立但相互呼应:
- AI 数据中心物理基础设施代际跃迁:800V DC + 整机液冷如何重构供配电与散热全链条
- UEC 标准落地——中国厂商的超以太适配竞赛:Ultra Ethernet 从规范到产品的关键路径
- 超节点 Scale-Up 方向技术跟踪:ETH-X / UALink / NVLink 三条路线的工程进展
- 在网计算标准化测试框架:交换机参与计算的技术原理、标准化缺口和 Agent 时代的新需求
- Token 经济学如何重塑网络设计原则:从带宽延迟到 Token 效率的评价范式转变
- NPO 从概念到 1024-lane 工程实施:光互联在 Scale-Up 域的技术经济性分析
每篇文章都遵循同一框架:技术原理 → 工程约束 → 产业进展 → 风险与边界。
六、一个判断
如果把这次 ODCC 夏季全会放在更长的技术周期里看,它标志着一个转折点:AI 数据中心的基础设施创新重心,正在从芯片层(GPU/加速器)下移到设施层(供电/散热/网络),同时从单点优化转向系统级标准化。
过去两年的故事是"谁的 GPU 最强",接下来两年的故事可能是"谁的机房更高效"。芯片性能的提升正在逼近物理极限,但数据中心的系统效率——从电网到芯片的端到端能量转化效率——还有巨大的优化空间。
谁能在 800V DC 供电、整机液冷、超节点互联、光互联这些方向上率先跑通标准化的工程闭环,谁就掌握了 AI 基础设施的下一代定义权。
这不是一个关于"哪项技术更好"的问题,而是一个关于"谁能率先把好技术变成可复制标准"的问题。
声明: 本文基于 2026 ODCC 夏季全会(6月24-26日,景德镇)公开信息撰写,综合参考了 ODCC 官网新闻、参会企业(华为、正泰、超聚变、格兰富等)发布的技术解读,以及中国信通院相关研究报告。不构成投资建议。文中数据截至 2026 年 7 月 2 日。